

- Oscar Kjell – Docente, Departamento de Psicología, Universidad de Lund
- Salvatore Giorgi – Departamento de Informática y Ciencias de la Información, Universidad de Pensilvania
- H. Andrés Schwartz – Profesor asociado, Informática, Universidad de Stony Brook
- Johannes C. Eichstaedt – Profesor asistente, Departamento de Psicología e Instituto de IA centrada en el ser humano, Universidad de Stanford
Cita: Kjell, O., Giorgi, S., Schwartz, HA y Eichstaedt, JC (2023). Hacia la Medición del Bienestar con las Redes Sociales a través del Espacio, el Tiempo y las Culturas: Tres Generaciones de Progreso. En World Happiness Report 2023 (11.ª ed., capítulo 5). Red de Soluciones de Desarrollo Sostenible.
Reconocimiento: Esta investigación fue apoyada por el Instituto Stanford para la Inteligencia Artificial centrada en el ser humano y NIH/NSF Smart and Connected Health R01 R01MH125702 y una subvención de NIH-NIAAA R01 AA028032. El trabajo fue financiado además por el Consejo Sueco de Investigación (2019-06305). Agradecemos a los revisores y al equipo del Informe Mundial de la Felicidad (WHR) por sus valiosos comentarios.

- Resumen
- El conjunto de datos más grande en la historia humana
- La evolución de los análisis de bienestar en las redes sociales
- Gen 1: Muestras aleatorias de publicaciones en redes sociales
- Gen 2: Muestreo a nivel de persona de feeds de Twitter
- Gen 3: Muestreo digital de cohortes: el futuro de la medición longitudinal
- Resumen y direcciones futuras
- Un completo conjunto de herramientas metodológicas para abordar los sesgos y proporcionar mediciones precisas
- Limitaciones: El lenguaje evoluciona en el espacio y el tiempo.
- Limitaciones: Cambios en la plataforma de Twitter
- Direcciones futuras: más allá de las redes sociales y entre culturas
- Consideraciones éticas
- Conclusión y perspectiva
- Referencias
Resumen
Los datos de las redes sociales se han convertido en el mayor conjunto de datos transversales y longitudinales sobre emociones, cogniciones y comportamientos en la historia humana. Usar datos de redes sociales, como Twitter, para evaluar el bienestar a gran escala promete ser rentable, estar disponible casi en tiempo real y con una alta resolución espacial (por ejemplo, hasta la ciudad, el condado o niveles de código postal).
Los métodos de evaluación han experimentado una mejora sustancial en la última década. Por ejemplo, la predicción transversal de la satisfacción con la vida en los condados de EE. UU. de Twitter ha mejorado de r = 0,37 a r = 0,54 (cuando se entrena y se compara con las encuestas de los CDC, fuera de la muestra), [1] lo que supera la predicción poder de registro. ingreso de r = .35 . [2] Usando encuestas telefónicas de Gallup, la estimación basada en Twitter alcanza precisiones de r = .62. [3]Más allá de la rentabilidad de esta medición discreta, estos enfoques de “macrodatos” son flexibles en el sentido de que pueden operar en diferentes niveles de agregación geográfica (naciones, estados, ciudades y condados) y cubren una amplia gama de constructos de bienestar que abarcan satisfacción con la vida, afecto positivo/negativo, así como la expresión relativa de rasgos positivos, como la empatía y la confianza. [4]
Quizás lo más prometedor es que el tamaño de los conjuntos de datos de las redes sociales permite la medición en el espacio y el tiempo hasta condado-mes, una granularidad muy adecuada para probar hipótesis sobre los determinantes y las consecuencias del bienestar con diseños cuasi-experimentales.
En este capítulo, proponemos que los métodos para medir los estados psicológicos de las poblaciones han evolucionado a lo largo de dos ejes principales que reflejan (1) cómo se recopilan, agregan y ponderan los datos de las redes sociales y (2) cómo se derivan las estimaciones psicológicas del lenguaje no estructurado. .
Para fines organizativos, argumentamos que (1) los métodos para agregar datos han evolucionado aproximadamente durante tres generaciones. En la primera generación (Gen 1) , se agregaron muestras aleatorias de tweets (como las obtenidas a través de la fuente de datos aleatorios de Twitter) y luego se analizaron. En la segunda generación (Gen 2) , los datos de Twitter se agregan a nivel de persona, por lo que las muestras geográficas o temporales del idioma se analizan como una muestra de individuos en lugar de una colección de tweets. Generación 2 más avanzadaLos enfoques también introducen pesos a nivel de persona a través de técnicas de estratificación posterior, similares a las encuestas telefónicas representativas, para disminuir los sesgos de selección y aumentar la validez externa de las mediciones. Sugerimos que estamos al comienzo de la tercera generación de métodos (Gen 3) que aprovechan los diseños longitudinales dentro de la persona (es decir, modelan individuos a lo largo del tiempo) además de los avances de Gen 2 para lograr una mayor precisión en la evaluación y permitir pruebas cuasi-experimentales. diseños de investigación. Los primeros resultados indican que estas nuevas generaciones de métodos a nivel de persona permiten estudios de cohortes digitales y pueden producir la mayor estabilidad longitudinal y validez externa.
El tamaño de los conjuntos de datos de las redes sociales permite la medición en el espacio y el tiempo hasta condado-mes
Con respecto a (2) cómo se estiman los estados y rasgos psicológicos a partir del lenguaje, discutimos brevemente la evolución de los métodos en términos de tres niveles (con fines organizativos), que se han discutido en trabajos anteriores. [5] Estos son el uso de diccionarios y listas de palabras anotadas ( Nivel 1 ), modelos basados en aprendizaje automático, como los sistemas de sentimientos modernos ( Nivel 2 ) y modelos de lenguaje extenso ( Nivel 3 ).
Estos métodos han abordado de forma iterativa la mayoría de las principales preocupaciones sobre el uso de datos ruidosos de las redes sociales para la estimación de la población. Específicamente, el uso de modelos de predicción de aprendizaje automático aplicados a funciones de vocabulario abierto ( Nivel 2 ) entrenados en estimaciones de población relativamente confiables (como encuestas telefónicas aleatorias) permite que la señal del idioma se ajuste a la “verdad básica”. Aborda implícitamente (a) los sesgos de autopresentación y los sesgos de deseabilidad social (solo ajustando la señal que generaliza), como lo demuestran las altas precisiones de predicción fuera de la muestra. La agregación a nivel de usuario y la ponderación equitativa resultante de los usuarios en Gen 2 reducen el error debido a (b) bots. A través de la ponderación, (c) se abordan los sesgos de selección. Por último, a través del seguimiento de los cambios dentro del usuario enGen 3 , (d) las estimaciones de las redes sociales pueden generar estimaciones longitudinales estables más allá de los análisis transversales, y (e) proporcionar un control de diseño metodológico más matizado (como a través de diseños de variables instrumentales o diferencias en diferencias).
En conjunto, la medición del bienestar basada en las redes sociales ha recorrido un largo camino. Alrededor de 2010, comenzó como demostraciones tecnológicas que aplicaban diccionarios simples (diseñados para diferentes aplicaciones) a transmisiones aleatorias ruidosas y no estabilizadas de datos de Twitter que producían estimaciones de series temporales poco confiables. Con la evolución a lo largo de generaciones de agregación de datos y niveles de modelos lingüísticos, los métodos actuales de vanguardia producen estimaciones regionales transversales sólidas del bienestar. [6] Están madurando hasta el punto de producir estimaciones longitudinales estables que permitan detectar cambios significativos en el bienestar y la salud mental de países, regiones y ciudades.
Gran parte del desarrollo inicial de estos métodos tuvo lugar en los EE. UU., principalmente porque la mayoría de los datos de las encuestas de bienestar para la capacitación y la evaluación comparativa de los modelos se recopilaron allí. Sin embargo, con la maduración de los métodos y la reproducción de los hallazgos por múltiples laboratorios, el enfoque está listo para implementarse en diferentes países del mundo, como lo demostró el Instituto Nacional de Estadística y Geografía (INEGI) de México al construir un primer proyecto de este tipo prototipo[7]

El conjunto de datos más grande en la historia humana
La necesidad de una medición oportuna del bienestar
Para lograr objetivos políticos de alto nivel, como la promoción del bienestar según lo propuesto en los Objetivos de Desarrollo Sostenible, [8] los formuladores de políticas deben poder evaluar la eficacia de diferentes implementaciones en instituciones y organizaciones del sector público y privado. Para eso, “todas las personas del mundo deben estar representadas en datos actualizados y oportunos que puedan usarse para medir el progreso y tomar decisiones para mejorar la vida de las personas”. [9]Específicamente, los datos continuos sobre el bienestar de las personas pueden ayudar a evaluar la política, brindar responsabilidad y ayudar a cerrar los ciclos de retroalimentación sobre lo que funciona y lo que no. Para dicha evaluación continua, se necesitan estimaciones de bienestar a niveles superiores a los anuales y nacionales de agregación temporal y geográfica. Particularmente con la vista puesta en contextos de escasos recursos y economías en desarrollo, sería ideal si dichas estimaciones pudieran derivarse de manera discreta y rentable mediante el análisis de huellas digitales que las poblaciones producen naturalmente en las redes sociales.
El potencial de los datos de las redes sociales para la salud y el bienestar de la población
Como quizás la fuente de datos más destacada, los datos de las redes sociales se han convertido en el mayor conjunto de datos transversales y longitudinales sobre las emociones, las cogniciones, los comportamientos y la salud humanos en la historia de la humanidad. [10] Las plataformas de redes sociales se utilizan ampliamente en todo el mundo. En una encuesta realizada en 11 economías emergentes y países en desarrollo en una amplia gama de regiones del mundo (p. ej., Venezuela, Kenia, India, Líbano), se descubrió que las plataformas de redes sociales (como Facebook) y las aplicaciones de mensajería (como WhatsApp) son ampliamente utilizado En los países estudiados, una mediana del 64 % de los adultos encuestados informan que actualmente usan al menos una plataforma de redes sociales o una aplicación de mensajería, que van desde el 31 % (India) al 85 % (Líbano). [11]
Durante la última década, se ha desarrollado una literatura, que abarca la lingüística computacional, la informática, las ciencias sociales, la salud pública y la medicina, que explora las redes sociales para comprender la salud, el progreso y el bienestar humanos. Por ejemplo, las redes sociales se han utilizado para medir la salud mental, incluida la depresión, [12] comportamientos de salud, incluido el consumo excesivo de alcohol, [13] dolencias de salud pública más generales (p. ej., alergias e insomnio), [14] como enfermedades transmisibles, incluyendo la gripe [15] y la influenza H1N1, [16] así como el riesgo de enfermedades no transmisibles, [17] incluida la mortalidad por enfermedades del corazón. [18]
Durante la última década, se ha desarrollado un cuerpo de investigación, que abarca la lingüística computacional, la informática, las ciencias sociales, la salud pública y la medicina, que extrae las redes sociales para comprender la salud, el progreso y el bienestar humanos.
La medición de los diferentes componentes del bienestar.
Se entiende ampliamente que el bienestar tiene múltiples componentes, incluidos los componentes evaluativos (satisfacción con la vida), afectivos (emociones positivas y negativas) y eudaimónicos (propósito; OCDE, 2013). Los métodos existentes en las ciencias sociales y en el procesamiento del lenguaje natural han sido especialmente adecuados para medir el componente afectivo/emocional del bienestar. Es decir, en psicología, existen diccionarios de emociones positivas y negativas, como los proporcionados por el software Linguistic Inquiry and Word Count (LIWC), ampliamente utilizado. [19] En el procesamiento del lenguaje natural, el “análisis de sentimientos”, cuyo objetivo es medir el afecto/sentimiento general de los textos, es ampliamente estudiado por diferentes grupos de investigación que comparan rutinariamente el rendimiento de los sistemas de predicción de sentimientos en “tareas compartidas”. [20]Como resultado, los datos de las redes sociales generalmente se han analizado con diccionarios de emociones y análisis de sentimientos para obtener estimaciones de bienestar. Al revisar el trabajo inicial de las estimaciones de bienestar de las redes sociales, estos análisis centrados en el afecto en combinación con técnicas simples de muestreo aleatorio de Twitter llevaron a algunos académicos a concluir que las estimaciones de bienestar “proporcionan una precisión satisfactoria para las experiencias emocionales, pero aún no para las experiencias emocionales”. satisfacción de vida.” [21]
Otros investigadores revisaron recientemente estudios que utilizan el lenguaje de las redes sociales para evaluar el bienestar. [22] De 45 estudios, seis utilizaron las redes sociales para estimar el bienestar agregado de las geografías, y todos ellos se basaron en datos de Twitter y en diccionarios emocionales y de sentimientos para derivar sus estimaciones. Sin embargo, debido a que la satisfacción con la vida generalmente se encuesta más ampliamente que el bienestar afectivo, cinco de los seis estudios utilizaron la satisfacción con la vida como un resultado contra el cual se validaron las estimaciones basadas en el lenguaje (afecto); solo un estudio [23] también incluyó medidas independientes de afecto positivo y negativo para comparar las medidas de lenguaje (a nivel de condado, de Gallup).
Por lo tanto, en conjunto, existe una divergencia en esta literatura naciente sobre la estimación del bienestar geográfico entre los métodos de medición predominantes que ponen en primer plano el bienestar afectivo (como los sistemas de sentimientos modernos) y las fuentes de datos disponibles para la validación geográfica que a menudo se basan en el bienestar evaluativo. -ser. Este desajuste entre el constructo de medición y validación del bienestar se alivia en cierta medida por el hecho de que, en particular en la agregación geográfica, el bienestar afectivo y evaluativo se interrelacionan de moderada a alta.
