

por Karen Hao
Las poderosas redes neuronales pronto podrían entrenarse en teléfonos inteligentes con velocidades dramáticamente más rápidas y menos energía.

El aprendizaje profundo es un consumidor de energía ineficiente. Requiere grandes cantidades de datos y abundantes recursos computacionales, lo que explota su consumo de electricidad. En los últimos años, la tendencia general de la investigación ha empeorado el problema. Los modelos de proporciones gigantescas, entrenados en miles de millones de puntos de datos durante varios días, están de moda y probablemente no desaparecerán pronto.
Algunos investigadores se han apresurado a encontrar nuevas direcciones, como algoritmos que pueden entrenar en menos datos,o hardware que puede ejecutar esos algoritmos más rápido. Ahora los investigadores de IBM están proponiendo uno diferente. Su idea reduciría el número de bits, o 1s y 0s, necesarios para representar los datos, desde 16 bits, el estándar actual de la industria, a solo cuatro.
El trabajo,que se presenta esta semana en NeurIPS, la mayor conferencia anual de investigación sobre IA, podría aumentar la velocidad y reducir los costos de energía necesarios para entrenar el aprendizaje profundo en más de siete veces. También podría hacer posible el entrenamiento de potentes modelos de IA en teléfonos inteligentes y otros dispositivos pequeños, lo que mejoraría la privacidad al ayudar a mantener los datos personales en un dispositivo local. Y haría que el proceso fuera más accesible para los investigadores fuera de grandes empresas tecnológicas ricas en recursos.
Cómo funcionan los bits
Probablemente has oído antes que las computadoras almacenan cosas en 1s y 0s. Estas unidades fundamentales de información se conocen como bits. Cuando un bit está “encendido”, se corresponde con un 1; cuando está “apagado”, se convierte en un 0. Cada bit, en otras palabras, puede almacenar sólo dos piezas de información.
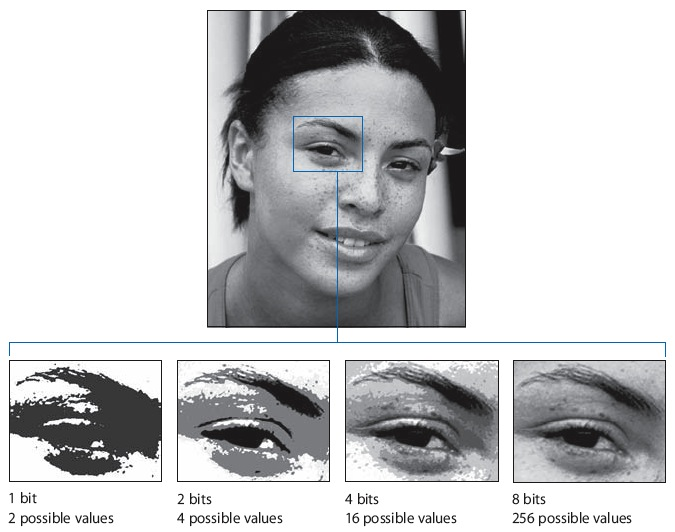
Pero una vez que los encadena, la cantidad de información que puede codificar crece exponencialmente. Dos bits pueden representar cuatro piezas de información porque hay combinaciones de 2 x 2: 00, 01, 10y 11. Cuatro bits pueden representar 2 x 4, o 16 piezas de información. Ocho bits pueden representar 2 x 8, o 256. Y así sucesivamente.
La combinación correcta de bits puede representar tipos de datos como números, letras y colores, o tipos de operaciones como suma, resta y comparación. La mayoría de los portátiles en estos días son computadoras de 32 o 64 bits. Eso no significa que el equipo solo pueda codificar 2 x 32 o 2 64 piezas de información total. (Eso sería un ordenador muy ingenioso.) Esto significa que puede utilizar tantos bits de complejidad para codificar cada dato o operación individual.
Aprendizaje profundo de 4 bits
Entonces, ¿qué significa entrenamiento de 4 bits? Bueno, para empezar, tenemos una computadora de 4 bits, y por lo tanto 4 bits de complejidad. Una manera de pensar en esto: cada número que usamos durante el proceso de entrenamiento tiene que ser uno de los 16 números enteros entre -8 y 7, porque estos son los únicos números que nuestro ordenador puede representar. Eso va para los puntos de datos que alimentamos en la red neuronal, los números que usamos para representar la red neuronal y los números intermedios que necesitamos almacenar durante el entrenamiento.
