

por Kyle Wiggers | TechCrunch
“Gato es lo que DeepMind describe como un sistema de ‘propósito general’, un sistema al que se le puede enseñar a realizar muchos tipos diferentes de tareas. Los investigadores de DeepMind entrenaron a Gato para completar 604, para ser exactos, incluyendo subtítulos de imágenes, participación en diálogos, apilamiento de bloques con un brazo robótico real y juegos de Atari”.

El logro final para algunos en la industria de la IA es crear un sistema con inteligencia general artificial (AGI), o la capacidad de comprender y aprender cualquier tarea que un ser humano pueda. Relegado durante mucho tiempo al dominio de la ciencia ficción, se ha sugerido que AGI generaría sistemas con la capacidad de razonar, planificar, aprender, representar conocimiento y comunicarse en lenguaje natural.
No todos los expertos están convencidos de que AGI es un objetivo realista, o incluso posible. Pero se podría argumentar que DeepMind, el laboratorio de investigación respaldado por Alphabet, dio un paso adelante esta semana con el lanzamiento de un sistema de inteligencia artificial llamado Gato .
Gato es lo que DeepMind describe como un sistema de “propósito general”, un sistema al que se le puede enseñar a realizar muchos tipos diferentes de tareas. Los investigadores de DeepMind entrenaron a Gato para completar 604, para ser exactos, incluyendo subtítulos de imágenes, participación en diálogos, apilamiento de bloques con un brazo robótico real y juegos de Atari.
“La mayoría de los sistemas de IA actuales funcionan en una sola tarea o en un dominio limitado a la vez. La importancia de este trabajo es principalmente que un agente con un [modelo] puede realizar cientos de tareas muy diferentes, incluso controlar un robot real y hacer subtítulos básicos y chatear”, Scott Reed, científico investigador de DeepMind y uno de los co -creadores de Gato, le dijeron a TechCrunch por correo electrónico.
Jack Hessel, científico investigador del Instituto Allen de IA, señala que un solo sistema de IA que pueda resolver muchas tareas no es nuevo. Por ejemplo, Google recientemente comenzó a usar un sistema en la Búsqueda de Google llamado modelo unificado multitarea, o MUM , que puede manejar texto, imágenes y videos para realizar tareas, desde encontrar variaciones interlingüísticas en la ortografía de una palabra hasta relacionar una consulta de búsqueda con una imagen. . Pero lo que es potencialmente más nuevo aquí, dice Hessel, es la diversidad de las tareas que se abordan y el método de entrenamiento.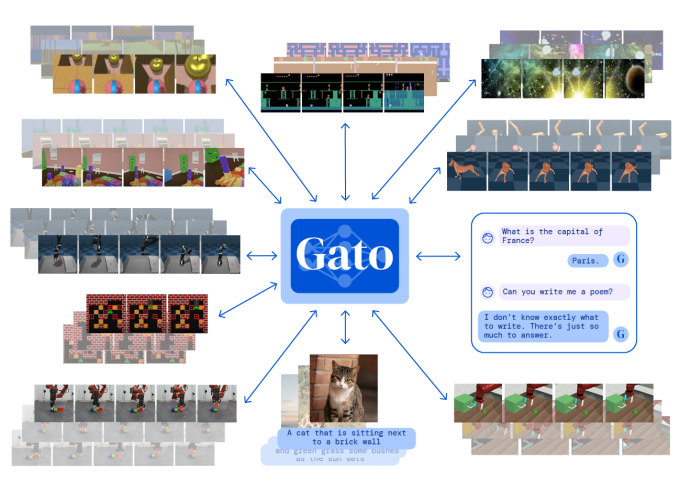
Arquitectura Gato de DeepMind. Créditos de imagen: DeepMind
“Hemos visto evidencia anteriormente de que los modelos individuales pueden manejar conjuntos de entradas sorprendentemente diversos”, dijo Hessel a TechCrunch por correo electrónico. “Desde mi punto de vista, la pregunta central cuando se trata del aprendizaje multitarea… es si las tareas se complementan entre sí o no. Podría imaginar un caso más aburrido si el modelo separa implícitamente las tareas antes de resolverlas, por ejemplo, ‘Si detecto la tarea A como entrada, usaré la subred A. Si en cambio detecto la tarea B, usaré una subred B diferente. ‘ Para esa hipótesis nula, se podría lograr un rendimiento similar entrenando a A y B por separado, lo cual es decepcionante. Por el contrario, si el entrenamiento conjunto de A y B conduce a mejoras para cualquiera (¡o para ambos!), entonces las cosas son más emocionantes”.
Como todos los sistemas de IA, Gato aprendió con el ejemplo, ingiriendo miles de millones de palabras, imágenes del mundo real y entornos simulados, pulsaciones de botones, torsión de articulaciones y más en forma de fichas. Estos tokens sirvieron para representar datos de una manera que Gato pudiera entender, lo que permitió que el sistema, por ejemplo, descubriera la mecánica de Breakout, o qué combinación de palabras en una oración podría tener sentido gramatical.
Gato no necesariamente hace bien estas tareas . Por ejemplo, al chatear con una persona, el sistema a menudo responde con una respuesta superficial o objetivamente incorrecta (por ejemplo, “Marsella” en respuesta a “¿Cuál es la capital de Francia?”). Al subtitular imágenes, Gato confunde a las personas. Y el sistema apila correctamente los bloques utilizando un robot del mundo real solo el 60 % de las veces.
Pero en 450 de las 604 tareas antes mencionadas, DeepMind afirma que Gato se desempeña mejor que un experto más de la mitad de las veces.
“Si piensas que necesitamos [sistemas] generales, que es mucha gente en el área de inteligencia artificial y aprendizaje automático, entonces [Gato es] un gran problema”, Matthew Guzdial, profesor asistente de ciencias de la computación en la Universidad de Alberta, le dijo a TechCrunch por correo electrónico. “Creo que las personas que dicen que es un paso importante hacia AGI lo exageran un poco, ya que todavía no estamos en la inteligencia humana y es probable que no lleguemos allí pronto (en mi opinión). Personalmente, estoy más en el campo de muchos modelos [y sistemas] pequeños que son más útiles, pero definitivamente hay beneficios para estos modelos generales en términos de su rendimiento en tareas fuera de sus datos de entrenamiento”.
Curiosamente, desde el punto de vista de la arquitectura, Gato no es muy diferente de muchos de los sistemas de IA que se producen actualmente. Comparte características en común con GPT-3 de OpenAI en el sentido de que es un “Transformador”. Desde 2017, el Transformer se ha convertido en la arquitectura elegida para tareas de razonamiento complejo, demostrando una aptitud para resumir documentos, generar música, clasificar objetos en imágenes y analizar secuencias de proteínas.