Como discutiremos en este capítulo, los avances metodológicos recientes han dado como resultado una alta validez convergente también para el bienestar evaluativo pronosticado por las redes sociales (p. ej., véase la Fig. 5.5 ). Si los datos de las redes sociales se agregan primero a nivel de persona (antes de la agregación geográfica) y se entrena específicamente un modelo de lenguaje para derivar la satisfacción con la vida, las estimaciones muestran una mayor validez convergente con la satisfacción con la vida informada por la encuesta que con el afecto (felicidad) informado por la encuesta. . Por lo tanto, los componentes específicos del bienestar deberían idealmente medirse con modelos de lenguaje personalizados, lo que se puede hacer en base a datos de capacitación recopilados por separado. [24]
Figura 5.1: Medición poblacional escalable del bienestar a través de Twitter
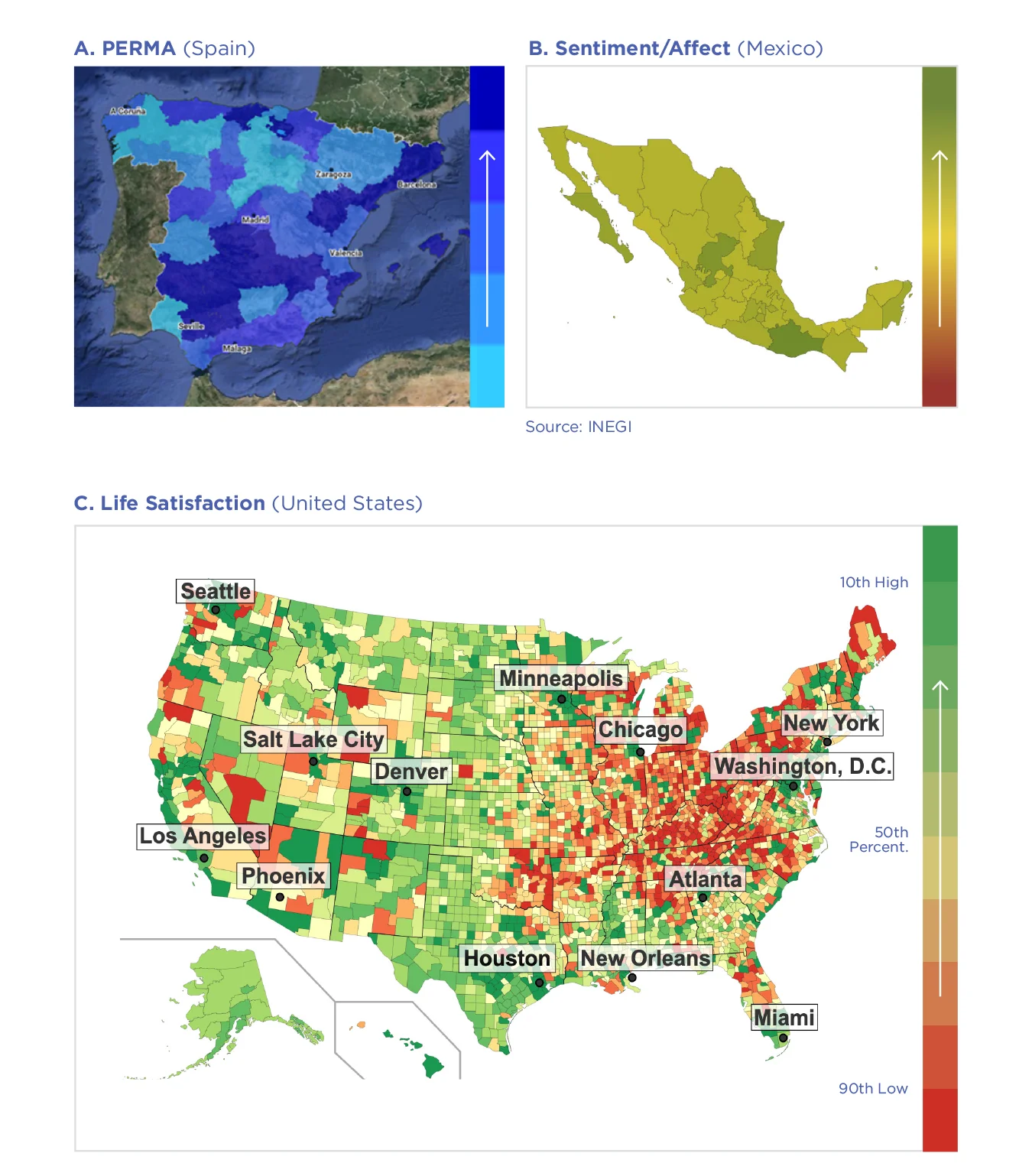
Cifra. 5.1 muestra ejemplos internacionales en los que se predijeron diferentes componentes de bienestar a través del lenguaje de Twitter, incluido un mapa de bienestar “PERMA” para España que estima los niveles de emociones positivas, compromiso, relaciones, significado y logros, [25] un mapa basado en sentimientos mapa para México, [26] y un mapa de satisfacción con la vida para los EE. UU. [27]
Figura 5.1: Medida poblacional escalable del bienestar a través de Twitter. A: en España, con base en datos de Twitter de 2015 y modelos de lenguaje de bienestar en español que miden PERMA: emociones positivas, compromiso, relaciones, significado y logros con base en diccionarios personalizados, [28] B: en México, con base en modelos de sentimiento en español y proporcionado por un tablero web a través del Instituto Nacional de Estadística y Geografía de México , [29] y C: para los condados de EE. UU., [30] con interpolación de los condados faltantes proporcionados a través de un modelo de proceso gaussiano que utiliza la similitud demográfica y socioeconómica entre los condados. [31]
Las ventajas de las redes sociales: medición “retroactiva” y flexibilidad multiconstrucción
Los datos de las redes sociales tienen la ventaja de estar constantemente “almacenados”, es decir, almacenados discretamente. Esto significa que se puede acceder a él en un momento posterior y analizarlo retroactivamente. Esta recopilación de datos la realizan, como mínimo, las propias empresas de tecnología (como Twitter, Facebook y Reddit), pero los investigadores también pueden acceder a los datos, por ejemplo, a través de la interfaz de programación de aplicaciones académicas de Twitter (una interfaz automática). Esto significa que cuando ocurren eventos impredecibles (por ejemplo, desastres naturales o un evento de desempleo masivo), no solo es posible observar el impacto posterior al evento en el bienestar de un área geográfica específica sino, en principio, las líneas base de eventos retroactivamente para comparar. Si bien también pueden ser posibles comparaciones similares con datos de encuestas de bienestar existentes,satisfacción con la vida ).
El lenguaje es una forma natural para que las personas describan estados mentales, experiencias y deseos complejos.
En segundo lugar, el lenguaje es una forma natural para que las personas describan estados mentales, experiencias y deseos complejos. En consecuencia, la riqueza de los datos del lenguaje de las redes sociales permite la estimación retrospectiva de diferentes constructos, que se extienden más allá del conjunto de dimensiones de bienestar medidas actualmente, como las emociones positivas y la satisfacción con la vida. Por ejemplo, un modelo de medición basado en el lenguaje (entrenado hoy) para estimar la nueva construcción de “equilibrio y armonía” [32]se puede aplicar retroactivamente a los datos históricos de Twitter para cuantificar la expresión de este constructo en los últimos años. De esta manera, las estimaciones basadas en las redes sociales pueden complementar las recopilaciones de datos de encuestas existentes con el potencial de una cobertura flexible de construcciones adicionales para regiones específicas para períodos presentes y pasados. Esta flexibilidad inherente a la medición del bienestar basada en las redes sociales puede ser particularmente deseable a medida que el campo se mueve para considerar otras conceptualizaciones del bienestar más allá de los conceptos occidentales típicos (como la satisfacción con la vida), ya que estos también pueden ser flexiblemente derivado del lenguaje de las redes sociales. [33]
Las fuentes de datos como Twitter y Reddit tienen diferentes sesgos de selección y presentación y generalmente son ruidosas, con patrones cambiantes de uso del lenguaje a lo largo del tiempo.
La evolución de los análisis de bienestar en las redes sociales
El análisis de los datos de las redes sociales no está exento de desafíos. Las fuentes de datos como Twitter y Reddit tienen diferentes sesgos de selección y presentación y generalmente son ruidosas, con patrones cambiantes de uso del lenguaje a lo largo del tiempo. Como fuentes de datos, son relativamente nuevos para la comunidad científica. Para darse cuenta del potencial de la estimación de las construcciones de bienestar basadas en las redes sociales, es esencial analizar los datos de las redes sociales de una manera que maximice la relación señal-ruido. A pesar de que la literatura es relativamente incipiente, los métodos para analizar el lenguaje de las redes sociales para evaluar los rasgos y estados psicológicos están madurando. Hasta la fecha, hemos visto una evolución a lo largo de dos ejes principales de desarrollo: estrategias de recopilación/agregación de datos y modelos de lenguaje (consulte la Tabla 5.1 para obtener una descripción general de alto nivel).
| Métodos de muestreo y agregación de datos | Modelos de lenguaje |
|---|---|
| Gen 1: Agregación de publicaciones aleatorias | Nivel 1: Vocabulario cerrado (diccionarios seleccionados o basados en anotaciones de palabras) |
| Gen 2: Agregación entre personas | Nivel 2: Vocabulario abierto (IA basada en datos, predicciones de ML) |
| Gen 3: Agregación a través de un diseño de cohorte longitudinal | Nivel 3: Representaciones contextuales (grandes modelos de lenguaje previamente entrenados) |
nota _ AI = Inteligencia Artificial, ML = Aprendizaje Automático. Consulte la Tabla 5.2 para obtener más información sobre las tres generaciones de métodos de agregación de datos y la Tabla 5.3 para los tres niveles de modelos de lenguaje.
El primer eje de desarrollo ( estrategias de recopilación y agregación de datos ) se puede clasificar en tres generaciones que han producido aumentos graduales en la precisión de las predicciones y reducciones en el impacto de las fuentes de error, como los bots (detallados en la Tabla 2):
Gen 1: Agregación de publicaciones aleatorias (es decir, tratar las publicaciones de cada comunidad como “bolsas de publicaciones” no estructuradas).
Gen 2: Muestreo a nivel de persona y agregación de publicaciones, con el potencial de corregir sesgos de muestra (es decir, agregación entre personas).
Gen 3: Agregación a través de un diseño de cohorte longitudinal (es decir, creación de cohortes digitales en las que se sigue a los usuarios a lo largo del tiempo y las tendencias temporales se describen mediante la extrapolación de los cambios observados en los usuarios).
El segundo eje de desarrollo, modelos de lenguaje , describe cómo se analiza el lenguaje; es decir, cómo se derivan del lenguaje las estimaciones numéricas del bienestar. Argumentamos que estos han avanzado paso a paso, a lo que nos referimos como Niveles para fines organizacionales. Estas iteraciones mejoran la precisión con la que se asigna la distribución del uso del lenguaje a las estimaciones del bienestar (consulte la Tabla 3 para obtener una descripción detallada). Los niveles han avanzado desde métodos de vocabulario cerrado (basados en diccionarios) hasta métodos de aprendizaje automático y modelos de lenguaje extenso que incorporan todo el vocabulario. [34] Proponemos los siguientes tres niveles de etapas de desarrollo en modelos de lenguaje:
Nivel 1: Los enfoques de vocabulario cerrado utilizan conteos de frecuencia de palabras que se derivan de diccionarios definidos o de fuentes colectivas (basados en anotaciones), como por ejemplo, para sentimientos (p. ej., ANEW [35]) o categorías de palabras (p. ej., Consulta lingüística y Conteo de palabras). 2015 o 2022). [36]
Nivel 2: Los enfoques de vocabulario abierto utilizan predicciones de aprendizaje automático basadas en datos. Aquí, las palabras, frases o características del tema (p. ej., LDA) [37] se extraen y utilizan como entradas en modelos de aprendizaje automático supervisado, en los que los patrones de lenguaje se detectan automáticamente.
Nivel 3: Los enfoques de incrustación de palabras contextuales usan modelos de lenguaje grandes para representar palabras en su contexto; así, por ejemplo, “abajo” se representa de manera diferente en “ Me siento deprimido ” en comparación con “ Estoy deprimido”. Los modelos preentrenados incluyen BERT, [38] RoBERTa, [39] y BLOOM. [40]
Las generaciones y los niveles aumentan la complejidad con la que se procesan y analizan los datos y, por lo general, también, como detallamos a continuación, la precisión de las estimaciones de bienestar resultantes.
Las precisiones de predicción fuera de la muestra de los modelos de aprendizaje automático demuestran empíricamente que estos sesgos pueden manejarse.
Abordar los sesgos de las redes sociales
Las muestras de lenguaje de las redes sociales son ruidosas y pueden sufrir una variedad de sesgos, y las audiencias desconocidas a veces descartan la medición basada en las redes sociales por estos motivos. Los discutimos en relación con los sesgos de selección, muestreo y presentación .
Los sesgos de selección incluyen sesgos demográficos y de muestreo. Los sesgos demográficos , es decir, que las personas en las plataformas de redes sociales no son representativas de la población en general (consulte la Figura 5.2), [41] revelan preocupaciones de que las evaluaciones no se generalizan a una población con otra estructura demográfica. En general, las plataformas de redes sociales difieren de la población general; Los usuarios de Twitter, por ejemplo, tienden a ser más jóvenes y más educados que la población general de EE. UU. [42] Estos sesgos pueden abordarse de varias maneras; por ejemplo, los sesgos demográficos pueden abordarse aplicando ponderaciones posteriores a la estratificación para que coincidan mejor con la población objetivo en variables demográficas importantes. [43]
Los sesgos de muestreo implican preocupaciones de que unas pocas cuentas generan la mayor parte del contenido, [44] incluidos los bots sociales de superpublicación y las cuentas de organizaciones, que a su vez tienen una influencia desproporcionada en las estimaciones. Las técnicas sólidas para abordar estos sesgos de muestreo, como la agregación a nivel de persona, eliminan en gran medida el impacto desproporcionado de las cuentas de superpublicación. [45] También es posible identificar y eliminar los bots sociales con gran precisión (consulte el recuadro 5.1 ). [46]
Los sesgos de presentación incluyen la autopresentación (o gestión de impresiones ) y los sesgos de deseabilidad social, e implican preocupaciones de que las personas “ponen una cara” y solo presentan aspectos curados de sí mismos y de su vida para evocar una percepción positiva de sí mismos. [47] Sin embargo, los estudios empíricos indican que estos sesgos tienen un efecto limitado en los algoritmos de aprendizaje automático que tienen en cuenta todo el vocabulario (en lugar de simplemente contar palabras clave). Como se analiza a continuación, las estimaciones basadas en el aprendizaje automático ( Nivel 2 ) convergen de manera confiable con evaluaciones que no son de redes sociales, como las respuestas de encuestas agregadas (convergencia fuera de la muestra por encima de Pearson r de .60).[48] Por lo tanto, estas estimaciones proporcionan un límite superior empírico en la medida en que estos sesgos pueden influir en los algoritmos de aprendizaje automático.
En conjunto, a pesar de la preocupación prima facie generalizada sobre los sesgos de selección, muestreo y presentación, las precisiones de predicción fuera de la muestra de los modelos de aprendizaje automático demuestran empíricamente que estos sesgos se pueden manejar [49], como analizamos a continuación .
