

El aprendizaje de “menos de uno” puede enseñar a un modelo a identificar más objetos que la cantidad de ejemplos en los que está entrenado.
por Karen Hao
El aprendizaje automático generalmente requiere toneladas de ejemplos. Para que un modelo de IA reconozca un caballo, debe mostrarle miles de imágenes de caballos. Esto es lo que hace que la tecnología sea computacionalmente costosa y muy diferente del aprendizaje humano. Un niño a menudo necesita ver solo algunos ejemplos de un objeto, o incluso solo uno, antes de poder reconocerlo de por vida.
De hecho, los niños a veces no necesitan ningún ejemplo para identificar algo. Se les muestran fotos de un caballo y un rinoceronte, y se les dice que un unicornio es algo intermedio, pueden reconocer a la criatura mítica en un libro de imágenes la primera vez que la ven.

Ahora, un nuevo artículo de la Universidad de Waterloo en Ontario sugiere que los modelos de IA también deberían poder hacer esto, un proceso que los investigadores denominan aprendizaje de “menos de un disparo” o LO-shot. En otras palabras, un modelo de IA debería ser capaz de reconocer con precisión más objetos que la cantidad de ejemplos en los que fue entrenado. Eso podría ser un gran problema para un campo que se ha vuelto cada vez más caro e inaccesible a medida que los conjuntos de datos utilizados se vuelven cada vez más grandes.
Cómo funciona el aprendizaje de “menos de uno”
Los investigadores primero demostraron esta idea mientras experimentaban con el popular conjunto de datos de visión por computadora conocido como MNIST . MNIST, que contiene 60.000 imágenes de entrenamiento de dígitos escritos a mano del 0 al 9, se utiliza a menudo para probar nuevas ideas en el campo.
En un artículo anterior, los investigadores del MIT habían introducido una técnica para “destilar” conjuntos de datos gigantes en pequeños y, como prueba de concepto, habían comprimido MNIST a sólo 10 imágenes. Las imágenes no se seleccionaron del conjunto de datos original, sino que se diseñaron y optimizaron cuidadosamente para contener una cantidad equivalente de información al conjunto completo. Como resultado, cuando se entrena exclusivamente en las 10 imágenes, un modelo de IA podría lograr casi la misma precisión que uno entrenado en todas las imágenes del MNIST.


Los investigadores de Waterloo querían llevar el proceso de destilación más allá. Si es posible reducir 60.000 imágenes a 10, ¿por qué no comprimirlas en cinco? Se dieron cuenta de que el truco consistía en crear imágenes que combinaran varios dígitos y luego introducirlos en un modelo de IA con etiquetas híbridas o “suaves”. (Piense en un caballo y un rinoceronte que tienen rasgos parciales de un unicornio).
“Si piensas en el dígito 3, también se parece al dígito 8 pero nada al dígito 7”, dice Ilia Sucholutsky, estudiante de doctorado en Waterloo y autora principal del artículo. “Las etiquetas blandas intentan capturar estas características compartidas. Entonces, en lugar de decirle a la máquina, ‘Esta imagen es el dígito 3’, decimos, ‘Esta imagen es 60% del dígito 3, 30% del dígito 8 y 10% del dígito 0’ ”.
Los límites del aprendizaje LO-shot
Una vez que los investigadores utilizaron con éxito etiquetas blandas para lograr el aprendizaje LO-shot en MNIST, comenzaron a preguntarse hasta dónde podría llegar realmente esta idea. ¿Existe un límite en la cantidad de categorías que puede enseñarle a un modelo de IA a identificar a partir de una pequeña cantidad de ejemplos?
Sorprendentemente, la respuesta parece ser no. Con etiquetas blandas cuidadosamente diseñadas, incluso dos ejemplos podrían codificar teóricamente cualquier número de categorías. “Con dos puntos, puede separar mil clases o 10,000 clases o un millón de clases”, dice Sucholutsky.
Esto es lo que demuestran los investigadores en su último artículo, a través de una exploración puramente matemática. Desarrollan el concepto con uno de los algoritmos de aprendizaje automático más simples, conocido como k vecinos más cercanos (kNN), que clasifica los objetos mediante un enfoque gráfico.