Entonces, ¿cómo hacemos esto? Primero pensemos en los datos de entrenamiento. Imagina que es un montón de imágenes en blanco y negro. Paso uno: necesitamos convertir esas imágenes en números, para que el ordenador pueda entenderlas. Hacemos esto representando cada píxel en términos de su valor de escala de grises: 0 para negro, 1 para blanco y los decimales entre los tonos de gris. Nuestra imagen es ahora una lista de números que van del 0 al 1. Pero en tierra de 4 bits, lo necesitamos para variar de -8 a 7. El truco aquí es escalar linealmente nuestra lista de números, por lo que 0 se convierte en -8 y 1 se convierte en 7, y los decimales se asignan a los enteros en el medio. así que:
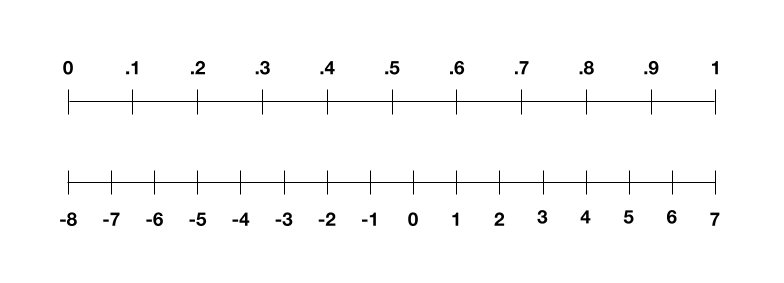
Este proceso no es perfecto. Si usted comenzó con el número 0.3, digamos, usted terminaría con el número escalado -3.5. Pero nuestros cuatro bits sólo pueden representar números enteros, por lo que tiene que redondear -3.5 a -4. Terminas perdiendo algunos de los tonos grises, o la llamada precisión,en tu imagen. Puedes ver cómo se ve en la imagen de abajo.
Este truco no está muy mal para los datos de entrenamiento. Pero cuando lo aplicamos de nuevo a la propia red neuronal, las cosas se complican un poco más.

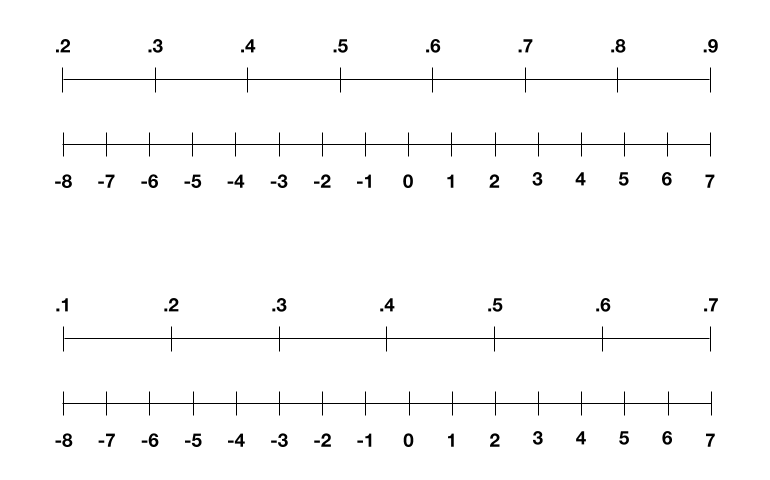
A menudo vemos las redes neuronales dibujadas como algo con nodos y conexiones, como la imagen de arriba. Pero para una computadora, estos también se convierten en una serie de números. Cada nodo tiene un llamado valor de activación, que suele oscilar entre 0 y 1, y cada conexión tiene un peso,que suele oscilar entre -1 y 1.
Podríamos escalarlos de la misma manera que lo hicimos con nuestros píxeles, pero las activaciones y los pesos también cambian con cada ronda de entrenamiento. Por ejemplo, a veces las activaciones oscilan entre 0,2 y 0,9 en una ronda y 0,1 a 0,7 en otra. Así que el grupo de IBM descubrió un nuevo truco en 2018: redimensionar esos rangos para que se estiren entre -8 y 7 en cada ronda (como se muestra a continuación), lo que evita efectivamente perder demasiada precisión.
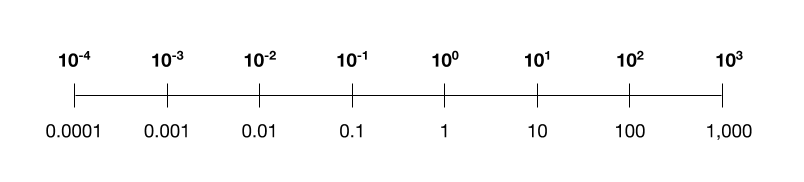
Pero luego nos queda una última pieza: cómo representar en cuatro bits los valores intermedios que parecen durante el entrenamiento. Lo que es un desafío es que estos valores pueden abarcar varios órdenes de magnitud, a diferencia de los números que estábamos manejando para nuestras imágenes, pesos y activaciones. Pueden ser diminutos, como 0.001, o enormes, como 1.000. Tratar de escalar linealmente esto a entre -8 y 7 pierde toda la granularidad en el extremo diminuto de la escala.
