

La disminución de la confianza en los datos obstaculiza el camino hacia el uso de los mismos, lo que afecta especialmente a los departamentos de marketing y finanzas.
por Myles Suer

- La esencia
- La importancia de generar confianza en los datos
- Los problemas de confianza en los datos amenazan el éxito empresarial
- Impactos de la baja confianza en los datos
- El papel de la privacidad de los datos en la confianza del cliente y la lealtad a la marca
- ¿Qué es la confiabilidad de los datos?
- ¿Qué es la observabilidad de los datos?
- Relacionados:
La esencia
- La gestión de riesgos es crucial. Los problemas de integridad de los datos ponen en riesgo estrategias comerciales defectuosas, sanciones regulatorias y dependencia de instintos poco confiables.
- Garantía de calidad vital. Los controles de calidad continuos y el seguimiento de las fuentes de datos son esenciales para mantener una alta confianza en los datos y evitar resultados negativos.
- Esfuerzos colaborativos clave. Alinear los procesos comerciales, mejorar la gobernanza de los datos y educar al personal son fundamentales para lograr una confianza confiable en los datos.
La confianza en los datos tiene como objetivo abordar los desafíos de la gestión de datos dentro de las empresas actuales. Debería abordar los datos que quedan atrapados en sistemas cerrados, a menudo duplicados y que adolecen de inexactitudes y definiciones deficientes.
Para contrarrestar estos problemas, la confianza en los datos debe garantizar la exactitud, la confiabilidad, la equidad y el cumplimiento normativo de los datos. La confianza en los datos debería hacer que los datos sean fáciles de encontrar, actualizados y gobernados adecuadamente. La implementación de estos principios libera a las organizaciones para innovar y transformar la experiencia del cliente y las propuestas de valor del mercado de sus negocios.
Según los autores de ” Los datos son asunto de todos “, los datos deben “convertirse en activos de datos que las personas puedan encontrar, confiar y utilizar para abordar necesidades comerciales no satisfechas sin tener que crear procesos y controles manuales y personalizados”.
La importancia de generar confianza en los datos
En el panorama actual centrado en los datos, la confianza en los datos no es negociable. La calidad, el cumplimiento y la confiabilidad de los datos forman la base de la toma de decisiones, la planificación estratégica y los resultados procesables. Cuando los datos se ven comprometidos, las empresas arriesgan todo, desde estrategias defectuosas hasta sanciones regulatorias, y pueden volver a instintos poco confiables en lugar de conocimientos basados en datos.
Los expertos de la industria subrayan la naturaleza crítica de la confianza en los datos y enfatizan su papel para garantizar una base común para resultados colectivos. Jim Russell, CIO de la Universidad de Manhattanville, dice: “Los datos sirven como elemento fundamental de las decisiones, análisis y proyecciones comerciales. Si la organización no puede confiar en esta base, cada uno de esos elementos se vuelve insustancial y es mucho más probable que conduzca a resultados y planificación incorrectos”.
Los problemas de confianza en los datos amenazan el éxito empresarial
Los desafíos a la confianza en los datos son multifacéticos y surgen de la complejidad, los actores maliciosos y la alfabetización inadecuada en ciencia de datos . No obstante, las empresas que verifican y confían en sus datos tienen una ventaja competitiva. Sin esto, las consecuencias son graves y se extienden hasta daños a la reputación, pérdidas financieras y más.
El CIO en transición, Martin Davis, sugiere que “si los datos son incorrectos, las decisiones, las acciones y los resultados no se producirán. Por lo tanto, es fundamental que se confíe en los datos, ya que sin confianza la empresa recurrirá al instinto para tomar decisiones y no a los datos”.
El vicepresidente de Constellation Research, Dion Hinchcliffe, añade: “La confianza en los datos es un elemento fundamental de los negocios. Sin él, no existe una base común ni la capacidad para crear resultados compartidos de manera confiable. Sin embargo, en la efímera era digital, cada vez es más difícil conseguir confianza en los datos. La causa es la complejidad de los datos y los malos actores. Para mí, los problemas de confianza ocurren en la recopilación de datos, las disputas, la tecnología de análisis/IA o la escasa alfabetización en ciencia de datos. Pero aquellos que no estén dispuestos a confiar o utilizar datos que puedan verificarse terminarán a merced competitiva de aquellos que sí lo hagan”.