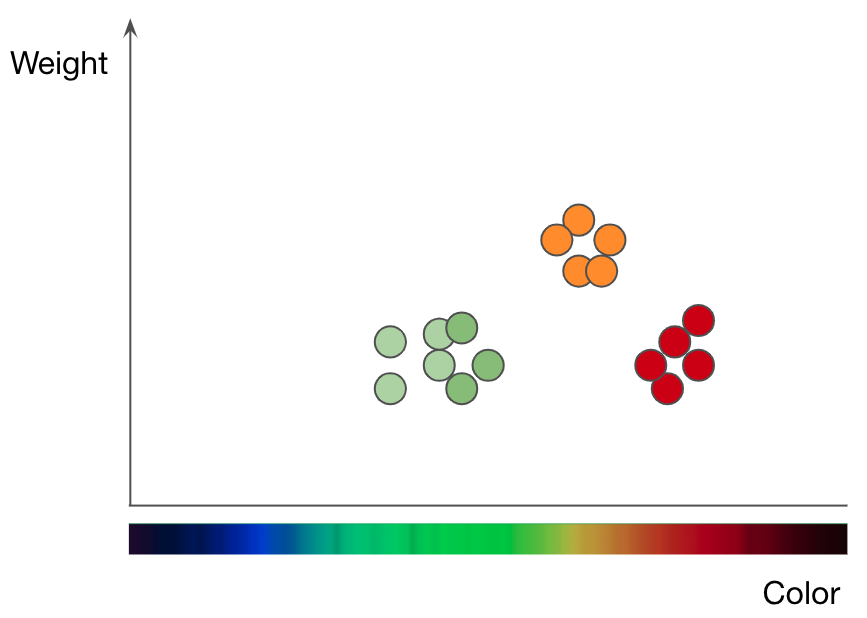
Para entender cómo funciona kNN, tome la tarea de clasificar frutas como ejemplo. Si desea entrenar un modelo kNN para comprender la diferencia entre manzanas y naranjas, primero debe seleccionar las características que desea utilizar para representar cada fruta. Quizás elijas el color y el peso, por lo que para cada manzana y naranja, alimentas al kNN con un punto de datos con el color de la fruta como su valor xy el peso como su valor y. El algoritmo kNN luego traza todos los puntos de datos en un gráfico 2D y dibuja una línea de límite en el centro entre las manzanas y las naranjas. En este punto, la gráfica se divide claramente en dos clases, y el algoritmo ahora puede decidir si los nuevos puntos de datos representan uno u otro en función de qué lado de la línea se encuentran.
Para explorar el aprendizaje LO-shot con el algoritmo kNN, los investigadores crearon una serie de pequeños conjuntos de datos sintéticos y diseñaron cuidadosamente sus etiquetas blandas. Luego dejaron que kNN trazara las líneas de límite que estaba viendo y descubrieron que dividió con éxito el gráfico en más clases que puntos de datos. Los investigadores también tenían un alto grado de control sobre dónde caían las líneas fronterizas. Usando varios ajustes en las etiquetas suaves, pudieron hacer que el algoritmo kNN dibujara patrones precisos en forma de flores.
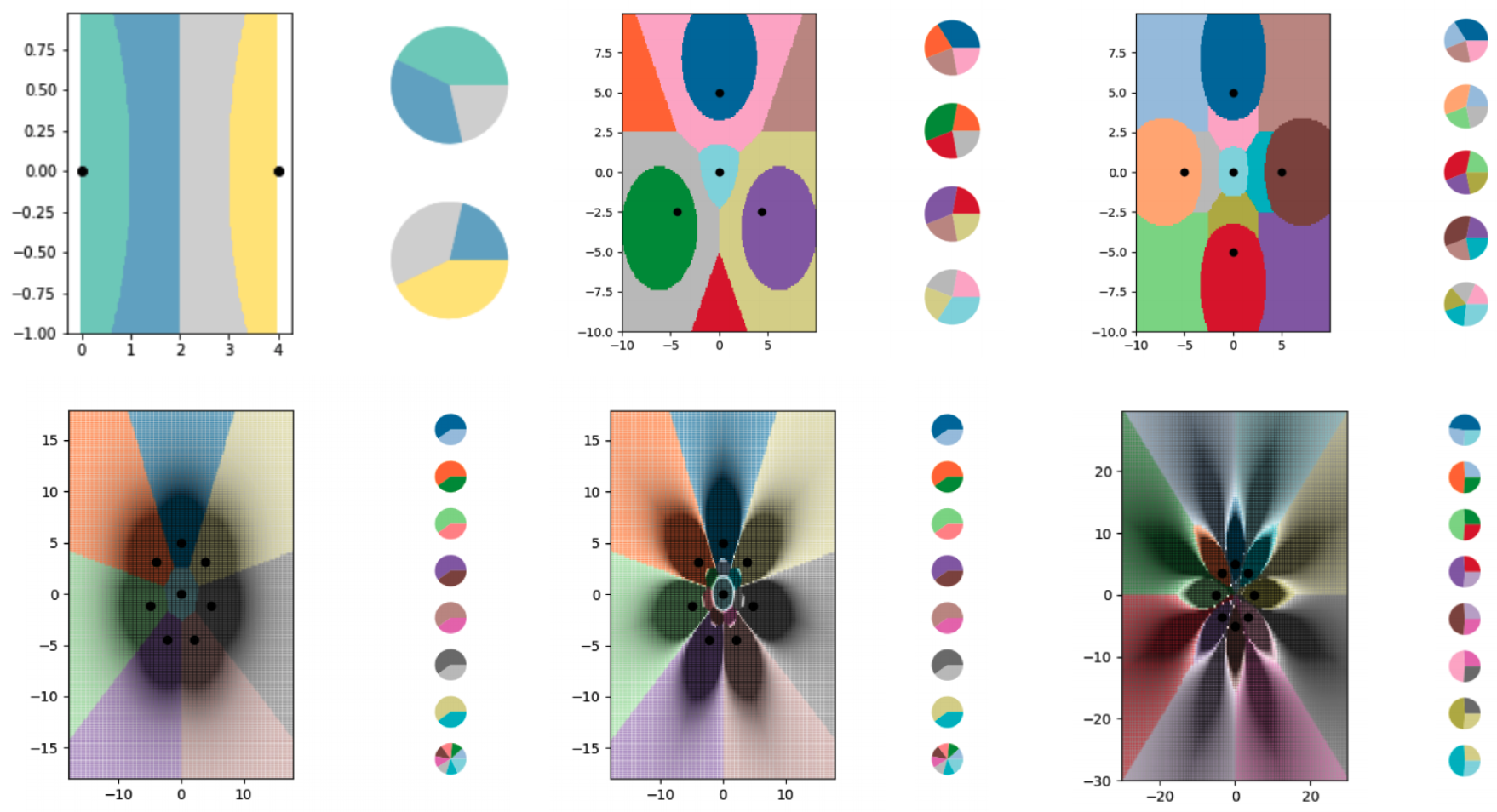
Por supuesto, estas exploraciones teóricas tienen algunos límites. Si bien la idea del aprendizaje LO-shot debería transferirse a algoritmos más complejos, la tarea de diseñar los ejemplos con etiquetas suaves se vuelve sustancialmente más difícil. El algoritmo kNN es interpretable y visual, lo que hace posible que los humanos diseñen las etiquetas; Las redes neuronales son complicadas e impenetrables, lo que significa que lo mismo puede no ser cierto. La destilación de datos, que funciona para diseñar ejemplos de etiquetas suaves para redes neuronales, también tiene una gran desventaja: requiere que comiences con un conjunto de datos gigante para reducirlo a algo más eficiente.