Las diversas tareas que Gato aprendió a completar. Créditos de imagen: DeepMind
Quizás aún más notable, Gato es mucho más pequeño que los sistemas de una sola tarea, incluido GPT-3, en términos de recuento de parámetros. Los parámetros son las partes del sistema aprendidas de los datos de entrenamiento y esencialmente definen la habilidad del sistema en un problema, como la generación de texto. Gato tiene solo 1.200 millones, mientras que GPT-3 tiene más de 170.000 millones.
Los investigadores de DeepMind mantuvieron Gato deliberadamente pequeño para que el sistema pudiera controlar un brazo robótico en tiempo real. Pero plantean la hipótesis de que, si se amplía, Gato podría abordar cualquier “tarea, comportamiento y encarnación de interés”.
Suponiendo que este sea el caso, habría que superar varios otros obstáculos para que Gato sea superior en tareas específicas a los sistemas de tareas únicas de última generación, como la incapacidad de Gato para aprender continuamente. Como la mayoría de los sistemas basados en Transformer, el conocimiento del mundo de Gato se basa en los datos de entrenamiento y permanece estático. Si le hace a Gato una pregunta sensible a la fecha, como el actual presidente de los EE. UU., es probable que responda incorrectamente.
El Transformer, y Gato, por extensión, tiene otra limitación en su ventana de contexto, o la cantidad de información que el sistema puede “recordar” en el contexto de una tarea determinada. Incluso los mejores modelos de lenguaje basados en Transformer no pueden escribir un ensayo largo, y mucho menos un libro, sin dejar de recordar los detalles clave y, por lo tanto, perder el hilo de la trama. El olvido ocurre en cualquier tarea, ya sea escribir o controlar un robot, por lo que algunos expertos lo han llamado el “talón de Aquiles” del aprendizaje automático.
Por estas y otras razones, Mike Cook, miembro del colectivo de investigación Knives & Paintbrushes, advierte que no se debe asumir que Gato es un camino hacia una verdadera IA de propósito general.
“Creo que el resultado está abierto a malas interpretaciones, de alguna manera. Suena emocionante que la IA pueda hacer todas estas tareas que suenan muy diferentes, porque para nosotros parece que escribir texto es muy diferente a controlar un robot. Pero, en realidad, esto no es muy diferente de que GPT-3 comprenda la diferencia entre el texto en inglés ordinario y el código de Python”, dijo Cook a TechCrunch por correo electrónico. “Gato recibe datos de entrenamiento específicos sobre estas tareas, al igual que cualquier otra IA de su tipo, y aprende cómo los patrones en los datos se relacionan entre sí, incluido el aprendizaje de asociar ciertos tipos de entradas con ciertos tipos de salidas. Esto no quiere decir que sea fácil, pero para el observador externo esto puede parecer que la IA también puede preparar una taza de té o aprender fácilmente otras diez o cincuenta tareas, y no puede hacer eso. Sabemos que los enfoques actuales para el modelado a gran escala pueden permitirle aprender múltiples tareas a la vez. Creo que es un buen trabajo, pero no me parece un peldaño importante en el camino hacia nada”.