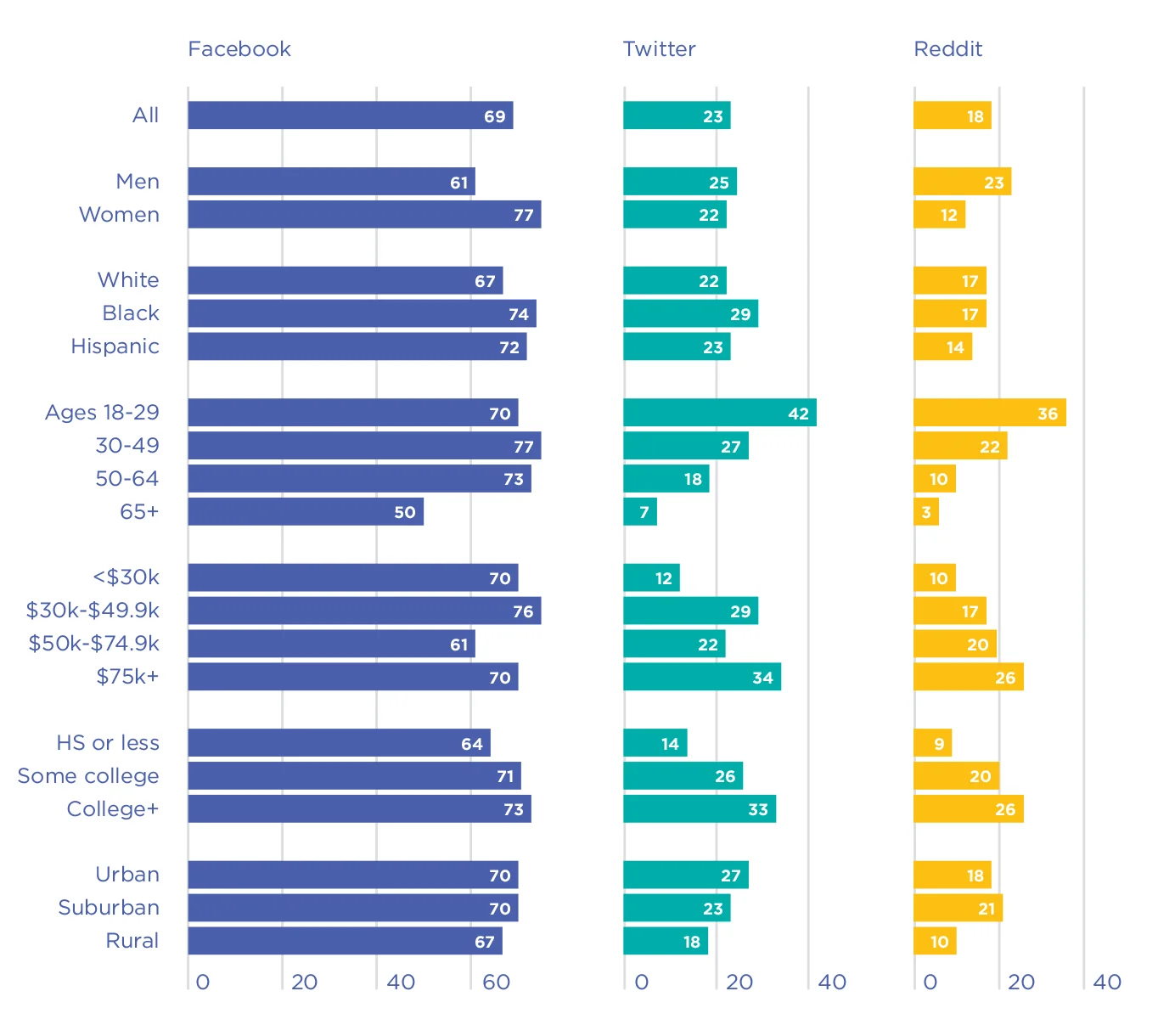
Figura 5.2. Porcentaje de adultos que usan cada plataforma de redes sociales dentro de cada grupo demográfico en los EE. UU. [50]
| Método de muestreo y agregación de datos | Ejemplos típicos | Ventajas | Desventajas | |
|---|---|---|---|---|
| Generación 1: pasado (2010–) | Agregación de (pseudo) muestreo aleatorio de publicaciones | Agregue publicaciones geográficamente, extraiga características del idioma, use el aprendizaje automático para predecir resultados (transversalmente) | Relativamente fácil de implementar (p. ej., API de Twitter aleatoria + modelo de sentimiento). | Sufre el impacto desproporcionado de las cuentas de superpublicación (por ejemplo, bots). Para aplicaciones longitudinales: Una nueva muestra aleatoria de individuos en cada periodo temporal. |
| Generación 2: Presente (2018–) | Agregación y muestreo a nivel de persona (algunos con corrección de sesgo de muestra) | Agregación a nivel de persona [51] y estratificación posterior para ajustar la muestra hacia una muestra más representativa (por ejemplo, el censo de EE. UU.). [52] | Aborda el impacto de las superpublicaciones de los usuarios de las redes sociales (p. ej., bots). Con posestratificación: datos demográficos de muestra conocidos y corrección de sesgos de muestra. Aumenta la fiabilidad de la medición y la validez externa. | Para aplicaciones longitudinales: Una nueva muestra aleatoria de individuos en cada periodo temporal. |
| Gen 3: futuro cercano | Muestreo de cohorte digital (seguimiento de las mismas personas a lo largo del tiempo) | Evaluaciones robustas de salud mental en tiempo y espacio a través de análisis de lenguaje de redes sociales. [53] | Todo Gen 2 + Aumenta la estabilidad temporal de las estimaciones.La resolución definida en el tiempo y el espacio (p. ej., mes-condado) permite diseños cuasi-experimentales | Mayor complejidad en la recopilación de datos de series temporales a nivel de persona (seguridad, almacenamiento de datos).Es difícil recopilar suficientes datos para resoluciones espaciotemporales más altas (p. ej., condado-día). |
| Enfoque de análisis del lenguaje | prototípico | Ejemplos | Ventajas | Desventajas | |
|---|---|---|---|---|---|
| Nivel 1 | Diccionarios de vocabulario cerrado o colaborativos | Los recuentos de frecuencia de palabras se derivan en función de diccionarios definidos, como opiniones o categorías de palabras. | LIWC LabMT ANEW ANEW de Warriner | Interfaz de software sencilla y fácil de usar (LIWC).Bueno para comprender los mismos patrones en el uso del lenguaje en todos los estudios (p. ej., uso de pronombres). | Los enfoques de arriba hacia abajo generalmente se basan en categorías codificadas a mano definidas por los investigadores.La mayoría de las palabras tienen múltiples sentidos de palabras, que los evaluadores humanos no anticipan; por ejemplo, “Me siento muy bien” y “Estoy muy triste”. [54]Los diccionarios sin pesos (como LIWC) pueden captar de manera insuficiente las diferencias de valencia entre las palabras (p. ej., bueno frente a fantástico ). |
| Nivel 2 | Predicciones de IA o ML basadas en datos y de vocabulario abierto | Las palabras, las frases o las características de los temas se extraen, se filtran (en función de la [co]ocurrencia) y se utilizan como entradas para los modelos de aprendizaje automático. | Palabras Frases LDA modelos de temas LSA | Los métodos basados en datos, ascendentes y no supervisados se basan en patrones estadísticos de uso de palabras (en lugar de evaluaciones subjetivas).Las palabras se representan con alta precisión (no solo binaria).Los temas pueden aparecer de forma natural y proporcionar un manejo básico de las ambigüedades del sentido de las palabras. | Las representaciones numéricas no tienen en cuenta el contexto.Las unidades de análisis basadas en datos (como los temas) pueden ser difíciles de comparar entre estudios. |
| Nivel 3 | Representaciones contextuales, grandes modelos de lenguaje | Incrustaciones de palabras contextualizadas a través de la autoatención. | Modelos de transformadores: BERT RoBERTa BLOOM | Produce representaciones de texto de última generación. Toma en cuenta el contexto. Elimina la ambigüedad del significado de las palabras.Aprovecha grandes corporaciones de Internet. | Computacionalmente intensivo en recursos (necesita GPU).Sesgos semánticos : los modelos de transformadores obtienen sus representaciones de texto a partir de la estructura del conjunto de datos de entrenamiento (corpus) que se utiliza; esto implica el riesgo de reproducir sesgos existentes en el corpus (Nb: existen métodos para examinar y reducir estos sesgos). |
IA = Inteligencia Artificial; ML = Aprendizaje automático; LabMT = Lista de palabras de Evaluación del lenguaje por Mechanical Turk (LabMT) (Dodds et al., 2015); ANEW = Normas afectivas para palabras en inglés (Bradley & Lang, 1999); LIWC = Investigación lingüística y recuento de palabras (Boyd et al., 2022; Pennebaker et al., 2001); ANEW de Warriner: una lista con 13915 palabras (Warriner et al., 2013). LSA = Análisis Semántico Latente (Deerwester et al., 1990); LDA = (Blei et al., 2003); BERT = Representaciones de codificador bidireccional de transformadores (Devlin et al., 2019); RoBERTa = Representaciones de codificador bidireccional robustamente optimizadas del enfoque de preentrenamiento de transformadores (Y. Liu et al., 2019); BLOOM = BigScience Gran modelo de lenguaje multilingüe de acceso abierto y ciencia abierta. GPU = Unidades de procesamiento gráfico (tarjetas gráficas)
Recuadro 5.1: Efectos de los bots en la medición de las redes sociales
En las redes sociales, los bots son cuentas que generan contenido automáticamente, por ejemplo, con fines de marketing, mensajes políticos y desinformación (noticias falsas). Estimaciones recientes sugieren que entre el 8 y el 18 % de las cuentas de Twitter son bots [55] y que estas cuentas tienden a permanecer activas entre 6 meses y 2,5 años. [56] Históricamente, los bots se usaban para difundir contenido no solicitado o malware, inflar el número de seguidores y generar contenido a través de retweets. [57] Más recientemente, se descubrió que los bots juegan un papel importante en la difusión de información de fuentes de baja credibilidad; por ejemplo, dirigirse a personas con muchos seguidores a través de menciones y respuestas. [58]Los bots más sofisticados, a saber, los spambots sociales, ahora interactúan e imitan a los humanos mientras evaden las técnicas de detección estándar. [59] Existe la preocupación de que la creciente sofisticación de los modelos de lenguaje generativo (como GPT) pueda conducir a una nueva generación de bots que se vuelven cada vez más difíciles de distinguir de los usuarios humanos.
Cómo impactan los bots en la medición del bienestar usando las redes sociales
El contenido generado por los bots no debería, por supuesto, influir en la evaluación del bienestar humano. Si bien los bots redactan menos tweets originales que los humanos, se ha demostrado que expresan sentimientos y patrones de felicidad que difieren de la población humana. [60] La aplicación de la técnica de agregación a nivel de persona ( Gen 2 ) limita efectivamente el problema de los bots, ya que todo su contenido generado se agrega en un solo “punto de datos”. Las heurísticas adicionales, como la eliminación de retweets, deberían minimizar el problema de los bots al eliminar el contenido de los bots de retweets. Finalmente, el trabajo ha demostrado que los bots exhiben características similares a las de los humanos, como la edad y el género estimados. [61]Por lo tanto, la aplicación de técnicas de posestratificación reduce el peso de los bots en el proceso de agregación, ya que las cuentas con datos demográficos promedio estarán sobrerrepresentadas en la muestra. Con los modernos sistemas de aprendizaje automático, los bots se pueden detectar y eliminar. [62]
Generaciones de métodos de muestreo y agregación de datos
La siguiente revisión metodológica está organizada por generaciones de métodos de agregación de datos ( Gen 1, 2 y 3 ), que observamos como la opción metodológica principal cuando se trabaja con datos de redes sociales. Pero dentro de estas generaciones, la distinción más importante en términos de confiabilidad es la transición de los enfoques de Nivel 1 basados en diccionarios (nivel de palabra) a aquellos que dependen del aprendizaje automático para entrenar modelos de lenguaje ( Nivel 2 ) y más allá.

Gen 1: Muestras aleatorias de publicaciones en redes sociales
Inicialmente, un ejemplo prototípico de análisis del lenguaje de las redes sociales para evaluaciones de población implicaba simplemente agregar publicaciones geográfica o temporalmente, por ejemplo, una muestra aleatoria de tweets de EE. UU. para un día determinado. En este enfoque, la agregación de lenguaje se lleva a cabo en base a una muestra ingenua de publicaciones, sin tener en cuenta a las personas que las escriben (ver Fig. 5.3 ).
El análisis del lenguaje se realizó típicamente utilizando un enfoque de vocabulario cerrado de Nivel 1 ; por ejemplo, el diccionario de emociones positivas LIWC se aplicó al conteo de palabras. Posteriormente, se han utilizado enfoques de nivel 2 con muestras aleatorias de tuits, como enfoques de vocabulario abierto basados en aprendizaje automático; esto incluye el uso de sistemas de opinión modernos o la predicción de los resultados de la encuesta de bienestar de Gallup a nivel de condado directamente utilizando el aprendizaje automático transversalmente.
Figura 5.3. Ejemplo de canalización de Twitter Gen 1 : una colección pseudoaleatoria de tweets se agrega directamente a nivel de condado.
Gen 1 con métodos basados en anotaciones/diccionario de nivel 1
En los EE. UU. En 2010, Kramer analizó las publicaciones de 100 millones de usuarios de Facebook utilizando recuentos de palabras basados en los diccionarios de emociones positivas y negativas ( Gen 1, Level 1 ) de Linguistic Inquiry and Word Count (LIWC ) de 2007. [63] El índice de bienestar se creó como la diferencia entre las frecuencias relativas estandarizadas (puntuación z) de los diccionarios de emociones positivas y negativas LIWC 2007. Sin embargo, el índice de bienestar de los usuarios solo se correlacionó débilmente con las respuestas de los usuarios a la escala de Satisfacción con la vida, [64] un hallazgo que se replicó en un trabajo posterior [65] en una muestra de más de 24.000 usuarios de Facebook.
Sorprendentemente, las puntuaciones SWLS y las frecuencias del diccionario de emociones negativas se correlacionaron positivamente entre días ( r = 0,13), semanas ( r = 0,37) y meses ( r = 0,72), mientras que el diccionario de emociones positivas no mostró una correlación significativa. Esto presentó algunas pruebas iniciales de que el uso de métodos de vocabulario cerrado de Nivel 1 (aquí en forma de diccionarios LIWC 2007) puede producir resultados poco fiables e inverosímiles.
Pasando de los diccionarios LIWC a las anotaciones de palabras sueltas de colaboración abierta, el proyecto Hedonometer (en curso, https://hedonometer.org/ , Fig. 5.4A ) [66] tiene como objetivo evaluar la felicidad de los estadounidenses a gran escala mediante el análisis de expresiones lingüísticas de Twitter ( Gen 1, Nivel 1 ; Fig. 5.4B) . [67] A las palabras se les asigna una puntuación de felicidad (que va de 1 = triste a 9 = feliz) de un diccionario colaborativo de 10 000 palabras comunes llamado LabMT (“Evaluación del lenguaje por Mechanical Turk”). [68] El diccionario LabMT se ha utilizado para mostrar variaciones espaciales en la felicidad en escalas de tiempo que van desde horas hasta años [69]– y geoespacialmente a través de estados, ciudades, [70] y vecindarios [71] basados en feeds aleatorios de tweets.
