

por David Petersson
Para establecer expectativas realistas de la IA , sin perder oportunidades, es importante comprender los algoritmos, tanto sus capacidades como sus limitaciones.
En este artículo, exploramos dos algoritmos que han impulsado el campo de la IA hacia adelante: las redes neuronales convolucionales (CNN) y las redes neuronales recurrentes (RNN). Cubriremos qué son, cómo funcionan, cuáles son sus limitaciones y dónde se complementan.
Pero primero, un breve resumen de las principales diferencias entre una CNN y una RNN.
- Las CNN se utilizan comúnmente para resolver problemas relacionados con datos espaciales, como imágenes. Los RNN son más adecuados para analizar datos secuenciales temporales, como texto o videos.
- Una CNN tiene una arquitectura diferente a una RNN. Las CNN son “redes neuronales de retroalimentación” que utilizan filtros y capas de agrupación, mientras que las RNN retroalimentan los resultados a la red (más sobre este punto a continuación).
- En las CNN, el tamaño de la entrada y la salida resultante son fijos. Es decir, una CNN recibe imágenes de tamaño fijo y las envía al nivel apropiado, junto con el nivel de confianza de su predicción. En RNN, el tamaño de la entrada y la salida resultante pueden variar.
- Los casos de uso de las CNN incluyen el reconocimiento facial, el análisis médico y la clasificación. Los casos de uso para RNN incluyen traducción de texto, procesamiento de lenguaje natural, análisis de sentimientos y análisis de voz.
ANN, CNN, RNN: ¿Qué son las redes neuronales?
La red neuronal fue ampliamente reconocida en el momento de su invención como un gran avance en el campo. Tomando una pista de cómo funcionan las neuronas en nuestro cerebro, la arquitectura de la red neuronal introdujo un algoritmo que permitió a la computadora ajustar su toma de decisiones, en otras palabras, aprender.
Una red neuronal artificial , o ANN, consta de muchos perceptrones . En su forma más simple, un perceptrón consiste en una función que toma dos entradas, las multiplica por dos pesos aleatorios , las suma junto con un valor de sesgo , pasa los resultados a través de una función de activación e imprime los resultados. Los pesos y los valores de sesgo son ajustables y definen el resultado del perceptrón, dados dos valores de entrada específicos.
Esta arquitectura fue genial: la combinación de los perceptrones generó capas de variables ajustables que podían asumir casi cualquier tarea. El problema, sin embargo, era qué números elegir para los pesos y los valores de sesgo para hacer un cálculo correcto.
Sesgo en neuronas artificiales
Tanto en las redes artificiales como en las biológicas, cuando las neuronas procesan la entrada que reciben, deciden si la salida debe pasarse a la siguiente capa como entrada. La decisión de enviar información o no se llama sesgo y está determinada por una función de activación integrada en el sistema. Por ejemplo, una neurona artificial solo puede pasar una señal de salida a la siguiente capa si sus entradas (que en realidad son voltajes) suman un valor por encima de algún valor de umbral particular.
– Linda Tucci
Siga este enlace para obtener más información sobre las neuronas artificiales .
Esto se solucionó mediante un mecanismo llamado retropropagación . A la RNA se le da una entrada y el resultado se compara con la salida esperada. La diferencia entre la salida deseada y la salida real se devuelve a la red neuronal mediante un cálculo matemático, que determina cómo se debe ajustar cada perceptrón para alcanzar el resultado deseado.
Este procedimiento, en el que se entrena a la IA, se repite hasta que se alcanza un nivel satisfactorio de precisión.
Una red neuronal como esta funciona muy bien para predicciones estadísticas simples, como predecir el equipo de fútbol favorito de una persona, dada la edad, el sexo y la ubicación geográfica de la persona. Pero, ¿cómo se puede utilizar la IA para tareas más difíciles como el reconocimiento de imágenes ? La respuesta plantea la pregunta de cómo alimentamos los datos a la red en primer lugar.

Redes neuronales convolucionales
Lo que vemos como imágenes en una computadora es en realidad un conjunto de valores de color, distribuidos en un cierto ancho y alto. Lo que vemos como formas y objetos aparecen como una matriz de números en la máquina. Las redes neuronales convolucionales dan sentido a estos datos a través de un mecanismo llamado filtros y luego agrupando capas .