Impactos de la baja confianza en los datos
La disminución de la confianza en los datos obstaculiza el camino hacia una tecnología basada en datos , lo que afecta especialmente a los departamentos de marketing y finanzas. Los equipos de marketing pueden terminar tomando malas decisiones estratégicas y asignando mal fondos debido a pronósticos de marketing de baja calidad. Los equipos financieros, que consideran los datos como la base de sus operaciones, enfrentan repercusiones aún más graves, ya que su confianza en el orden lógico y la confiabilidad de los datos es fundamental.
Una falla en la integridad de los datos puede provocar una disfunción generalizada, lo que obliga a realizar verificaciones y ajustes continuos. Las consecuencias notables, dice la CIO de Smart Manufacturing, Joanne Friedman, “incluyen daños al valor de la marca, como lo demuestra la experiencia de Air Canada , e interrupciones en medidas financieras cruciales como la tesorería, el flujo de efectivo y las métricas de los clientes”.
Existe una clara diferencia en el impacto de la confianza en los datos entre marketing y finanzas. Las finanzas requieren una confiabilidad de datos casi absoluta, mientras que las operaciones de marketing, aunque afectadas negativamente por la baja confianza, pueden soportar algunas discrepancias. En última instancia, la baja confianza en los datos puede hacer que los equipos pierdan tiempo administrando hojas de cálculo propensas a errores y puede generar resultados negativos graves, desde daños a la reputación hasta pérdidas financieras.
Hinchcliffe sostiene: “La tolerancia a la baja confianza en los datos entre marketing y finanzas básicamente define el espectro”. En pocas palabras, el CIO adjunto de UC Santa Bárbara, Joe Sabado, dice: “La integridad de los datos tiene consecuencias. Por un lado, la confianza es la base del éxito de una empresa. Además, puede haber resultados negativos (reputacionales, financieros, políticos…) a partir de datos erróneos”.
Fuente: https://www.cmswire.com/digital-marketing/achieve-reliable-data-trust-with-these-steps/
El papel de la privacidad de los datos en la confianza del cliente y la lealtad a la marca
Descubra la interacción crucial entre la privacidad de los datos, la confianza y la lealtad a la marca, y descubra por qué es esencial ser abierto sobre el uso de los datos.
por Scott Clark
La esencia
- Aumento de la conciencia. Aumenta la atención de los consumidores a la privacidad de los datos.
- Equilibrio de confianza. La personalización y la protección de datos son claves para la fidelización.
- La apertura gana. La transparencia en las prácticas de datos aumenta la confianza del cliente.
La privacidad de los datos ha pasado de ser una mera preocupación de backend a una piedra angular de las empresas orientadas al cliente. A medida que los consumidores se vuelven cada vez más conscientes de sus huellas digitales y se implementan regulaciones de privacidad de datos, las marcas deben manejar la información personal con sumo cuidado. Este artículo profundiza en cómo la privacidad de los datos afecta directamente la confianza del cliente y la lealtad a la marca, destacando su importancia en las estrategias comerciales modernas.
Tienes derecho a permanecer privado
La conciencia de los consumidores sobre los derechos de privacidad de los datos ha aumentado dramáticamente en los últimos años, en gran parte debido a las violaciones de datos que se han producido en marcas conocidas como Target , Activision y Chick-fil-A . Además, un informe de privacidad de datos de Deloitte de 2021 reveló que el 66% de los encuestados dijeron que les preocupa cómo las marcas con las que interactúan en línea utilizan sus datos personales. De manera similar, un informe de KPMG de 2021 sobre Responsabilidad de datos corporativos indicó que el 86% de los encuestados dijeron que sentían una preocupación creciente por la privacidad de los datos, mientras que el 78% dijo que estaban preocupados por la cantidad de datos que se recopilan.
Chris Jones, director de producto de Amperity , un proveedor de plataforma CDP, dijo a CMSWire que el papel que desempeña la privacidad de los datos en la configuración de la confianza del cliente y la lealtad a la marca en el mundo empresarial actual basado en datos es fundamental. “Los clientes se han vuelto cada vez más conscientes y preocupados por cómo las empresas manejan su información personal, especialmente después de varias violaciones de datos de alto perfil”.