Sin embargo, aplicar el diccionario LabMT al lenguaje de Twitter agregado geográficamente puede generar resultados poco confiables e inverosímiles. Algunos investigadores examinaron evaluaciones de bienestar de alta resolución espacial de vecindarios en San Diego usando el diccionario LabMT [72] (ver Fig. 5.4C ). Sin embargo, las estimaciones se asociaron negativamente con la salud mental autoinformada a nivel de distritos censales (y no en absoluto cuando se controlaron los factores del vecindario, como las variables demográficas). Otros investigadores encontraron resultados inverosímiles adicionales; utilizando datos de Twitter agregados de persona a condado [73] ( Gen 2), se ha observado que las estimaciones de LabMT de 1,208 condados de EE. UU. y la satisfacción con la vida del condado informada por Gallup tienen una anticorrelación, que se analiza con más detalle a continuación (consulte la Fig. 5.5 ).
Fuera de los EE. UU. Hasta la fecha, los enfoques Gen 1 se han aplicado ampliamente, en diferentes países, con diferentes idiomas. En China, se ha utilizado para evaluar emociones positivas y negativas (p. ej., alegría, amor, ira y ansiedad) a nivel nacional a lo largo de días, meses y años utilizando publicaciones de blogs (63 505 blogs de Sina.com por 316 blogueros ) de 2008 a 2013 (Gen 1, Nivel 1). [74] Para este propósito, se utilizó un diccionario centrado en el bienestar subjetivo para chino, Ren-CECps-SWB 2.0, que abarca 17 961 entradas. La validación implicó examinar la validez aparente de la serie temporal resultante comparando los máximos y mínimos del índice con eventos nacionales en China.
En Turquía, se aplicó el análisis de sentimientos a 35 millones de tuits publicados entre 2013 y 2014 por más de 20 000 personas (Gen 1, Nivel 1). [75] Se analizaron más de 35 millones de tuits utilizando el diccionario de sentimientos turco “Zemberek”. [76] Sin embargo, el índice no se correlacionó significativamente con el bienestar de los resultados de la encuesta provincial del Instituto de Estadística de Turquía (ver material complementario para estudios internacionales adicionales).
En general, la aplicación de enfoques basados en diccionarios ( Nivel 1 ) a muestras aleatorias de Twitter ( Gen 1 ) ha sido la opción más común entre los grupos de investigación de todo el mundo, pero los resultados generalmente no han sido validados en la literatura más allá de la publicación de series temporales de mapas. .
Figura 5.4. El hedonómetro mide la felicidad mediante el análisis de palabras clave de feeds de Twitter aleatorios, a lo largo de A) tiempo basado en un feed de Twitter aleatorio del 10 % , [77] B) estados de EE. UU. [78] y C) distritos censales. [79]
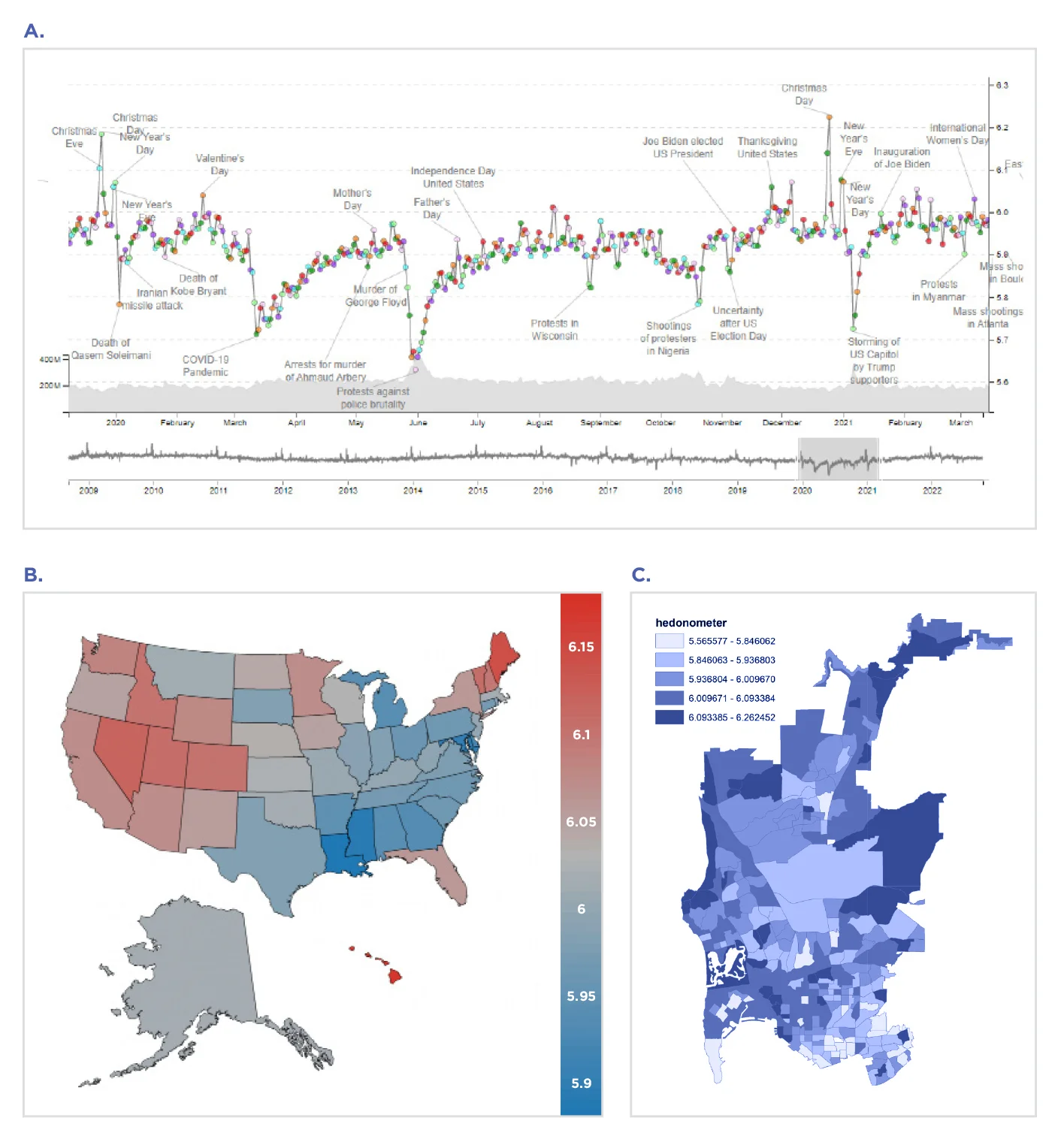
Figura 5.5. Uso de diferentes tipos (“niveles”) de modelos de lenguaje en la predicción de la satisfacción con la vida, la felicidad y la tristeza a nivel de condado informados por Gallup (usando un conjunto de datos de Twitter del 10% Gen 2: nivel de usuario agregado 2009-2015) en 1,208 EE. UU. condados Las estimaciones basadas en el nivel 2 , como las basadas en Swiss Chocolate, un moderno sistema Sentiment derivado del aprendizaje automático, arrojan resultados consistentes. [80] Sin embargo, las estimaciones derivadas de la Investigación lingüística y recuento de palabras de nivel 1 (LIWC 2015) Emoción positivas o el diccionario Language Assessment by Mechanical Turk (labMT) basado en anotaciones a nivel de palabra tienen una correlación negativa con la medida de satisfacción con la vida informada por Gallup a nivel de condado. [81]
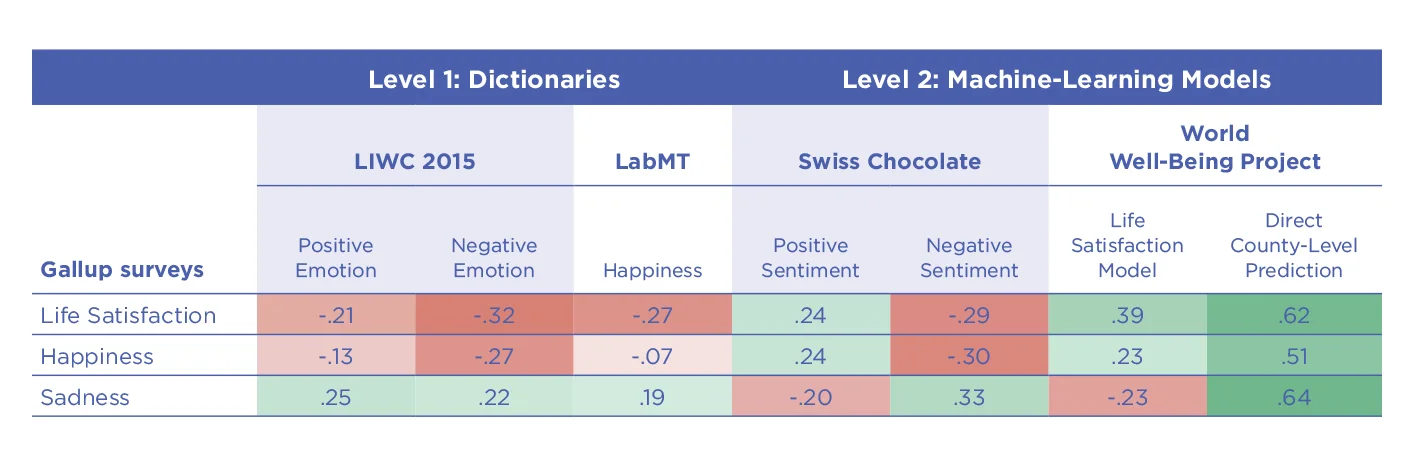
Gen 1 usando métodos de aprendizaje automático de nivel 2
Se han aplicado enfoques de análisis de lenguaje más avanzados, incluido el Nivel 2 (aprendizaje automático) y el Nivel 3 (modelos de lenguaje grande), a feeds aleatorios de Twitter. Por ejemplo, se usaron tweets aleatorios agregados a nivel de condado de EE. UU. para predecir la satisfacción con la vida ( r = 0,31; 1293 condados) [82] y las tasas de mortalidad por enfermedades cardíacas ( r = 0,42, IC del 95 % = [0,38, 0,45 ]; 1347 condados; Gen 1, Nivel 1–2); [83] en estos estudios, se aplicaron modelos de aprendizaje automático a palabras, frases y temas de vocabulario abierto (ver material complementario para estimaciones de redes sociales con una resolución espacial por debajo del nivel del condado).
Además, los investigadores utilizaron datos de texto de foros de discusión en un gran periódico en línea (Der Standard) y el lenguaje de Twitter para capturar la dinámica temporal de los estados de ánimo de las personas. [84] Se pidió a los lectores del periódico (N = 268 128 respuestas) que calificaran su estado de ánimo del día anterior (formato de respuesta: “bueno”, “algo bueno”, “algo malo” o “malo”), que se agregaron a nivel nacional (Gen 1, Nivel 1 y 3). [85] Los análisis lingüísticos basados en una combinación de Nivel 1 (adaptación alemana de LIWC 2001) [86] y Nivel 3 (Sentimiento alemán, basado en incrustaciones contextuales, BERT) arrojaron un alto acuerdo a lo largo de los días con el Der Standard agregado.autoinformes durante 20 días ( r =.93 [.82, .97]). De manera similar, en una réplica registrada previamente, las estimaciones del lenguaje de Twitter (más de 500 000 tuits de usuarios austriacos de Twitter) se correlacionaron con el mismo estado de ánimo autoinformado agregado diariamente en r = .63 (.26, .84).
Gen 1: Agregación aleatoria de publicaciones – Resumen
Agregar tweets aleatorios directamente en estimaciones geográficas es intuitivamente sencillo y relativamente fácil de implementar; y se ha utilizado durante más de una década (2010+). Sin embargo, es susceptible a muchos tipos de ruido, como cambios en la composición de la muestra a lo largo del tiempo, patrones de publicación inconsistentes y el impacto desproporcionado de las cuentas de superpublicación (p. ej., bots, consulte el cuadro 5.1), lo que puede disminuir la precisión de la medición .
Gen 2: Muestreo a nivel de persona de feeds de Twitter
La precisión de las mediciones se puede aumentar sustancialmente mejorando los métodos de muestreo y agregación, especialmente al agregar los tweets primero al nivel de la persona. El muestreo a nivel de persona aborda el impacto desproporcionado que puede tener una pequeña cantidad de cuentas muy activas en las estimaciones geográficas. Además del muestreo a nivel de persona, las características demográficas de la persona (como la edad y el sexo) se pueden estimar a través del lenguaje y, sobre esta base, se pueden determinar las ponderaciones posteriores a la estratificación, que es similar a los métodos utilizados en las encuestas telefónicas representativas (ver Fig. 5.6 para un esquema de método). Este enfoque muestra notables mejoras en la precisión (ver Fig. 5.7 ).
Gen 2 con métodos basados en anotaciones/diccionario de nivel 1
Uno de los primeros ejemplos de Gen 2 evaluó la precisión predictiva del lenguaje a nivel comunitario (medido con diccionarios de Nivel 1 como LIWC) en 27 resultados relacionados con la salud, como la obesidad y los días mentalmente insalubres. [87] Es importante destacar que este trabajo evaluó varios métodos de agregación, incluidas muestras aleatorias de publicaciones ( métodos Gen 1 ) y un enfoque centrado en la persona ( Gen 2 ). Esta agregación centrada en la persona superó significativamente (en términos de precisión predictiva fuera de la muestra) los métodos de agregación Gen 1 con una precisión ( r promedio de Pearson en los 27 resultados de salud) de .59 para Gen 1 frente a .63 para Gen 2.
Gen 2 utilizando métodos de aprendizaje automático de nivel 2
Agregación a nivel de usuario. Algunos investigadores han propuesto un enfoque centrado en la persona de Nivel 2, que primero mide las frecuencias de las palabras a nivel de persona y luego promedia esas frecuencias a nivel de condado, lo que arroja efectivamente un promedio de idioma del condado entre los usuarios . [88] Además, a través de análisis de sensibilidad, este trabajo calibró umbrales mínimos tanto en la cantidad de tweets necesarios por persona (30 tweets o más) como en la cantidad de personas necesarias por condado para producir estimaciones lingüísticas estables a nivel de condado (al menos 100 personas). ), que son técnicas estándar en el análisis geoespacial. [89] En varias tareas de predicción, incluida la estimación de la satisfacción con la vida, Gen 2 superó a Gen 1enfoques, como se ve en la Fig. 5.7 . Trabajos adicionales han demostrado que las estimaciones del idioma Gen 2 muestran cómo la validez externa (p. ej., las estimaciones del idioma de la personalidad a nivel de condado se correlacionan con las medidas basadas en encuestas) y son sólidas para las autocorrelaciones espaciales (es decir, las correlaciones del condado no son un artefacto de, ni dependen de , la naturaleza espacial física de los datos). [90]
El enfoque centrado en la persona también se ha ampliado para considerar quién usa las redes sociales en relación con su comunidad respectiva.