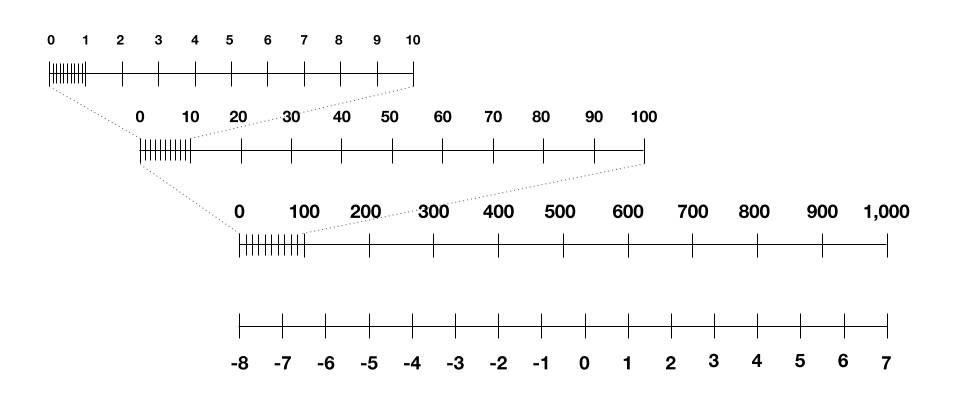
Después de dos años de investigación, los investigadores finalmente rompieron el rompecabezas: tomando prestada una idea existente de otros, escalan estos números intermedios logarítmicamente. Para ver lo que quiero decir, a continuación hay una escala logarítmica que podría reconocer, con una llamada “base” de 10, utilizando sólo cuatro bits de complejidad. (Los investigadores en su lugar utilizan una base de 4, porque el ensayo y el error mostraron que esto funcionó mejor.) Puede ver cómo le permite codificar números pequeños y grandes dentro de las restricciones de bits.
Con todas estas piezas en su lugar, este último artículo muestra cómo se unen. Los investigadores de IBM ejecutan varios experimentos en los que simulan el entrenamiento de 4 bits para una variedad de modelos de aprendizaje profundo en visión computarizada, habla y procesamiento de lenguaje natural. Los resultados muestran una pérdida limitada de precisión en el rendimiento general de los modelos en comparación con el aprendizaje profundo de 16 bits. El proceso también es más de siete veces más rápido y siete veces más eficiente energéticamente.
Trabajo futuro
Todavía hay varios pasos más antes de que el aprendizaje profundo de 4 bits se convierta en una práctica real. El documento sólo simula los resultados de este tipo de entrenamiento. Hacerlo en el mundo real requeriría un nuevo hardware de 4 bits. En 2019, IBM Research lanzó un AI Hardware Center para acelerar el proceso de desarrollo y producción de dichos equipos. Kailash Gopalakrishnan, un becario y gerente sénior de IBM que supervisó este trabajo, dice que espera tener hardware de 4 bits listo para el entrenamiento de aprendizaje profundo en tres o cuatro años.
Boris Murmann, un profesor de Stanford que no participó en la investigación, llama emocionantes a los resultados. “Este avance abre la puerta a la formación en entornos con recursos limitados”, dice. No necesariamente haría posibles nuevas aplicaciones, pero haría que las existentes fueran más rápidas y que se agoten menos la batería “por un buen margen”. Apple y Google, por ejemplo, han tratado cada vez más de mover el proceso de formación de sus modelos de IA, como los sistemas de voz a texto y autocorrección, lejos de la nube y en los teléfonos de los usuarios. Esto preserva la privacidad de los usuarios manteniendo sus datos en su propio teléfono mientras mejora las capacidades de IA del dispositivo.
Pero Murmann también señala que hay que hacer más para verificar la solidez de la investigación. En 2016, su grupo publicó un artículo que demostró entrenamiento de 5 bits. Pero el enfoque no se desmescrá con el tiempo. “Nuestro enfoque simple se desmoronó porque las redes neuronales se volvieron mucho más sensibles”, dice. “Así que no está claro si una técnica como esta también sobreviviría a la prueba del tiempo”.
Sin embargo, el artículo “motivará a otras personas a examinar esto con mucho cuidado y estimular nuevas ideas”, dice. “Este es un avance muy bienvenido.”
Fuente: https://www.technologyreview.com/2020/12/11/1014102/ai-trains-on-4-bit-computers/