“Un filtro es una matriz de números aleatorios. En una CNN, los filtros se multiplican por representaciones matriciales de partes de la imagen, escaneando efectivamente la imagen píxel por píxel y obteniendo el valor promedio de todos los píxeles adyacentes, detectando así las características más importantes, “, explicó Ajay Divakaran, director técnico senior del Laboratorio de Visión y Aprendizaje en el Centro de Tecnologías de la Visión de SRI International, un instituto de investigación científica sin fines de lucro.
“Esta información pasa a través de una capa de agrupación, que condensa el mapa de características adquirido en su información más esencial”, agregó. Este último paso reduce en gran medida el tamaño de los datos y hace que la red neuronal sea mucho más rápida. La información resultante luego se alimenta a la red neuronal.
Una CNN consta de varias capas de perceptrones y los filtros construyen efectivamente una red que comprende cada vez más la imagen con cada capa que pasa. Mientras que la primera capa comprende los contornos y los bordes, la segunda capa comienza a comprender las formas y la tercera comprende los objetos. El poder de este modelo es su capacidad para reconocer objetos, sin importar en qué parte de la imagen aparezcan o su rotación.
Las CNN son excelentes para reconocer objetos, animales y personas, pero ¿qué pasa si queremos entender lo que está sucediendo en las imágenes?
Por ejemplo, considere la imagen de una pelota en el aire. ¿Cómo podemos saber si la pelota se lanza y sube o si está cayendo? Responder a esta pregunta requeriría más información que una sola imagen; necesitaríamos un video. La secuencia de las imágenes determinaría si la pelota va hacia arriba o hacia abajo. Pero, ¿cómo podemos hacer que las redes neuronales recuerden la información en la que habían trabajado anteriormente y la incorporen a sus cálculos?
Redes neuronales recurrentes
El problema de recordar va más allá de los videos; de hecho, muchos algoritmos de comprensión del lenguaje natural (que generalmente solo tratan con texto) requieren algún tipo de recuerdo, como el tema de la discusión o las palabras anteriores en la oración.
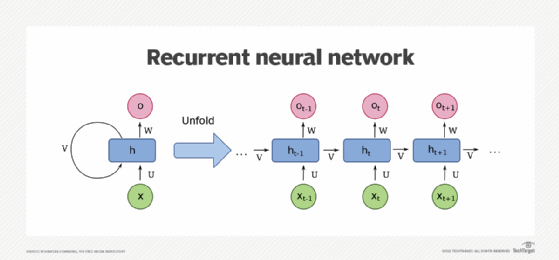
Las redes neuronales recurrentes se diseñaron para abordar exactamente este problema. Este algoritmo retroalimenta el resultado en sí mismo, convirtiéndolo en parte de la respuesta final.
Para ilustrarlo, suponga que queremos traducir la siguiente oración: “¿Qué fecha es?” El algoritmo alimenta cada palabra por separado a la red neuronal, y cuando llega a la palabra “eso”, su salida ya está influenciada por la palabra “qué”.
Sin embargo, los RNN tienen un problema. En el ejemplo anterior, las palabras que se introducen en último lugar en la red tienen una mayor influencia en el resultado (en nuestro caso, las palabras “¿lo es?”). Esas dos palabras no nos dan mucha comprensión de la oración completa: el algoritmo sufre de “pérdida de memoria”. Este problema no ha pasado desapercibido y los algoritmos más nuevos, como Long Short-Term Memory (LSTM), resuelven ese problema.
El siguiente diagrama, de Wikimedia Commons , muestra una red neuronal recurrente de una unidad.
CNN vs RNN: fortalezas y debilidades
Habiendo visto cómo se diseñó cada red, ahora podemos señalar las fortalezas y debilidades de cada una.
“Se prefieren las CNN para interpretar datos visuales, datos escasos o datos que no vienen en secuencia”, explicó Prasanna Arikala, CTO de Kore.ai, una empresa de desarrollo de chatbot. “Las redes neuronales recurrentes, por otro lado, están diseñadas para reconocer datos secuenciales o temporales. Hacen mejores predicciones considerando el orden o secuencia de los datos en relación con los nodos de datos anteriores o siguientes”.Hoy en día, los límites entre el uso de CNN y RNN son algo difusos.Fred NavruzovLíder de ciencia de datos, Competera
Las aplicaciones en las que las CNN son particularmente útiles incluyen la detección de rostros , el análisis médico, el descubrimiento de fármacos y el análisis de imágenes, dijo Arikala. Los RNN son útiles para la traducción de idiomas, la extracción de entidades, la inteligencia conversacional, el análisis de sentimientos y el análisis del habla.
Debido a que las RNN se basan en el estado anterior para predecir el estado futuro, “tienen sentido para el mercado de valores, ya que predecir hacia dónde se dirigirá una acción depende mucho de dónde ha estado antes”, dijo.