Sucholutsky dice que ahora está trabajando en descubrir otras formas de diseñar estos pequeños conjuntos de datos sintéticos, ya sea que eso signifique diseñarlos a mano o con otro algoritmo. Sin embargo, a pesar de estos desafíos de investigación adicionales, el documento proporciona las bases teóricas para el aprendizaje LO-shot. “La conclusión es que dependiendo del tipo de conjuntos de datos que tenga, probablemente pueda obtener ganancias masivas de eficiencia”, dice.
Esto es lo que más le interesa a Tongzhou Wang, un estudiante de doctorado del MIT que dirigió la investigación anterior sobre destilación de datos. “El documento se basa en un objetivo realmente novedoso e importante: aprender modelos poderosos a partir de pequeños conjuntos de datos”, dice sobre la contribución de Sucholutsky.
Ryan Khurana, investigador del Instituto de Ética de IA de Montreal, se hace eco de este sentimiento: “Lo más significativo es que el aprendizaje ‘menos de una vez’ reduciría radicalmente los requisitos de datos para construir un modelo funcional”. Esto podría hacer que la IA sea más accesible para las empresas y las industrias que hasta ahora se han visto obstaculizadas por los requisitos de datos del campo. También podría mejorar la privacidad de los datos, porque se tendría que extraer menos información de las personas para entrenar modelos útiles.
Sucholutsky enfatiza que la investigación aún es temprana, pero está emocionado. Cada vez que comienza a presentar su artículo a otros investigadores, su reacción inicial es decir que la idea es imposible, dice. Cuando de repente se dan cuenta de que no lo es, se abre un mundo completamente nuevo.
Fuente: https://www.technologyreview.com/2020/10/16/1010566/ai-machine-learning-with-tiny-data/