Corrección por representatividad. Una limitación común con el trabajo en el texto de las redes sociales es el sesgo de selección: la muestra de las redes sociales no es representativa de la población de la que nos gustaría inferir información adicional. El enfoque centrado en la persona también se ha ampliado para considerar quién usa las redes sociales en relación con su comunidad respectiva. Cuando se utilizan enfoques de aprendizaje automático de última generación, se pueden estimar los datos sociodemográficos (como la edad, el género, los ingresos y la educación) de cada usuario de Twitter a partir del idioma de sus redes sociales, lo que permite medir la composición sociodemográfica de los usuarios. muestra. [91]La comparación de la distribución sociodemográfica de la muestra con la distribución de la población da una medida del grado de sobrepresentación o subpresentación de los usuarios de Twitter. Esta comparación se puede utilizar para volver a ponderar la estimación del idioma de cada usuario en el proceso de agregación de condados utilizando técnicas de posestratificación comúnmente utilizadas en demografía y salud pública. [92] La aplicación de estas técnicas de reponderación al vocabulario cerrado (p. ej., diccionarios LIWC, Nivel 1 ) [93] y funciones de vocabulario abierto (p. ej., temas LDA, Nivel 2 ) [94] aumentó la precisión predictiva por encima de los métodos Gen 2 anteriores ( ver Fig. 5.7, arriba ).
Promedio entre géneros. En el capítulo 4 del Informe mundial de la felicidad 2022 (WHR 2022) , los autores [95] informan los resultados de un estudio que evaluó las emociones, incluidas la felicidad/alegría/afecto positivo , la tristeza y el miedo/ansiedad/miedo durante dos años en el Reino Unido. Trabajos anteriores han encontrado que la demografía como el género y la edad afectan los patrones en el uso del lenguaje más que la personalidad y, por lo tanto, son variables de confusión importantes a considerar al analizar el uso del lenguaje. [96] Los autores en el capítulo 4 de WHR 2022 , [97] derivaron por separado (y luego combinaron) estimaciones específicas de género a partir de datos de Twitter utilizando tanto Nivel 1(LIWC) y enfoques de Nivel 3 (incrustaciones de palabras contextualizadas; RoBERTa). [98] La alegría estimada en Twitter se correlacionó en r = .55 [.27, .75] con la felicidad reportada por YouGov durante ocho meses desde noviembre de 2020 hasta junio de 2021.
La agregación a nivel de persona puede reducir el peso de las cuentas altamente activas y minimizar las influencias de los bots.
Agregación a nivel de persona Gen 2 – Resumen
Los métodos Gen 2 a nivel de persona se basan en una década de investigación utilizando Gen 1Métodos de agregación de feeds aleatorios basados en la intuición (en retrospectiva obvia) de que las comunidades son grupos de personas que producen lenguaje en lugar de una variedad aleatoria de tweets. Esta intuición tiene varias ventajas metodológicas. En primer lugar, la agregación a nivel de persona trata a cada persona como una sola observación, lo que puede reducir el peso de las cuentas muy activas y minimizar las influencias de los bots o las organizaciones. En segundo lugar, allana el camino para abordar los sesgos de selección, ya que ahora se puede ponderar a cada persona de la muestra según su representatividad en la población. Además, estos métodos se pueden aplicar a cualquier dato digital. Finalmente, estos métodos reflejan más de cerca los enfoques metodológicos en demografía y salud pública que encuestan a las personasy sentar las bases para el seguimiento de cohortes digitales a lo largo del tiempo ( Gen 3 ).
Figura 5.6 . Ejemplo de canalización de Twitter Gen 2 : agregación y posestratificación a nivel de persona.
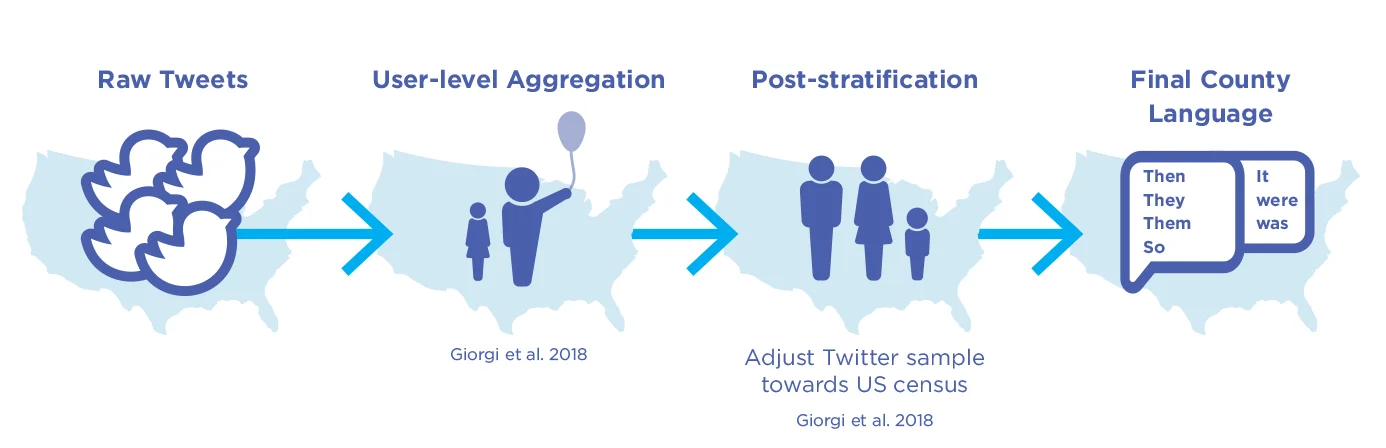
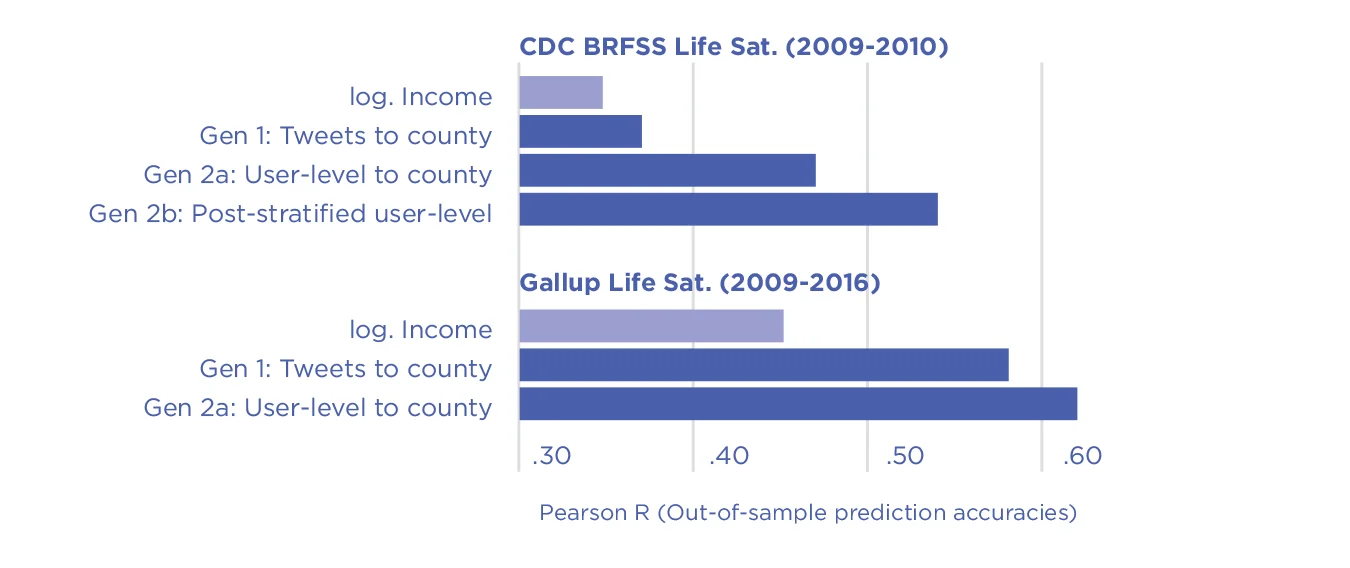
Figura 5.7 . Desempeño de predicción transversal validado a nivel de condado basado en Twitter usando ( Gen 1 ) agregación directa de tweets a condados, Gen 2a : agregación a nivel de persona antes de la agregación de condado, y Gen 2b : estratificación posterior sólida basada en edad, género , ingresos y educación. [99] Los valores de satisfacción con la vida se obtuvieron de: Top, estimaciones del Sistema de Vigilancia de Factores de Riesgo del Comportamiento (BRFSS) de los CDC (2009 a 2010, N = 1951 condados) [100] ; Abajo: Índice de Bienestar de Gallup-Sharecare (2009-2016, N = 1,208 condados). [101]Los datos de Twitter fueron los mismos en ambos casos, abarcando una muestra aleatoria del 10 % de Twitter recopilada entre 2009 y 2015. [102] Publicado públicamente aquí.
Gen 3: Muestreo digital de cohortes: el futuro de la medición longitudinal
La mayor parte del trabajo discutido hasta ahora se ha limitado a un análisis transversal entre comunidades, pero las redes sociales ofrecen mediciones de alta resolución a lo largo del tiempo a un nivel que no es factible en la práctica con métodos basados en encuestas (p. medición a nivel comunitario). Esta abundancia de señales psicológicas específicas del tiempo ha motivado mucho trabajo previo. De hecho, muchos de los primeros trabajos que utilizaron conjuntos de datos de texto de redes sociales se centraron en gran medida en análisis longitudinales, que van desde la predicción de índices bursátiles utilizando léxicos de sentimientos y estados de ánimo (Gen 1, Nivel 1) [103] hasta la evaluación de la variación diurna temporal de positivos y negativos . afecto dentro de los individuos expresado en los feeds de Twitter ( Gen 1, Nivel 1 ). [104]Por ejemplo, algunos análisis mostraron que las personas tienden a despertarse con un estado de ánimo positivo que disminuye a lo largo del día. [105]
Este trabajo inicial sobre la medición longitudinal pareció desvanecerse después de que uno de los proyectos más icónicos, Google Flu Trends ( Gen 1, Level 1 ), [106] comenzó a producir resultados sorprendentemente erróneos. [107] Google Flu Trends supervisó consultas de búsqueda de palabras clave asociadas con la gripe; este enfoque podría detectar un brote de gripe hasta una semana antes de los informes del Centro para el Control y la Prevención de Enfermedades (CDC). Si bien los CDC tradicionalmente detectaron brotes de gripe a partir de los recuentos de ingesta de proveedores de atención médica; Google buscó detectar la gripe a partir de algo que las personas suelen hacer mucho antes cuando se enferman: buscar en Google sus síntomas.
Sin embargo, Google Flu Trends tenía una falla crítica: no podía considerar completamente el contexto del idioma; [108] por ejemplo, no podía distinguir las discusiones sobre los síntomas debido a las inquietudes en torno a la gripe aviar de la descripción de los propios síntomas. Esto llegó a un punto crítico en 2013 cuando sus estimaciones resultaron ser casi el doble de las de los sistemas de salud. [109] En resumen, este enfoque era susceptible a este tipo de influencias ruidosas en parte porque se basaba en series temporales aleatorias analizadas principalmente con enfoques basados en diccionarios (palabras clave) ( Gen 1 y Nivel 1 ).
Después de que se revelaran los errores de Google Flu Trends, el interés disminuyó en general, pero la investigación dentro del Procesamiento del lenguaje natural comenzó a abordar esta falla, recurriendo a métodos de aprendizaje automático ( Nivel 2 y 3 ). Para las enfermedades infecciosas, los investigadores han demostrado que las técnicas de modelado de temas podrían distinguir las menciones de los síntomas propios de otras discusiones médicas. [110] Para el bienestar, como se discutió anteriormente, las técnicas han ido más allá del uso de listas de palabras que se supone que significan bienestar (por expertos o anotadores; Nivel 1) a estimaciones que se basan en técnicas de aprendizaje automático para vincular empíricamente las palabras con el bienestar aceptado. siendo resultados (a menudo con validación cruzada fuera de la muestra; Nivel 2 ). [111]Más recientemente, se han utilizado grandes modelos de lenguaje como (incrustaciones de palabras contextualizadas, RoBERTa) para distinguir el contexto de las palabras ( Nivel 3 ). [112] Aquí, discutimos lo que creemos que será la tercera generación de métodos que toman el muestreo a nivel de persona y la corrección del sesgo de selección de Gen 2 y los combinan con muestreo longitudinal y diseños de estudio.
Muestras de cohortes digitales pioneras
Los resultados preliminares de la investigación en curso demuestran el potencial del muestreo de cohorte digital longitudinal ( Fig. 5.8). Esto va un paso más allá del muestreo a nivel de usuario y permite realizar un seguimiento de la variación en los resultados de bienestar a lo largo del tiempo: los cambios en el bienestar se estiman como la suma de los cambios dentro de la persona observados en la muestra. El muestreo de cohorte digital presenta varias oportunidades nuevas. Los cambios en el bienestar y la salud mental se pueden evaluar tanto a nivel individual como grupal (del entorno), lo que abre la puerta al estudio de su interacción. Además, se pueden descubrir patrones a corto plazo (semanales) y a largo plazo (cambios en escalas de tiempo de varios años). Finalmente, el diseño longitudinal desbloquea diseños cuasi-experimentales, tales como diseños de diferencia en diferencia, variable instrumental o discontinuidad de regresión. Por ejemplo, las tendencias en condados socioeconómicamente coincidentes se pueden comparar para estudiar el impacto de eventos específicos, como cierres por pandemias,
Se pueden descubrir patrones a corto plazo (semanales) y a largo plazo (cambios en escalas de tiempo de varios años).