Sin embargo, como aprendimos anteriormente, al escanear una imagen, el filtro de una CNN tiene en cuenta los píxeles adyacentes mientras funciona. ¿No podría utilizar el mismo mecanismo para palabras adyacentes?
“No es que tal enfoque no funcione en absoluto”, explicó Divakaran. “[Pero] es un enfoque innecesariamente indirecto”. Según Divakaran, tratar de utilizar las capacidades de modelado espacial de la CNN para capturar lo que es básicamente un fenómeno temporal es subóptimo por definición y requiere mucho más esfuerzo y memoria para lograr la misma tarea.
CNN vs RNN: modelos complementarios
Pero hay casos en los que los dos modelos se complementan. Arikala compartió un caso interesante.
“Para algunos de los idiomas asiáticos como el chino, el japonés y el coreano, donde los caracteres son como imágenes especiales, usamos redes neuronales profundas construidas con una combinación de CNN y RNN para la detección de intenciones y el análisis de sentimientos “, dijo.
En estos llamados lenguajes logográficos, algunos caracteres pueden traducirse a una o varias palabras en inglés, mientras que otros solo significan algo cuando se les añade un sufijo a otros caracteres, cambiando el significado del carácter original.
“La razón por la que una combinación de redes neuronales funciona aquí es que hacemos tokenización de caracteres en lenguajes logográficos en comparación con [usar] la tokenización de Treebank / WordNet en otros idiomas”, explicó Arikala. “Una combinación de CNN y LSTM funciona mucho mejor que RNN puro”.
Fred Navruzov, el líder de ciencia de datos en Competera, una empresa de inteligencia artificial que ayuda a los minoristas a establecer precios óptimos, estuvo de acuerdo en que los modelos pueden cooperar en lugar de competir entre sí.
“Hoy en día, los límites entre el uso de CNN y RNN son algo difusos, ya que puede combinar esas arquitecturas en CRNN para una mayor efectividad en la resolución de tareas específicas como etiquetado de video o reconocimiento de gestos”, dijo. En un análisis de una secuencia de fotogramas de vídeo, por ejemplo, RNN se puede utilizar para capturar información temporal y CNN se puede utilizar para extraer características espaciales de fotogramas individuales.
Profundice en el universo en expansión de las redes neuronales
Es importante tener en cuenta que las CNN y las RNN son solo dos de las categorías más populares de arquitecturas de redes neuronales. Hay docenas de otros enfoques para organizar la forma en que las neuronas se conectan, y algunos que eran oscuros hace unos años están experimentando un crecimiento significativo en la actualidad.
Entre los ejemplos de nuevas redes neuronales se incluyen los siguientes:
- Transformers , que están ayudando a resolver muchas de las limitaciones de los RNN en el procesamiento de grandes volúmenes de texto, audio o secuencias de video y en la construcción de grandes modelos de lenguaje como Google BERT .
- Generative Adversarial Networks , que combinan múltiples redes neuronales en competencia para hacer posible diseñar drogas, generar falsificaciones digitales o mejorar la producción de medios.
- Autoencoders , que se están convirtiendo en la herramienta preferida para la reducción de dimensionalidad, compresión de imágenes y codificación de datos.
Además, los servicios de inteligencia artificial están encontrando formas de crear automáticamente nuevas redes neuronales altamente optimizadas sobre la marcha utilizando la búsqueda de arquitectura neuronal. Estas técnicas crean una arquitectura inicial para un problema particular y analizan interactivamente los resultados para ajustar mejor las arquitecturas.
Las implementaciones actuales de aprendizaje de máquinas automatizadas incluyen AutoML de Google , AutoAI de IBM Watson , y la fuente abierta AutoKeras. Los investigadores también están explorando mejores formas de combinar múltiples modelos de redes neuronales de la misma o diferentes arquitecturas utilizando técnicas de aprendizaje por conjuntos.
Mejores técnicas para comparar el rendimiento y la precisión de las arquitecturas de redes neuronales también podrían desempeñar un papel para facilitar que los investigadores examinen muchas opciones para una tarea de IA en particular. Los investigadores están comenzando a encontrar formas creativas de aplicar técnicas estadísticas tradicionales para comparar el rendimiento relativo de diferentes arquitecturas de redes neuronales.
George Lawton contribuyó a esta historia.
Fuente: https://searchenterpriseai.techtarget.com/feature/CNN-vs-RNN-How-they-differ-and-where-they-overlap