Las regulaciones de privacidad de datos de los consumidores que se han implementado en los últimos años ( GDPR , CCPA , etc.) también han aumentado la conciencia de que no solo las empresas tienen regulaciones de privacidad que cumplir, sino que los consumidores tienen derecho a proteger sus datos. . Para cumplir con el RGPD, los sitios web han agregado varios tipos de ventanas emergentes de consentimiento de cookies que permiten a los usuarios optar por no usar cookies, una característica que la mayoría de las personas han llegado a aceptar como parte normal del uso de sitios web.

Myles Suer, director de marketing estratégico de Privacera , un proveedor de plataforma de gobierno de acceso unificado a datos, dijo a CMSWire que recuerda que después del ataque a Target preguntó a los CIO cómo Target no podía justificar la aplicación de parches a su software. “Para mi sorpresa, los CIO dijeron que ha sido difícil explicar a los tomadores de decisiones empresariales el valor de la ciberseguridad y por qué es esencial hacer cumplir los controles de privacidad y proteger los datos de los clientes”, dijo Suer.
Como todos los líderes con los que hablamos, Suer entiende que no hay duda de que comprometer la información personal afecta negativamente el valor de la marca. “Y el valor de la marca afecta aspectos como la lealtad del cliente, el margen y los beneficios percibidos del producto”.
Las principales empresas de navegadores web también han tomado medidas para dejar de permitir que las empresas utilicen cookies invasivas de terceros, que se han utilizado durante décadas para rastrear a los usuarios mientras se mueven de un sitio a otro. En cambio, las empresas han comenzado a utilizar datos propios y cero que los clientes proporcionan voluntariamente.
Un informe de 2023 de MediaMath indicó que el 65% de los consumidores clasificaron el “uso indebido de datos personales” como la principal razón por la que perderían la confianza en una marca. Además, el informe mostró que el 74% de los encuestados tienen más probabilidades de confiar en marcas que priorizan el uso de información personal con un enfoque seguro de la privacidad. “La privacidad y la confianza del cliente son 100% fundamentales en las empresas de hoy. Es por eso que hace unos años el nuevo CIO de Target dijo que otro ataque como el que habían experimentado eliminaría su franquicia comercial”, dijo Suer.
Privacidad de los datos del consumidor y cumplimiento normativo
Además del GDPR y otras regulaciones de privacidad de datos extranjeras, Estados Unidos tiene bastantes leyes de privacidad de datos propias:
- HIPAA ( Ley de Responsabilidad y Portabilidad del Seguro Médico ): Esta ley se refiere a la privacidad y seguridad de la información de salud del paciente.
- FERPA ( Ley de Privacidad y Derechos Educativos de la Familia ): Esta ley tiene que ver con los registros educativos de los estudiantes.
- COPPA ( Ley de protección de la privacidad infantil en línea ): para niños menores de 13 años, los sitios web deben obtener el consentimiento de los padres antes de recopilar información personal.
- GLBA ( Ley Gramm-Leach-Bliley ): Esta ley exige que las instituciones financieras expliquen sus prácticas de intercambio de información a los clientes.
- Ley de la FTC ( Ley de la Comisión Federal de Comercio ): Esta ley permite a la FTC tomar medidas contra las empresas que cometen prácticas de privacidad de datos de consumidores injustas o engañosas.
Más recientemente, el Congreso introdujo la Ley Estadounidense de Protección de la Privacidad de Datos (ADPPA), que tiene como objetivo brindar a los consumidores derechos fundamentales de privacidad de datos, establecer mecanismos sólidos de supervisión y garantizar una aplicación significativa.
Raymond Vélez, director global de tecnología de Publicis Sapient , una consultora digital, dijo a CMSWire que las empresas deberían adoptar un enfoque de “consentimiento progresivo” cuando se trata de datos. “Este enfoque requiere un modelo de consentimiento con ‘privacidad por defecto’. Estas regulaciones de privacidad en evolución tienen como objetivo poner en manos del consumidor el poder de elección y la visibilidad de cómo se manejan los datos personales”, dijo Vélez.
Los consumidores prefieren poder controlar su propia narrativa, algo que las regulaciones de privacidad de datos vuelven a poner sobre la mesa. “Permitir que los consumidores opten por no participar en la recopilación de datos les devuelve el poder y protege su privacidad”, dijo Vélez. “Las empresas deben ganarse el derecho a capturar datos y ganarse la confianza de sus clientes a lo largo del tiempo”. Vélez explicó que este enfoque hacia el consentimiento progresivo puede presentarse en forma de comunicación clara sobre cómo obtener permiso para las cookies y describir cómo la cookie (u otros datos de privacidad) ayuda a brindarle al consumidor una mejor experiencia.