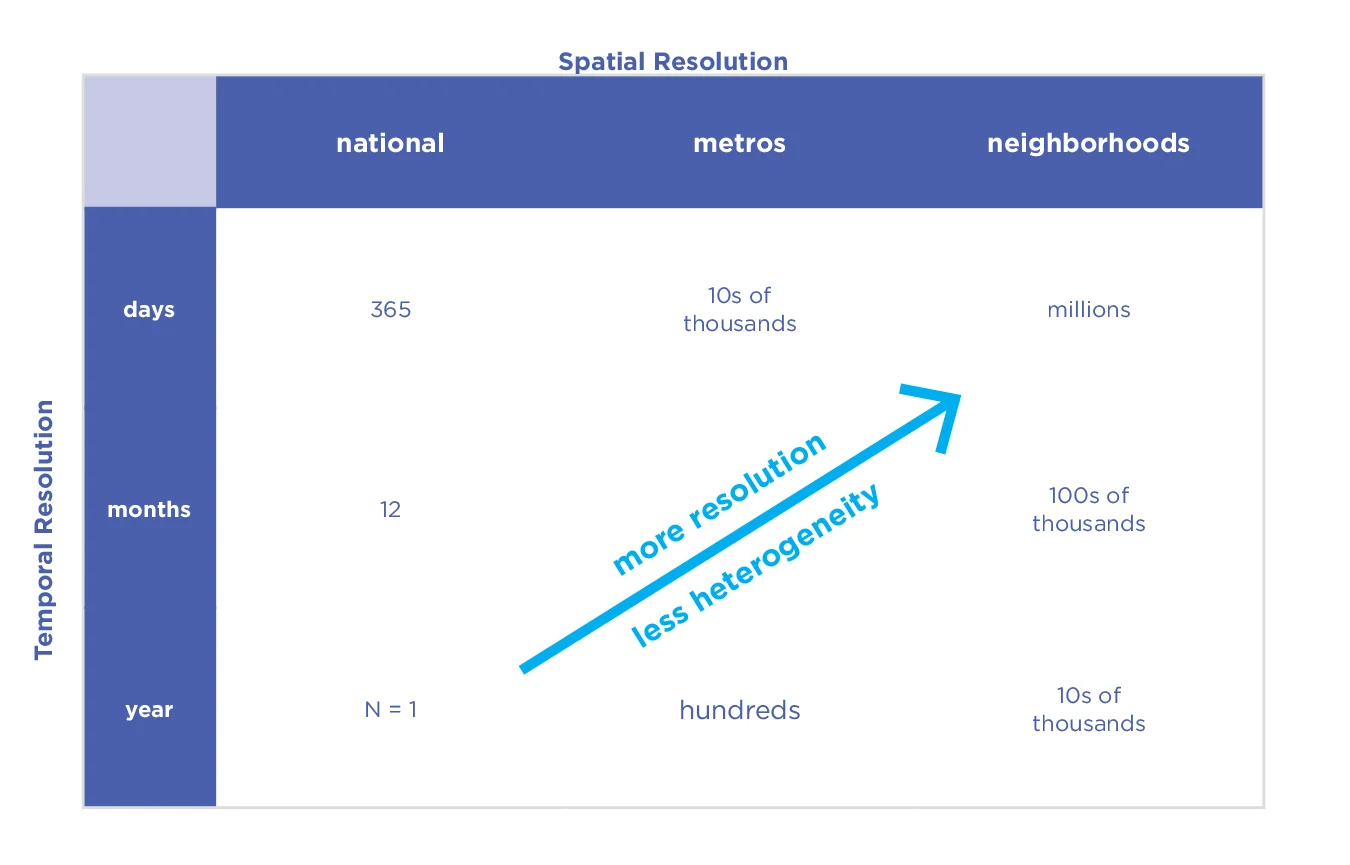
La elección de la resolución espaciotemporal. Los datos de las redes sociales son particularmente adecuados para los diseños longitudinales, ya que muchas personas interactúan con frecuencia con las redes sociales. Por ejemplo, en los EE. UU., el 38 % de los encuestados informaron interactuar con otros “una vez al día o más” a través de una de las cinco principales plataformas de redes sociales (esto varía del 19 % en India al 59 % en Brasil en siete países). [113] Incluso en estudios de investigación realizados por laboratorios de investigación universitarios, son factibles tamaños de muestra de más del 1 % de la población de EE. UU. (p. ej., el County-Tweet Lexical Bank con 6,1 millones de usuarios de Twitter). [114] En principio, tal abundancia de datos permite una alta resolución tanto en el espacio como en el tiempo, como las estimaciones de condado-semanas (ver Fig. 5.9).). La resolución más alta puede proporcionar a los economistas y a los formuladores de políticas información más detallada y confiable que se puede usar para evaluar el impacto de las políticas dentro de un marco cuasi-experimental.
Habilitación del enlace de datos. Las estimaciones a nivel mes-condado también parecen ser adecuadas para la vinculación de datos con los proyectos de vigilancia de la población en la salud de la población (por ejemplo, el Rastreador de sobredosis de opioides no fatales de la Oficina de Política Nacional de Control de Drogas [ONDCP]) y sirven como predictores de resultados de salud sensibles que varían con el tiempo, como los cambios a nivel de condado en las tasas de bajo peso al nacer. La estimación basada en principios y estabilizada de las series temporales a nivel de condado abre la puerta para que las mediciones basadas en las redes sociales se integren con el ecosistema más grande de conjuntos de datos diseñados para capturar la salud y el bienestar.
Figura 5.8 . Ejemplo de canalización de Twitter Gen 3 : cohortes digitales longitudinales componen unidades espaciales.
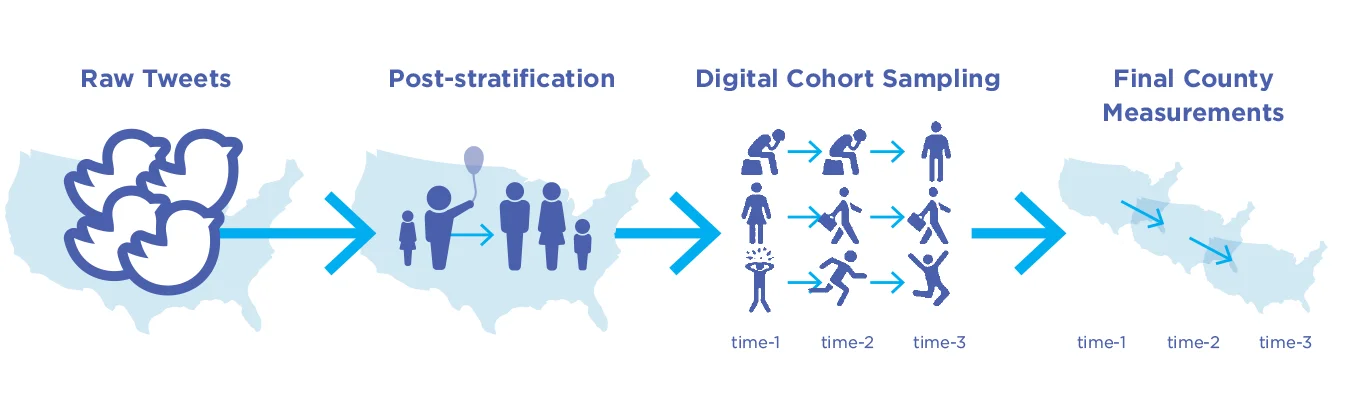
Figura 5.9. El número de puntos de datos de medición producidos en función de diferentes opciones de resolución temporal y espacial en estudios de diseño de cohortes digitales (Gen 3).
Trabajo próximo: evaluación del bienestar y la salud mental en el tiempo y el espacio
Los estudios que emplean cohortes digitales han surgido recientemente (es decir, estudios preliminares en preprints) relacionados con el seguimiento de la epidemia de opioides en las redes sociales. Por ejemplo, algunos investigadores ( Gen 3, Nivel 1 ) utilizan los datos del foro de Reddit para identificar y seguir a más de 1,5 millones de personas geolocalizadas en un estado y una ciudad para probar las relaciones entre los temas de debate y los cambios en la tasa de mortalidad de opioides. [115] De manera similar, otros investigadores ( Gen 3, Nivel 2 ) rastrean las tasas de opioides de una cohorte de condados para predecir el futuroCambios en las tasas de mortalidad por opioides. Si bien utilizan resoluciones temporales de granularidad gruesa (es decir, estimaciones anuales), estos trabajos sientan las bases de diseños de cohortes dentro de la persona y dentro de la comunidad que pueden reflejarse para monitorear el bienestar a escala. [116]
El campo está a punto de combinar el muestreo y la agregación Gen 3 con los análisis de lenguaje basados en incrustaciones contextualizados de Nivel 3 ( Gen 3, Nivel 3 ) , que proporcionarán resoluciones y precisiones de última generación.
Diseños de cohortes digitales Gen 3: resumen y limitaciones
El enfoque de cohorte digital tiene las ventajas de los enfoques a nivel de persona, así como un mayor control del diseño metodológico y estabilidad temporal de las estimaciones, incluida una resolución de medición mejorada en el tiempo y el espacio (p. ej., condado-meses). Como tal, desbloquea el control necesario para los diseños cuasi-experimentales. Sin embargo, las desventajas incluyen una mayor complejidad en la recopilación y el análisis de datos de series temporales a nivel de persona (incluida la necesidad de mayor seguridad y almacenamiento de datos). También puede ser un desafío recopilar suficientes datos para resoluciones espaciotemporales más altas (p. ej., resoluciones hasta el día del condado).

Resumen y direcciones futuras
Un completo conjunto de herramientas metodológicas para abordar los sesgos y proporcionar mediciones precisas
Con respecto a la cuestión de los sesgos de autopresentación, si bien pueden desviar los métodos de diccionario basados en palabras clave ( Nivel 1; como se analiza en la sección Abordar los sesgos de las redes sociales), la investigación indica que estos sesgos tienen menos impacto en los algoritmos de aprendizaje automático que se ajustan a muestras representativas. ( Nivel 2 ) que consideran todo el vocabulario para aprender asociaciones lingüísticas, en lugar de solo considerar palabras clave preseleccionadas fuera de contexto ( Fig. 5.5 ). [117] En lugar de basarse en suposiciones sobre cómo las palabras se relacionan con el bienestar (lo cual es peligroso debido a que la mayoría de las palabras tienen muchos sentidos, y las palabras generalmente solo transmiten su significado completo en contexto), [118] Nivel 2Los métodos de aprendizaje automático y de vocabulario abierto derivan estadísticamente las relaciones entre el lenguaje y el bienestar. Las estimaciones de las redes sociales basadas en el aprendizaje automático pueden mostrar un fuerte acuerdo con las evaluaciones de fuentes extralingüísticas, como las respuestas a encuestas, y demostrar que, al menos para los modelos de aprendizaje automático, el uso del lenguaje está fuertemente relacionado con el bienestar. [119]
Los enfoques a nivel de persona ( Gen 2 ) dan grandes pasos para abordar los problemas de la posible influencia de los bots de las redes sociales. La agregación a nivel de persona facilita la identificación y eliminación confiables de bots del conjunto de datos. Esto reduce su influencia en las estimaciones. [120]Además, los métodos de agregación postestratificados a nivel de persona abordan el problema de que los sesgos de selección dominan el análisis de las redes sociales. Existe una diferencia importante entre los datos no representativos y alguien que no está representado en los datos “en absoluto” (es decir, todos los grupos pueden estar representados, pero están relativamente subrepresentados o sobrerrepresentados): el uso de métodos robustos de posestratificación puede corregir los datos no representativos hacia la representatividad (siempre y cuando los estratos demográficos estén suficientemente representados en los datos). Por último, el diseño de la cohorte digital ( Gen 3)supera las deficiencias de las estrategias de agregación de datos que se basan en muestras aleatorias de tweets de muestras cambiantes de usuarios. En cambio, la investigación en curso muestra la posibilidad de seguir una muestra bien caracterizada a lo largo del tiempo y “muestrear” a partir de ella a través de la recopilación discreta de datos de las redes sociales. Este enfoque abre la puerta al conjunto de herramientas de métodos cuasi-experimentales y al enlace significativo de datos con otros esfuerzos de monitoreo de población de granularidad fina en la salud de la población.
Limitaciones: El lenguaje evoluciona en el espacio y el tiempo.
Variación semántica regional.Uno de los desafíos de usar el lenguaje a través de regiones geográficas y períodos de tiempo es que las palabras (y sus diversos sentidos) varían con la ubicación y el tiempo. Las predicciones geográficas y temporales plantean diferentes dificultades: Geográficamente, algunas palabras expresan diferencias subculturales (p. ej., “jazz” tiende a referirse a la música, pero en Utah, a menudo se refiere al equipo de baloncesto Utah Jazz). Algunas palabras también se usan en formas que dependen temporalmente (p. ej., feliz, por ejemplo, se invoca con frecuencia en Feliz Año Nuevo, que es un acto de habla con alta frecuencia, el 1 de enero, mientras que en otras ocasiones puede referirse a un emoción o evaluación/juicio (p. ej., “feliz por”, “una vida feliz”). El uso del lenguaje también depende demográficamente (“enfermo” significa cosas diferentes entre los jóvenes y los adultos mayores).[121] Es importante examinar la estructura de covarianza de las palabras más influyentes en modelos lingüísticos con marcadores de gradientes culturales y socioeconómicos. [122]
Deriva semántica (a lo largo del tiempo). Las palabras en lenguajes naturales también están sujetas a variaciones de significado a lo largo del tiempo a medida que se adaptan a los requisitos de las personas y su entorno. [123] Es posible documentar la deriva semántica utilizando técnicas de aprendizaje automático que actúan en un lapso de 5 a 10 años. [124] Debido a la deriva semántica, los modelos de aprendizaje automático no son permanentemente estables y, por lo tanto, pueden requerir una actualización (reentrenamiento o “ajuste”) cada década a medida que evolucionan la cultura y el uso del lenguaje.
Limitaciones: Cambios en la plataforma de Twitter
Un futuro incierto de Twitter bajo Musk.La accesibilidad de los datos de las redes sociales puede cambiar entre plataformas. Por ejemplo, después de comprar y hacerse cargo de Twitter a fines de 2022, Elon Musk está cambiando la forma en que opera Twitter. El acceso futuro a las interfaces de Twitter (API) presenta el mayor riesgo para la investigación de Twitter, ya que es posible que solo se pueda acceder a ellas sujetas a tarifas muy altas. También hay cambios potencialmente desconocidos en la composición de la muestra de Twitter posterior a noviembre de 2022, ya que los usuarios pueden abandonar Twitter en protesta (e ingresar de acuerdo con la preferencia política percibida). Además, los cambios en las características de la interfaz de usuario (p. ej., verificación futura obligatoria) pueden cambiar el tipo de conversaciones que tienen lugar y la composición de la muestra. Los diferentes niveles de estado de cuenta/publicación (pagado, verificado, no verificado) pueden diferenciar el alcance y el impacto de los tweets, que habrá que considerar; por lo tanto, es probable que los modelos temporales deban tener en cuenta los cambios de muestra/plataforma.
