


por Sergey L. Gladkiy (Federación Rusa)
En este artículo, discutiremos los pros y los contras de los enfoques DNN existentes y seleccionaremos un modelo previamente entrenado para una mayor experimentación.
Aquí seleccionaremos (para seguir trabajando) dos modelos de SSD, uno basado en MobileNet y otro basado en SqueezeNet:
En el artículo introductorio de esta serie, discutimos una forma simple de crear un detector de personas DL para dispositivos de borde, que consistía en encontrar un modelo DNN apropiado y escribir el código para lanzarlo en un dispositivo. En este artículo, discutiremos los pros y los contras de los enfoques DNN existentes y seleccionaremos un modelo previamente entrenado para una mayor experimentación.
Hemos mencionado tres técnicas DL modernas para la detección de objetos en imágenes: Faster-RCNN, Single-Shot Detector (SSD) y You Only Look Once (YOLO). Cada una de estas técnicas tiene ventajas e inconvenientes que debemos tener en cuenta para poder seleccionar la que mejor se adapte a nuestro propósito específico.
Faster-RCNN utiliza una red neuronal convolucional junto con el bloque Region-Proposal y capas completamente conectadas (FC). CNN es el primer bloque de la red; su trabajo es extraer características de la imagen. El siguiente bloque – Red de propuesta de región – es responsable de sugerir Regiones de interés (ROI) para posibles ubicaciones de objetos. El bloque final, las capas FC, está diseñado para la regresión del cuadro delimitador (BB) y la clasificación de objetos para cada uno de los cuadros. Aquí hay un esquema simple del algoritmo Faster-RCNN:
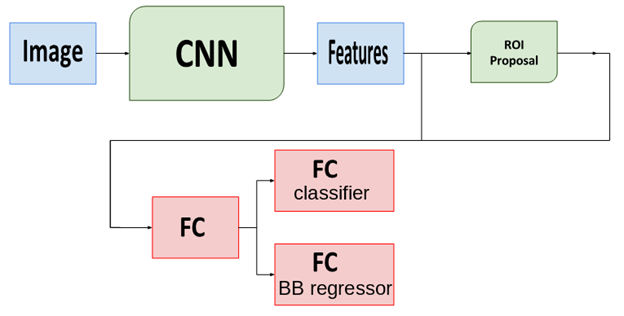
El método SSD es similar a Faster-RCNN. Después del extractor de funciones de CNN, contiene un detector Multi-Box, que permite la detección de cuadros delimitadores y la clasificación de objetos en una sola pasada hacia adelante. Por eso se considera que es más rápido que Faster-RCNN.
La técnica YOLO se basa en el marco Darknet. En lugar de escanear una imagen en las diferentes ubicaciones y escalas, divide la imagen completa en una cuadrícula de celdas y analiza cada celda, puntuando la probabilidad de que cada celda pertenezca a una determinada clase. Esto hace que el algoritmo YOLO sea muy rápido.
La sola consideración de la velocidad haría de YOLO la elección obvia. Pero hay una cosa más a considerar antes de tomar la decisión: la precisión del algoritmo. El concepto de precisión para la detección de objetos es más complejo que el de la clasificación de objetos. Aquí, debemos evaluar no solo el error de clasificación, sino también el error de la ubicación del cuadro delimitador del objeto.
La principal medida de precisión para la detección de objetos es Intersection over Union (IoU): la relación de intersección y unión de la verdad del terreno y los cuadros delimitadores detectados. Debido a que podemos tener muchas clases para ubicar y clasificar, la precisión promedio media (mAP) se usa para calcular la precisión de todo el conjunto de datos. El valor de mAP se evalúa comúnmente para IoU = 0.5 y se indica como “mAP@0.5”.
No profundizaremos demasiado en la teoría de las medidas de precisión de detección de objetos. Simplemente compararemos los tres métodos DL de la competencia en términos de mAP@0.5: cuanto mayor sea este valor, más preciso será el modelo.
Busque en Internet valores de precisión de los diversos modelos Faster-RCNN, SSD y YOLO, y encontrará muchos resultados drásticamente diferentes. Esto se debe a que existen muchos modelos de DNN previamente entrenados para cada método de detección. Por ejemplo, la tecnología SSD puede usar los diferentes modelos de CNN para la extracción de características, y cada uno de estos modelos se puede entrenar con los diferentes conjuntos de datos: ImageNet, COCO, VOC y otros.
Una comparación completa de las métricas de precisión de todos los modelos existentes no es nuestro objetivo. Nuestras pruebas de los tres métodos con el mismo conjunto de datos mostraron que la mejor precisión podría lograrse con el método Faster-RCNN, una precisión ligeramente menor, con los modelos SSD, y los resultados menos precisos, con la red YOLO.
Parece que cuanto más rápido es el método de detección de objetos, menos precisión proporciona. Por lo tanto, elegimos el medio feliz: los modelos SSD, que pueden proporcionar suficiente velocidad con suficiente precisión.
A continuación, buscamos un modelo SSD listo para usar que sería:
- Lo suficientemente pequeño para funcionar en Raspberry Pi con sus recursos informáticos limitados
- Capacitado para detectar humanos (el modelo también puede detectar otras clases de objetos, pero su precisión de detección humana es lo que importa para la aplicación que estamos creando)
Hemos encontrado dos modelos de SSD adecuados. El primero se basó en MobileNet CNN, y el segundo utilizó un SqueezeNet previamente entrenado como extractor de funciones. Ambos modelos han sido entrenados utilizando el conjunto de datos COCO y podrían detectar objetos de veinte clases diferentes, incluidos humanos, automóviles, perros y otros. Cada modelo tenía un tamaño de aproximadamente 20 MB, muy pequeño en comparación con el tamaño común de 200-500 MB para los modelos utilizados en procesadores de alto rendimiento. Así que estos dos parecían la elección correcta para nuestros propósitos.
Fuente: https://www.codeproject.com/Articles/5281993/Real-time-AI-Person-Detection-on-Edge-Devices-Sele