“El RGPD y varias regulaciones estatales han añadido costos operativos, pero creo que el valor de la confianza del cliente digital también ha quedado claro”, afirmó Suer.
Personalización versus privacidad: los consumidores exigen ambas
A pesar de la abrumadora necesidad de privacidad de los datos, los consumidores también quieren que las experiencias que tienen con las empresas sean personalizadas. A todo el mundo le gusta que lo reconozcan cuando entra a una tienda o restaurante. En línea no es muy diferente: a los clientes les gusta ser reconocidos, respetados y comprendidos. Para que eso ocurra, el cliente debe compartir una cierta cantidad de datos y, afortunadamente, está dispuesto a hacerlo si eso resulta en una personalización y una mejor experiencia.
Nagendra Kumar, CTO de Gleen AI , una startup de IA generativa, dijo a CMSWire que, como marca, la privacidad de los datos de los clientes siempre es algo a lo que hay que estar atento. “Por otro lado, para el éxito de la marca es importante comprender las preferencias y los comportamientos de los clientes para poder ofrecerles la mejor experiencia”, dijo Kumar. “Los consumidores deben confiar en que las marcas utilizarán sus datos de manera responsable para brindarles una experiencia altamente personalizada”. experiencia y al mismo tiempo protege sus datos de malos actores y prácticas de marketing invasivas”.
El Informe de sentimiento sobre la experiencia del consumidor de Merkle de 2021 reveló que el 76% de los encuestados dijeron que realizarían una breve encuesta al visitar un sitio web por primera vez para tener una experiencia más personalizada. El informe indicó que los consumidores se sienten más cómodos dando sus datos de comportamiento para permitir que las marcas mejoren sus experiencias. De manera similar, la encuesta MediaMath de 2023 indicó que casi la mitad de los encuestados están interesados en compartir datos propios para una experiencia más efectiva y personalizada.
Meggie Giancola, vicepresidenta senior de estrategia y soluciones de ventas de Vericast , una empresa de soluciones de marketing, dijo a CMSWire que la privacidad de los datos representa un delicado equilibrio entre personalización y privacidad, y las empresas deben adaptarse rápidamente al panorama regulatorio que cambia rápidamente en este ámbito. “Si bien los consumidores desean un compromiso personalizado con la marca, también valoran su privacidad personal y la seguridad de sus datos. Para navegar la paradoja de la personalización sin comprometer la privacidad, las empresas deben centrarse en establecer un compromiso directo con los consumidores y obtener su consentimiento para recopilar información de forma segura”.
La transparencia de la privacidad de los datos es crucial
Cuando se trata del uso de datos, la transparencia es crucial. La transparencia permite a los clientes comprender mejor cómo una marca utilizará sus datos, lo que les permite confiar sus datos a la marca. Además, informar de forma transparente a las personas sobre las prácticas de recopilación de datos les permite dar su consentimiento informado. La encuesta de MediaMath indicó que el 59% de los clientes dijeron que su confianza en una marca aumentaría si se revelara cómo se determinó el destinatario del anuncio.
“Al adaptarse a los cambios legislativos y regulatorios, los especialistas en marketing deben convertir lo desconocido en conocido mediante prácticas transparentes en la recopilación y el uso de datos”, dijo Giancola. “Las marcas que comunican abiertamente sobre las prácticas de datos pueden aliviar las preocupaciones de los consumidores, fomentando la afinidad y la lealtad, impulsando así el crecimiento”.
Ser transparente sobre la privacidad de los datos demuestra que una empresa respeta y valora la privacidad de sus clientes. Esto genera confianza entre los clientes, lo que lleva a relaciones más sólidas y positivas. También pone a los clientes en el asiento del conductor al permitirles elegir si desean o no compartir sus datos con una marca.
Jones dijo que para generar y mantener la confianza, la transparencia es la clave. “Las marcas deben ser abiertas sobre sus prácticas de recopilación y uso de datos y garantizar el cumplimiento de las normas de protección de datos indica a los clientes que su privacidad es una prioridad absoluta”, dijo Jones. “Esta transparencia sienta las bases para la lealtad a la marca, ya que los clientes se sienten seguros de que sus Los datos están en buenas manos.”