Un historial de cambios de plataforma no documentados. Este es un nuevo giro en las observaciones previas de que la composición del lenguaje de Twitter ha cambiado de manera discontinua en formas que Twitter históricamente no ha documentado y que solo un análisis cuidadoso podría revelar. [125] Por ejemplo, se ha demostrado que los cambios en el procesamiento de tweets de Twitter han resultado en series de tiempo corruptas de frecuencias lingüísticas (es decir, las frecuencias de palabras muestran cambios abruptos que no reflejan cambios reales en el uso del lenguaje sino simplemente cambios en el procesamiento, como diferentes aplicaciones de filtros de idioma en segundo plano [126]Estas series temporales corruptas no están documentadas en Twitter y pueden sesgar la investigación. Hasta cierto punto, tales inconsistencias pueden abordarse identificando y eliminando series de tiempo de palabras particulares, pero también a través de una agregación inicial más cuidadosa del idioma en usuarios. Los métodos que se basan en la agregación aleatoria de tweets pueden estar particularmente expuestos a estas inconsistencias, mientras que el uso de diseños de cohortes y a nivel de persona ( Gen 2 y 3 ) que se basan en muestras bien caracterizadas de usuarios específicos probablemente resulte más sólido.
Direcciones futuras: más allá de las redes sociales y entre culturas
Datos más allá de las redes sociales. Una preocupación común para las evaluaciones de bienestar derivadas de los análisis del lenguaje de las redes sociales es que las personas pueden guardar silencio en las redes sociales o migrar a otras plataformas de redes sociales. Es difícil imaginar que el uso de las redes sociales desaparecerá, aunque habrá desafíos para recopilar datos y preservar la privacidad. Además, el trabajo sugiere que también se pueden utilizar otras formas de comunicación. Por ejemplo, los mensajes de texto de las personas pueden usarse para evaluar tanto la depresión autoinformada [127] como el riesgo de suicidio [128] ; y los foros de discusión en línea en un periódico se pueden usar para evaluar el estado de ánimo. [129]El factor limitante para estos análisis es a menudo la cantidad de datos a los que se puede acceder fácilmente, las plataformas de redes sociales públicas por defecto, como Twitter y Reddit, generan datos que se consideran de dominio público. Esto es particularmente fácil de recopilar a escala sin el consentimiento de los sujetos individuales.
Medición más allá del inglés. Más allá de estas dificultades dentro del mismo idioma, se necesita más investigación en comparaciones entre culturas y entre idiomas. La mayoría de las investigaciones sobre las redes sociales y el bienestar se llevan a cabo con datos de un solo idioma, predominantemente en inglés. Un metanálisis reciente identificó 45 estudios que utilizan las redes sociales para evaluar el bienestar, 42 de los cuales estudian un solo idioma, siendo el inglés el más común ( n = 30); [130] Para mejorar el potencial de las comparaciones entre idiomas, se necesita más investigación para comprender cómo se puede hacer esto. Un avance potencial en este dominio puede ser proporcionado por la evolución reciente de grandes modelos multilingües, [131]que brindan representaciones compartidas en varios idiomas comunes y, en principio, pueden permitir la medición simultánea del bienestar en varios idiomas en función de datos de capacitación limitados para “afinar” estos modelos. Más allá de la medición, también se necesita investigación sobre cómo se usan las redes sociales de manera diferente en las culturas. Por ejemplo, la investigación indica que las personas tienden a generar contenido en las redes sociales que está de acuerdo con el afecto ideal de su cultura. [132]
Estamos comenzando a ver el uso de indicadores basados en las redes sociales en contextos de políticas. El principal de ellos, el Instituto Nacional de Estadística y Geografía (INEGI) de México ha demostrado un gran liderazgo en el desarrollo de mediciones de bienestar basadas en Twitter para las regiones mexicanas.
Bienestar entre culturas . Más allá de las diferencias interculturales en el uso de las redes sociales, dado que el campo está considerando una generación de instrumentos de medición más allá del autoinforme, es esencial reconsiderar cuidadosamente los supuestos inherentes a la elección de los constructos de bienestar medidos. Las culturas difieren en cómo se entiende y conceptualiza el bienestar, o la buena vida en general. [133] Una de las ventajas potenciales de la medición de la buena vida basada en el lenguaje es que muchos aspectos de ella se pueden medir a través de modelos de lenguaje ajustados. En principio, el lenguaje puede medir la armonía, la justicia, el sentido de igualdad y otros aspectos que las culturas de todo el mundo valoran.
Consideraciones éticas
El análisis de los datos de las redes sociales requiere un manejo cuidadoso de las cuestiones de privacidad. Las consideraciones clave incluyen el mantenimiento de la confidencialidad y la privacidad de las personas, lo que generalmente implica desidentificar y eliminar información confidencial automáticamente. Este trabajo es supervisado y aprobado por juntas de revisión institucional (IRB). Cuando la recopilación de datos a nivel individual es parte del diseño del estudio, por ejemplo, cuando se recopilan datos de idioma de una muestra de usuarios de redes sociales que han realizado una encuesta para entrenar un modelo de lenguaje, es necesario obtener el consentimiento informado aprobado por el IRB de estos participantes del estudio. siempre requerida. Si bien una discusión exhaustiva sobre todas las consideraciones éticas relevantes está más allá del alcance de este capítulo, alentamos al lector a consultar revisiones de consideraciones éticas. [134]
Esperamos que más grupos e instituciones de investigación utilicen estos métodos para desarrollar indicadores de bienestar en todo el mundo.
Conclusión y perspectiva
Los enfoques para evaluar el bienestar a partir del lenguaje de las redes sociales están madurando: los métodos para agregar y muestrear datos de las redes sociales se han vuelto cada vez más sofisticados a medida que han evolucionado desde el análisis de fuentes aleatorias (Gen 1) hasta el análisis de muestras de usuarios caracterizadas demográficamente. ( Gen 2 ) a estudios de cohortes digitales ( Gen 3 ). Los enfoques de análisis del lenguaje se han vuelto más precisos para representar y resumir la medida en que el lenguaje captura construcciones de bienestar, desde contar listas de palabras clave del diccionario (Nivel 1) hasta confiar en asociaciones de lenguaje sólidas aprendidas de los datos ( Nivel 2 ) para la nueva generación. de grandes modelos de lenguaje que consideran palabras dentro de contextos (Nivel 3 ).
El potencial para la medición global.Juntos, estos avances han dado como resultado una mayor precisión de medición y el potencial para diseños de investigación cuasiexperimentales más avanzados. Como siempre con los métodos de big data, “los datos son el rey”, cuantos más datos de redes sociales se recopilen y analicen, más precisas y detalladas pueden ser estas estimaciones. Después de una década en el campo desarrollando fundamentos metodológicos, la gran mayoría de los cuales son de código abierto y de dominio público, esperamos que más grupos e instituciones de investigación utilicen estos métodos para desarrollar indicadores de bienestar en todo el mundo, especialmente en idiomas distintos del inglés, recurriendo a otros tipos de redes sociales y fuera de los EE. UU. Es a través de un esfuerzo conjunto de este tipo que la estimación del bienestar basada en las redes sociales puede madurar y convertirse en un método rentable, preciso y
Referencias
Alessa, A. y Faezipour, M. (2018). Una revisión de la detección y predicción de la influenza a través de los sitios de redes sociales. Biología teórica y modelado médico , 15 (1), 1–27.
Auxier, B. y Anderson, M. (2021). Uso de las redes sociales en 2021. Pew Research Center , 1 , 1–4.
Bellet, C. y Frijters, P. (2019). Big data y bienestar. Informe mundial de la felicidad 2019 . 2019, 97-122.
Benton, A., Coppersmith, G. y Dredze, M. (2017). Protocolos éticos de investigación para la investigación en salud en las redes sociales. Actas del primer taller de ACL sobre ética en el procesamiento del lenguaje natural , 94–102.
Blei, DM, Ng, AY y Jordan, MI (2003). Asignación latente de dirichlet. Journal of Machine Learning Research , 3 (enero), 993–1022.
Bollen, J., Mao, H. y Zeng, X. (2011). El estado de ánimo de Twitter predice el mercado de valores. Revista de Ciencias Computacionales , 2 (1), 1–8.
Boyd, RL, Ashokkumar, A., Seraj, S. y Pennebaker, JW (2022). El desarrollo y las propiedades psicométricas de LIWC-22. Austin, TX: Universidad de Texas en Austin .
Bradley, MM y Lang, PJ (1999). Normas afectivas para palabras en inglés (ANEW): manual de instrucciones y calificaciones afectivas . Informe Técnico C-1, Centro de Investigación en Psicofisiología, Universidad de Florida.
Mayordomo, D. (2013). Cuando Google se equivocó de gripe. Naturaleza , 494 (7436), artículo 7436. https://doi.org/10.1038/494155a
Chew, C. y Eysenbach, G. (2010). Pandemias en la era de Twitter: análisis de contenido de tuits durante el brote de H1N1 2009. PloS One , 5 (11), e14118.
Cresci, S., Di Pietro, R., Petrocchi, M., Spognardi, A. y Tesconi, M. (2017). El cambio de paradigma de los spambots sociales: evidencia, teorías y herramientas para la carrera armamentista. Actas de la 26ª Conferencia Internacional sobre World Wide Web Companion , 963–972.
Culotta, A. (2014a). Estimación de las estadísticas de salud del condado con Twitter. Actas de la Conferencia SIGCHI sobre factores humanos en sistemas informáticos , 1335–1344.
Culotta, A. (2014b). Reducción del sesgo de muestreo en los datos de las redes sociales para la inferencia de salud del condado. Actas de las reuniones estadísticas conjuntas , 1–12.
Davis, CA, Varol, O., Ferrara, E., Flammini, A. y Menczer, F. (2016). Botornot: Un sistema para evaluar bots sociales. Actas de la 25ª Conferencia Internacional Compañero en World Wide Web , 273–274.
De Choudhury, M., Counts, S. y Horvitz, E. (2013). Las redes sociales como herramienta de medición de la depresión en las poblaciones. Actas de la 5ª Conferencia Anual de Ciencias Web de ACM , 47–56.
Deerwester, S., Dumais, ST, Furnas, GW, Landauer, TK y Harshman, R. (1990). Indexación por análisis semántico latente. Revista de la Sociedad Estadounidense de Ciencias de la Información , 41 (6), 391.
DeLucia, A., Wu, S., Mueller, A., Aguirre, C., Resnik, P. y Dredze, M. (2022). Bernice: un codificador preentrenado multilingüe para Twitter . 6191–6205. https://aclanthology.org/2022.emnlp-main.415
Devlin, J., Chang, M.-W., Lee, K. y Toutanova, K. (2019). BERT: Pre-entrenamiento de Transformadores Bidireccionales Profundos para la Comprensión del Lenguaje. Actas de la Conferencia de 2019 del Capítulo de América del Norte de la Asociación de Lingüística Computacional: Tecnologías del lenguaje humano, Volumen 1 (Artículos largos y cortos) , 4171–4186. https://doi.org/10.18653/v1/N19-1423
Dodds, PS, Clark, EM, Desu, S., Frank, MR, Reagan, AJ, Williams, JR, Mitchell, L., Harris, KD, Kloumann, IM y Bagrow, JP (2015). El lenguaje humano revela un sesgo de positividad universal. Actas de la Academia Nacional de Ciencias , 112 (8), 2389–2394.
Dodds, PS, Harris, KD, Kloumann, IM, Bliss, CA y Danforth, CM (2011). Patrones temporales de felicidad e información en una red social global: Hedonometrics y Twitter. PloS One , 6 (12), e26752.
Dodds, PS, Minot, JR, Arnold, MV, Alshaabi, T., Adams, JL, Dewhurst, DR, Reagan, AJ y Danforth, CM (2020). La dinámica de frecuencia de palabras a largo plazo derivada de Twitter está corrupta: un enfoque personalizado para detectar y eliminar patologías en conjuntos de series temporales. Preimpresión de ArXiv ArXiv:2008.11305 .
Durahim, AO y Coşkun, M. (2015). # iamhappybecause: felicidad nacional bruta a través del análisis de Twitter y big data. Pronóstico tecnológico y cambio social , 99 , 92–105.
Ebert, T., Götz, FM, Mewes, L. y Rentfrow, PJ (2022). Análisis espacial para psicólogos: cómo utilizar datos a nivel individual para la investigación a nivel agregado geográficamente. Métodos psicológicos .
Eichstaedt, JC, Schwartz, HA, Kern, ML, Park, G., Labarthe, DR, Merchant, RM, Jha, S., Agrawal, M., Dziurzynski, LA y Sap, M. (2015). El lenguaje psicológico en Twitter predice la mortalidad por enfermedades cardíacas a nivel de condado. Ciencia psicológica , 26 (2), 159–169.
Elmas, T., Overdorf, R. y Aberer, K. (2022). Caracterización de los bots de retweet: el caso de las cuentas del mercado negro. Actas de la Conferencia Internacional AAAI sobre Web y Medios Sociales , 16 , 171–182.
Ferrara, E., Varol, O., Davis, C., Menczer, F. y Flammini, A. (2016). El auge de los bots sociales. Comunicaciones de la ACM , 59 (7), 96–104.
Flanagan O., LeDoux JE, Bingle B., Haybron DM, Mesquita, B., Moody-Adams, M., Ren, S., Sun A. y Wilson, YY Con respuestas de los críticos Frey JA, Markus HR, Sachs JD y Tsai, JL Contra la felicidad, Columbia University Press
Forgeard, MJ, Jayawickreme, E., Kern, ML y Seligman, ME (2011). Hacer lo correcto: medir el bienestar para las políticas públicas. Revista Internacional de Bienestar , 1 (1).
Fukuda, M., Nakajima, K. y Shudo, K. (2022). Estimación de la población de bots en Twitter a través de un muestreo basado en paseos aleatorios. Acceso IEEE , 10 , 17201–17211. https://doi.org/10.1109/ACCESO.2022.3149887
Gallup y Meta. (2022). El estado de las conexiones sociales .
Gibbons, J., Malouf, R., Spitzberg, B., Martinez, L., Appleyard, B., Thompson, C., Nara, A. y Tsou, M.-H. (2019). Medidas basadas en Twitter del sentimiento del vecindario como predictores de la salud de la población residencial. PLOS UNO , 14 (7), e0219550. https://doi.org/10.1371/journal.pone.0219550
Ginsberg, J., Mohebbi, MH, Patel, RS, Brammer, L., Smolinski, MS y Brilliant, L. (2009). Detección de epidemias de influenza utilizando datos de consulta de motores de búsqueda. Naturaleza , 457 (7232), 1012–1014.
Giorgi, S., Eichstaedt, JC, Preotiuc-Pietro, D., Gardner, JR, Schwartz, HA, Ungar, L. (en revisión). Llenar el espacio en blanco: interpolación espacial con procesos gaussianos y datos de redes sociales.
Giorgi, S., Lynn, VE, Gupta, K., Ahmed, F., Matz, S., Ungar, LH y Schwartz, HA (2022). Corrección de sesgos de selección sociodemográfica para la predicción de población a partir de redes sociales. Actas de la Conferencia Internacional AAAI sobre Web y Medios Sociales , 16 , 228–240.