Reflexiones finales sobre la privacidad y la confianza de los datos
La privacidad de los datos juega un papel crucial en la generación de confianza del consumidor en una empresa. Con violaciones de datos de alto perfil que afectan a marcas como Target y Activision, junto con regulaciones como el GDPR, el mensaje es alto y claro: las marcas deben priorizar la protección de datos y reconocer la importancia de equilibrar la personalización con la privacidad. A medida que la confianza se convierte en el activo más valioso de una marca, las empresas deben combinar ofertas personalizadas con una seguridad de datos férrea.
¿Qué es la confiabilidad de los datos?
La confiabilidad de los datos se refiere a la integridad y precisión de los datos como una medida de qué tanto puede contarse con que son constantes y no presentan errores en los distintos tiempos y fuentes.
por IBM
Cuanto más confiables sean los datos, más se puede contar con ellos. La confianza en los datos proporciona una base sólida para obtener insights significativos y para una toma de decisiones bien fundamentada, ya sea en investigación académica, analytics de negocio o políticas públicas.
Los datos poco precisos o poco confiables pueden conducir a conclusiones incorrectas, modelos defectuosos y una mala toma de decisiones. Es por eso que cada vez más empresas están introduciendo Chief Data Officers, una cantidad que se ha duplicado entre las principales empresas que cotizan en la bolsa entre 2019 y 2021.1
Los riesgos de datos malos por un lado, y las ventajas competitivas de los datos precisos por el otro significan que las iniciativas de confiabilidad de los datos deben ser la prioridad de cualquier negocio. Para tener éxito, es importante comprender qué implica evaluar y mejorar la confiabilidad, lo que se reduce en gran parte a la observabilidad de los datos, y luego establecer responsabilidades y objetivos claros para la mejora.
La implementación de la observabilidad de datos de extremo a extremo ayuda a los equipos de ingeniería de datos a garantizar la confiabilidad en toda su pila de datos identificando, solucionando y resolviendo problemas antes de que los problemas de datos malos tengan la oportunidad de propagarse.Demostración en vivoReserve una demostración de IBM Databand hoy mismo
Vea cómo la observabilidad proactiva de los datos puede ayudarle a detectar incidentes de datos con antelación y resolverlos más rápido.Contenido relacionado
Cómo se mide la confiabilidad de los datos
Medir la confiabilidad de sus datos requiere observar tres factores principales:
1. ¿Es válido?
La validez de los datos depende de si están almacenados y formateados correctamente y de si miden lo que deben medir. Por ejemplo, si está recopilando nuevos datos sobre un fenómeno particular del mundo real, los datos solo son válidos si reflejan con precisión ese fenómeno y no están influenciados por factores extraños.
2. ¿Están completos?
La integridad de los datos identifica si falta algo en la información. Si bien los datos pueden ser válidos, pueden estar incompletos si no hay algunos campos críticos que podrían cambiar la comprensión de la información. Los datos incompletos pueden dar lugar a análisis sesgados o incorrectos.
3. ¿Son únicos?
La unicidad de los datos revisa si hay duplicados en el conjunto de datos. Esta singularidad es importante para evitar una representación excesiva, que sería inexacta.
Para ir un paso más adelante, algunos equipos de datos también analizan otros factores, entre ellos:
- Si y cuándo se modificó la fuente de datos
- Qué cambios se hicieron en los datos
- Con qué frecuencia se han actualizado los datos
- De dónde provienen originalmente los datos
- Cuántas veces se han utilizado los datos
Medir la fiabilidad de los datos es esencial para ayudar a los equipos a generar confianza en sus conjuntos de datos y detectar posibles problemas en una fase temprana. Las pruebas de datos periódicas y eficaces pueden ayudar a los equipos de datos a localizar rápidamente los problemas para determinar su origen y tomar medidas para solucionarlos.Confiabilidad de los datos frente a calidad de los datos
Una plataforma de datos moderna está respaldada no solo por la Tecnología, sino también por las filosofías DevOps, DataOps y ágiles. Aunque DevOps y DataOps tienen propósitos completamente diferentes, cada uno es similar a la filosofía ágil, que está diseñada para acelerar los ciclos de trabajo de los proyectos.
DevOps se centra en el desarrollo de productos, mientras que DataOps, en crear y mantener un sistema de arquitectura de datos distribuido que ofrece valor comercial a partir de los datos.
Ágil es una filosofía para el desarrollo de software que promueve la velocidad y eficiencia, pero sin eliminar el factor “humano”. Pone énfasis en las conversaciones cara a cara como una forma de maximizar las comunicaciones, al tiempo que enfatiza la automatización como un medio para minimizar los errores.Confiabilidad de los datos frente a validez de los datos
La confiabilidad de los datos y la validez de los datos abordan dos aspectos distintos de la calidad de los datos.
En el contexto de la administración de datos, ambas cualidades juegan un papel crucial para garantizar la integridad y utilidad de los datos en cuestión.
- La confiabilidad de los datos se centra en la sistematicidad y repetibilidad de los datos en diferentes observaciones o mediciones. Básicamente, los datos confiables deben producir los mismos resultados o unos muy similares cada vez que se repite una medición o observación en particular. Se trata de garantizar que los datos sean estables y sistemáticos con el tiempo y en diferentes contextos.
- La validez de los datos, en el sentido de validación de datos, se refiere a la exactitud, estructura e integridad de los datos. Asegura que cualquier dato nuevo esté formateado correctamente, cumpla con las reglas necesarias y sea preciso e incorrupto.Por ejemplo, una columna de fecha debe tener fechas y no caracteres alfanuméricos. Los datos no válidos pueden generar diversos problemas, como errores de aplicaciones, resultados incorrectos de análisis de datos y mala calidad general de los datos.
Aunque la confiabilidad de los datos y la validez de los datos están relacionadas, no son intercambiables. Por ejemplo, es posible que tenga un proceso de recopilación de datos altamente confiable (que proporcione resultados sistemáticos y repetibles), pero si los datos que se recopilan no están validados (no cumplen con las reglas o formatos requeridos), el resultado final seguirá siendo datos de baja calidad.
Por el contrario, podría tener datos perfectamente válidos (que cumplan con todas las reglas de formato e integridad), pero si el proceso de recopilación de esos datos no es confiable (da resultados diferentes con cada medición u observación), la utilidad y confiabilidad de esos datos se vuelve cuestionable.
Para mantener la confiabilidad de los datos, se debe establecer y seguir de cerca un método uniforme para recopilar y procesar todo tipo de datos. Para la validez de los datos, deben existir protocolos rigurosos de validación de datos. Esto puede incluir comprobaciones de tipo de datos, verificaciones de rango, comprobaciones de integridad referenciales y otras. Estos protocolos ayudarán a garantizar que los datos estén en el formato correcto y se adhieran a todas las reglas necesarias.Problemas y desafíos de confiabilidad de datos
Todas las iniciativas de confiabilidad de datos plantean problemas y retos considerables en muchos ámbitos de la investigación y el análisis de datos, entre ellos:Recopilación y medición de datos
La forma en que se recopilan los datos puede afectar enormemente su confiabilidad. Si el método utilizado para recopilar datos es defectuoso o sesgado, los datos no serán confiables. Además, pueden producirse errores de medición en el momento de la recopilación de datos, durante la entrada de datos o cuando se procesan o analizan los datos.Consistencia de los datos
Los datos deben ser constantes con el tiempo y en diferentes contextos para ser confiables. Pueden surgir datos inconstantes debido a cambios en las técnicas de medición, las definiciones o los sistemas utilizados para recopilar datos.Error humano
El error humano siempre es una fuente potencial de falta de confiabilidad. Esto puede ocurrir de muchas maneras, como el ingreso de datos incorrecto, la codificación de datos inconstante y la interpretación errónea de los datos.Cambios a lo largo del tiempo
En algunos casos, lo que se mide puede cambiar con el tiempo, provocando problemas de fiabilidad. Por ejemplo, un modelo de aprendizaje automático que predice el comportamiento del consumidor podría ser confiable cuando se crea por primera vez, pero podría volverse inexacto a medida que cambia el comportamiento subyacente del consumidor.Gobernanza y control de datos
Las prácticas inconstante de gobernanza de datos y la falta de administración de datos pueden dar lugar a la falta de responsabilidad por la calidad y confiabilidad de los datos.Cambiar fuentes de datos
Cuando las fuentes de datos cambian o se actualizan, eso puede alterar la confiabilidad de los datos, especialmente si cambian los formatos o estructuras de los datos. La integración de datos de diferentes fuentes de datos también puede dar lugar a problemas de fiabilidad de los datos en su plataforma de datos moderna.Duplicación de datos
Los registros o entradas duplicados pueden generar inexactitudes y resultados sesgados. Identificar y manejar duplicados es un desafío para mantener la confiabilidad de los datos.