Giorgi, S., Preoţiuc-Pietro, D., Buffone, A., Rieman, D., Ungar, L. y Schwartz, HA (2018). El beneficio notable de la agregación a nivel de usuario para predicciones de nivel de población basadas en léxico. En Actas de la Conferencia de 2018 sobre métodos empíricos en el procesamiento del lenguaje natural (págs. 1167-1172).
Giorgi, S., Ungar, L. y Schwartz, HA (2021). Caracterización de los spambots sociales por sus rasgos humanos. Hallazgos de la Asociación de Lingüística Computacional: ACL-IJCNLP 2021 , 5148–5158.
Glenn, JJ, Nobles, AL, Barnes, LE y Teachman, BA (2020). ¿Pueden los mensajes de texto identificar el riesgo de suicidio en tiempo real? Un examen piloto dentro de los sujetos de los marcadores temporalmente sensibles del riesgo de suicidio. Ciencia psicológica clínica , 8 (4), 704–722.
Datos de la Asociación Global para el Desarrollo Sostenible, el Banco Mundial, las Naciones Unidas y la Red de Soluciones para el Desarrollo Sostenible. (2022). DATOS EN TIEMPO REAL PARA LOS ODS: Acelerar el progreso a través de información oportuna . https://www.data4sdgs.org/sites/default/files/2019-05/Datos en tiempo real para los ODS_Nota conceptual.pdf
Golder, SA y Macy, MW (2011). El estado de ánimo diurno y estacional varía con el trabajo, el sueño y la duración del día en diversas culturas. Ciencia , 333 (6051), 1878–1881.
Hedonómetro. Felicidad promedio para Twitter. (2022, 19 de diciembre). Obtenido de https://hedonometer.org/ .
Hogan, B. (2010). La presentación de uno mismo en la era de las redes sociales: Distinguir actuaciones y exhibiciones en línea. Boletín de Ciencia, Tecnología y Sociedad , 30 (6), 377–386.
Hsu, TW, Niiya, Y., Thelwall, M., Ko, M., Knutson, B. y Tsai, JL (2021). Los usuarios de las redes sociales producen más afecto que respalda los valores culturales, pero están más influenciados por el afecto que viola los valores culturales. Revista de Personalidad y Psicología Social .
Iacus, SM, Porro, G., Salini, S. y Siletti, E. (2020). Un índice de bienestar subjetivo compuesto italiano: la voz de los usuarios de Twitter de 2012 a 2017. Investigación de indicadores sociales , 1–19.
INEGI (2022, 19 de diciembre). Mapa del estado de ánimo de los usuarios de Twitter en México. Obtenido de https://www.inegi.org.mx/app/animotuitero/#/app/map .
Jaggi, M., Uzdilli, F. y Cieliebak, M. (2014). Chocolate suizo: Detección de sentimientos utilizando SVM dispersas y n-gramas de parte del discurso. Actas del 8º Taller Internacional sobre Evaluación Semántica (SemEval 2014) , 601–604.
Jaidka, K., Chhaya, N. y Ungar, L. (2018). Degradación diacrónica de los modelos lingüísticos: perspectivas de las redes sociales. Actas de la 56.ª Reunión Anual de la Asociación de Lingüística Computacional (Volumen 2: Artículos breves) , 195–200. https://doi.org/10.18653/v1/P18-2032
Jaidka, K., Giorgi, S., Schwartz, HA, Kern, ML, Ungar, LH y Eichstaedt, JC (2020). Estimación del bienestar subjetivo geográfico de Twitter: una comparación de diccionario y métodos de lenguaje basados en datos. Actas de la Academia Nacional de Ciencias , 117 (19), 10165–10171.
José, R., Matero, M., Sherman, G., Curtis, B., Giorgi, S., Schwartz, HA y Ungar, LH (2022). Uso del lenguaje de Facebook para predecir y describir el consumo excesivo de alcohol. Alcoholismo: Investigación Clínica y Experimental .
Kramer, AD (2010). Un modelo conductual discreto de “felicidad nacional bruta”. Actas de la Conferencia SIGCHI sobre factores humanos en sistemas informáticos , 287–290.
Lavertu, A., Hamamsy, T. y Altman, RB (2021). Monitoreo de la epidemia de opioides a través de discusiones en las redes sociales. MedRxiv .
Lazer, D., Kennedy, R., King, G. y Vespignani, A. (2014). La parábola de Google Flu: Trampas en el análisis de big data. Ciencia , 343 (6176), 1203–1205.
Poco, RJ (1993). Post-estratificación: la perspectiva de un modelador. Revista de la Asociación Estadounidense de Estadística , 88 (423), 1001–1012.
Liu, T., Meyerhoff, J., Eichstaedt, JC, Karr, CJ, Kaiser, SM, Kording, KP, Mohr, DC y Ungar, LH (2022). La relación entre el sentimiento del mensaje de texto y la depresión autoinformada. Revista de trastornos afectivos , 302 , 7–14.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L. y Stoyanov, V. (2019). Roberta: Un enfoque de preentrenamiento de bert sólidamente optimizado. Preimpresión de ArXiv ArXiv:1907.11692 .
Lomas, T., Lai, A., Shiba, K., Diego-Rosell, P., Uchida, Y. y VanderWeele, TJ (2022). Perspectivas de la primera encuesta mundial sobre el equilibrio y la armonía. Informe sobre la felicidad mundial 2022 , 127–154.
Luhmann, M. (2017). Uso de big data para estudiar el bienestar subjetivo. Opinión actual en ciencias del comportamiento , 18 , 28–33.
Mangalik, S., Eichstaedt, JC, Giorgi, S., Mun, J., Ahmed, F., Gill, G., … & Schwartz, HA (2023). Evaluaciones sólidas de salud mental basadas en el lenguaje en el tiempo y el espacio a través de las redes sociales. preimpresión de arXiv arXiv:2302.12952 .
Metzler, H., Pellert, M. y García, D. (2022). Uso de datos de redes sociales para capturar emociones antes y durante COVID-19. Informe sobre la felicidad mundial 2022 , 75–104.
Mitchell, L., Frank, MR, Harris, KD, Dodds, PS y Danforth, CM (2013). La geografía de la felicidad: conectando el sentimiento y la expresión de Twitter, la demografía y las características objetivas del lugar. PloS One , 8 (5), e64417.
Mohammad, S., Bravo-Márquez, F., Salameh, M. y Kiritchenko, S. (2018). Semeval-2018 tarea 1: Afecto en tuits. Actas del 12º Taller Internacional sobre Evaluación Semántica , 1–17.
OCDE. (2013). Directrices de la OCDE sobre la medición del bienestar subjetivo . Publicaciones de la OCDE. http://dx.doi.org/10.1787/9789264191655-es
Paul, M. y Dredze, M. (2011). Eres lo que tuiteas: análisis de Twitter para la salud pública. Actas de la Conferencia Internacional AAAI sobre Web y Medios Sociales , 5 (1), 265–272.
Paul, MJ y Dredze, M. (2012). Un modelo para extraer temas de salud pública de Twitter. Salud , 11 (16–16), 1.
Paul, MJ y Dredze, M. (2014). Descubrir temas de salud en las redes sociales utilizando modelos temáticos. PloS One , 9 (8), e103408.
Pellert, M., Metzler, H., Matzenberger, M. y García, D. (2022). Validación de los macroscopios diarios de las redes sociales de las emociones. Informes científicos , 12 (1), artículo 1. https://doi.org/10.1038/s41598-022-14579-y
Pennebaker, JW, Boyd, RL, Jordan, K. y Blackburn, K. (2015). El desarrollo y las propiedades psicométricas de LIWC2015. Trabajos de docentes/investigadores de la UT .
Pennebaker, JW, Francis, ME y Booth, RJ (2001). Investigación lingüística y recuento de palabras: LIWC 2001. Mahway: Lawrence Erlbaum Associates , 71 , 2001.
Qi, J., Fu, X. y Zhu, G. (2015). Medición de bienestar subjetivo basada en análisis de sentimiento de texto de blog de base chino. Información y gestión , 52 (7), 859–869. https://doi.org/10.1016/j.im.2015.06.002
Sametoglu, S., Pelt, D., Ungar, LH y Bartels, M. (2022). El valor del lenguaje de las redes sociales para la evaluación del bienestar: una revisión sistemática y un metanálisis .
Santillana, M., Zhang, DW, Althouse, BM y Ayers, JW (2014). ¿Qué puede aprender la detección digital de enfermedades de (una revisión externa de) Google Flu Trends? Revista estadounidense de medicina preventiva , 47 (3), 341–347. https://doi.org/10.1016/j.amepre.2014.05.020
Scao, TL, Fan, A., Akiki, C., Pavlick, E., Ilić, S., Hesslow, D., Castagné, R., Luccioni, AS, Yvon, F. y Gallé, M. (2022 ). BLOOM: un modelo de idioma multilingüe de acceso abierto con parámetros 176B. Preimpresión de ArXiv ArXiv:2211.05100 .
Schwartz, HA, Eichstaedt, J., Blanco, E., Dziurzynski, L., Kern, M., Ramones, S., Seligman, M. y Ungar, L. (2013). Eligiendo las palabras correctas: caracterizando y reduciendo el error del enfoque de conteo de palabras. Segunda conferencia conjunta sobre semántica léxica y computacional ( SEM), Volumen 1: Actas de la conferencia principal y la tarea compartida: similitud textual semántica *, 296–305.
Schwartz, HA, Eichstaedt, JC, Kern, ML, Dziurzynski, L., Lucas, RE, Agrawal, M., Park, GJ, Lakshmikanth, SK, Jha, S. y Seligman, ME (2013). Caracterización de la variación geográfica en el bienestar mediante tweets. ICWSM.
Schwartz, HA, Sap, M., Kern, ML, Eichstaedt, JC, Kapelner, A., Agrawal, M., Blanco, E., Dziurzynski, L., Park, G. y Stillwell, D. (2016) . Predecir el bienestar individual a través del lenguaje de las redes sociales . 516–527.
Seabrook, EM, Kern, ML, Fulcher, BD y Rickard, NS (2018). Predicción de la depresión a partir de la dinámica emocional basada en el lenguaje: análisis longitudinal de las actualizaciones de estado de Facebook y Twitter. Revista de investigación médica en Internet , 20 (5), e9267.
Shah, DS, Schwartz, HA y Hovy, D. (2020). Sesgos predictivos en los modelos de procesamiento del lenguaje natural: un marco conceptual y una descripción general. Actas de la 58.ª Reunión Anual de la Asociación de Lingüística Computacional , 5248–5264. https://doi.org/10.18653/v1/2020.acl-main.468
Shao, C., Ciampaglia, GL, Varol, O., Yang, K.-C., Flammini, A. y Menczer, F. (2018). La difusión de contenido de baja credibilidad por parte de los bots sociales. Comunicaciones de la naturaleza , 9 (1), 1–9.
Silver, L., Smith, A., Johnson, C., Taylor, K., Jiang, J., Anderson, M. y Rainie, L. (2019). Conectividad móvil en economías emergentes. Centro de Investigación Pew , 7 .
Smith, L., Giorgi, S., Solanki, R., Eichstaedt, J., Schwartz, HA, Abdul-Mageed, M., Buffone, A. y Ungar, L. (2016). ¿Se traduce ‘bienestar’ en Twitter? Actas de la Conferencia de 2016 sobre métodos empíricos en el procesamiento del lenguaje natural , 2042–2047.
Townsend, L. y Wallace, C. (2017). La ética del uso de datos de redes sociales en la investigación: un nuevo marco. En La ética de la investigación en línea (Vol. 2, págs. 189–207). Emerald Publishing Limited.
ONU (2016). Transformando nuestro mundo: La agenda 2030 para el desarrollo sostenible .
Vural, AG, Cambazoglu, BB, Senkul, P. y Tokgoz, ZO (2013). Un marco para el análisis de sentimientos en turco: Aplicación a la detección de polaridad de reseñas de películas en turco. En Informática y Ciencias de la Información III (págs. 437–445). Saltador.
Wang, N., Kosinski, M., Stillwell, DJ y Rust, J. (2014). ¿Se puede medir el bienestar mediante las actualizaciones de estado de Facebook? Validación del Índice de Felicidad Nacional Bruta de Facebook. Investigación de Indicadores Sociales , 115 (1), 483–491. https://doi.org/10.1007/s11205-012-9996-9
Wang, Z., Hale, S., Adelani, DI, Grabowicz, P., Hartman, T., Flöck, F. y Jurgens, D. (2019). Inferencia demográfica y estimaciones de población representativas a partir de datos multilingües de redes sociales. La Conferencia de la World Wide Web , 2056–2067.
Warriner, AB, Kuperman, V. y Brysbaert, M. (2013). Normas de valencia, excitación y dominancia para 13.915 lemas en inglés. Métodos de investigación del comportamiento , 45 (4), 1191–1207. https://doi.org/10.3758/s13428-012-0314-x
Wojcik, S. y Hughes, A. (2019). Evaluando a los usuarios de Twitter. Centro de Investigación PEW , 24 .
Wolf, M., Horn, AB, Mehl, MR, Haug, S., Pennebaker, JW y Kordy, H. (2008). Computergestützte textanalyse cuantitativo: Äquivalenz und robustheit der deutschen version des language research and word count. Diagnostica , 54 (2), 85–98.
Yaden, DB, Giorgi, S., Jordan, M., Buffone, A., Eichstaedt, J., Schwartz, HA, Ungar, L. y Bloom, P. (2022). Caracterización de la empatía y la compasión mediante el análisis lingüístico computacional. en prensa
Zamani, M., Buffone, A. y Schwartz, HA (2018). Predicción de la confianza humana a partir del lenguaje de Facebook. Preimpresión de ArXiv ArXiv:1808.05668 .
El Informe Mundial de la Felicidad es una publicación de la Red de Soluciones de Desarrollo Sostenible, impulsada por los datos de la Encuesta Mundial de Gallup.
El Informe cuenta con el respaldo de Fondazione Ernesto Illy, illycaffè, Davines Group, la marca de helados más grande de Unilever, Wall’s, The Blue Chip Foundation, The William, Jeff, and Jennifer Gross Family Foundation, The Happier Way Foundation y The Regeneration Society Foundation.
El Informe Mundial de la Felicidad fue escrito por un grupo de expertos independientes que actuaron a título personal. Las opiniones expresadas en este informe no reflejan necesariamente las opiniones de ninguna organización, organismo o programa de las Naciones Unidas.
Para consultas generales sobre el Informe mundial de la felicidad, comuníquese con info@worldhappiness.report .
Para consultas de los medios, comuníquese con media@worldhappiness.report.