Abordar estos problemas y desafíos requiere una combinación de procesos de calidad de datos, gobernanza de datos, validación de datos y prácticas de gestión de datos.Pasos para garantizar la confiabilidad de los datos
Garantizar la fiabilidad de sus datos es un aspecto fundamental de una gestión sólida de los datos. A continuación se presentan algunas prácticas recomendadas para mantener y mejorar la confiabilidad de los datos en toda su pila de datos:
- Estandarice la recopilación de datos: establezca procedimientos claros y estandarizados para la recopilación de datos. Esto puede ayudar a reducir la variación y garantizar la constancia a lo largo del tiempo.
- Capacitar a los recolectores de datos: Las personas que recopilan datos deben estar debidamente capacitadas para comprender los métodos, herramientas y protocolos para minimizar los errores humanos. Deben ser conscientes de la importancia de contar con datos fiables y de las consecuencias de los datos poco fiables.
- Auditorías regulares: las auditorías regulares de datos son cruciales para detectar inconstancias o errores que podrían afectar la confiabilidad. En estas auditorías deben tratarse de encontrar errores, pero también de identificar las causas principales de los errores e implementar acciones correctivas.
- Utilice instrumentos confiables: utilice herramientas e instrumentos cuya confiabilidad haya sido probada. Por ejemplo, si utiliza el procesamiento de flujos, pruebe y supervise los flujos de eventos para asegurarse de que no se pierdan datos ni se dupliquen.
- Limpieza de datos: emplee un riguroso proceso de limpieza de datos. Esto debe incluir identificar y abordar valores atípicos, valores faltantes e inconstancias. Utilice métodos sistemáticos para manejar datos faltantes o problemáticos.
- Mantener un diccionario de datos: un diccionario de datos es un repositorio centralizado de información sobre datos, como tipos de datos, significados, relaciones con otros datos, origen, uso y formato. Ayuda a mantener la coherencia de los datos y garantiza que todos utilicen e interpreten los datos de la misma manera.
- Asegurar la reproducibilidad de los datos: Documentar todos los pasos en la recopilación y procesamiento de datos asegura que otros puedan reproducir sus resultados, lo cual es un aspecto importante de la confiabilidad. Esto incluye proporcionar explicaciones claras de las metodologías utilizadas y mantener el control de versiones para los datos y el código.
- Implementar la gobernanza de datos: las buenas políticas de gobernanza de datos pueden ayudar a mejorar la confiabilidad de los datos. Esto implica tener políticas y procedimientos claros sobre quién puede acceder y modificar datos y mantener registros claros de todos los cambios realizados en los conjuntos de datos.
- Copia de seguridad y recuperación de datos: realice copias de seguridad regulares de los datos para evitar la pérdida de datos. Además, asegúrese de que haya un sistema confiable para la recuperación de datos en caso de pérdida de datos.
Mejorar la confiabilidad de los datos a través de la observabilidad de los datos
La observabilidad de los datos consiste en comprender la salud y el estado de los datos en su sistema. Incluye diversas actividades que van más allá de solo describir un problema. La observabilidad de los datos puede ayudar a identificar, solucionar y resolver problemas de datos casi en tiempo real.
Es importante destacar que la observabilidad de los datos es esencial para adelantarse a los problemas de datos incorrectos, que se encuentran en el corazón de la confiabilidad de los datos. Mirando más profundamente, la observabilidad de datos abarca actividades como monitoreo, alertas, seguimiento, comparaciones, análisis, registro, seguimiento de SLA y linaje de datos, todas las cuales trabajan juntas para comprender la calidad de los datos de extremo a extremo, incluida la confiabilidad de los datos.
Cuando se hace bien, la observabilidad de los datos puede ayudar a mejorar la confiabilidad de los datos al hacer posible identificar los problemas desde el principio, para que todo el equipo de datos pueda responder más rápidamente, comprender el alcance del impacto y restaurar la confiabilidad.
Al implementar prácticas y herramientas de observabilidad de datos, las organizaciones pueden mejorar la confiabilidad de los datos, asegurando que sean precisos, constantes y confiables a lo largo de todo el ciclo de vida de los datos. Esto es especialmente crucial en entornos basados en datos donde los datos de alta calidad pueden impactar directamente en business intelligence, las decisiones basadas en datos y los resultados de negocio.
Fuente: https://www.ibm.com/mx-es/topics/data-reliability
¿Qué es la observabilidad de los datos?
La observabilidad de datos se refiere a la práctica de monitorear, administrar y mantener datos de una manera que garantice su calidad, disponibilidad y confiabilidad en varios procesos, sistemas y canales dentro de una organización.
por IBM
La observabilidad de los datos consiste en comprender verdaderamente la salud de sus datos y su estado en todo su ecosistema de datos. Incluye una variedad de actividades que van más allá del monitoreo tradicional, que solo describe un problema. La observabilidad de los datos puede ayudar a identificar, solucionar y resolver problemas de datos casi en tiempo real.
El uso de herramientas de observabilidad de datos es esencial para adelantarse a los problemas de datos incorrectos, que son la base de la confiabilidad de los datos. Estas herramientas permiten monitoreo automatizado, alertas de clasificación, seguimiento, comparaciones, análisis de causa raíz , registro, linaje de datos y seguimiento de acuerdos de nivel de servicio (SLA), todo lo cual funciona en conjunto para ayudar a los profesionales a comprender la calidad de los datos de un extremo a otro, incluida la confiabilidad de los datos. .
La implementación de una solución de observabilidad de datos es especialmente importante para los equipos de datos modernos, donde los datos se utilizan para obtener conocimientos, desarrollar modelos de aprendizaje automático e impulsar la innovación. Garantiza que los datos sigan siendo un activo valioso en lugar de un pasivo potencial.
La observabilidad de los datos debe infundirse de manera consistente durante todo el ciclo de vida de los datos de un extremo a otro. De esa manera, todas las actividades de gestión de datos involucradas están estandarizadas y centralizadas en todos los equipos para obtener una visión clara e ininterrumpida de los problemas y los impactos en toda la organización.
La observabilidad de los datos es la evolución natural del movimiento de la calidad de los datos, que está haciendo posible la práctica de operaciones de datos (DataOps).
Informe del analistaIBM nombrada líder por Gartner
Lea por qué IBM fue nombrado líder en el informe Gartner® Magic Quadrant™ de 2023 para servicios de desarrolladores de IA en la nube.Contenido relacionado
Por qué es importante la observabilidad de los datos
Simple y llanamente, la mayoría de las organizaciones creen que sus datos no son confiables:
- El 82% dice que las preocupaciones sobre la calidad de los datos son una barrera para los proyectos de integración de datos 1
- El 80% de los ejecutivos no confía en sus datos 2
No se puede subestimar el impacto de estos malos datos. En mayo de 2022, Unity Software descubrió que había estado ingiriendo datos incorrectos de un gran cliente, lo que provocó una caída del 30 % en las acciones de la empresa 3 y, en última instancia, le costó a la empresa 110 millones de dólares en ingresos perdidos 4 .
Tradicionalmente, ha sido difícil identificar datos incorrectos hasta que ya es demasiado tarde. A diferencia de cuando una aplicación deja de funcionar y afecta a miles de usuarios inmediatamente, las empresas pueden operar con datos incorrectos sin saberlo durante bastante tiempo. Por ejemplo, un equipo de ventas sabría de inmediato si un panel de Salesforce no se está cargando, pero no se sabe cuánto tiempo les tomaría darse cuenta de que un panel muestra datos incorrectos.
La observabilidad de los datos es la mejor defensa contra la difusión de datos incorrectos. Supervisa los canales de datos para garantizar la entrega completa, precisa y oportuna de los datos, de modo que los equipos de datos puedan evitar el tiempo de inactividad de los datos, cumplir con los SLA de datos y mantener la confianza de la empresa en los datos que ve.La evolución de la observabilidad de los datos.
Los sistemas de datos modernos proporcionan una amplia variedad de funciones, lo que permite a los usuarios almacenar y consultar sus datos de muchas maneras diferentes. Por supuesto, cuantas más funciones agregue, más complicado será garantizar que su sistema funcione correctamente. Esta complicación incluye:
Más fuentes de datos externas
En el pasado, la infraestructura de datos se creó para manejar pequeñas cantidades de datos (generalmente datos operativos de unas pocas fuentes de datos internas) y no se esperaba que los datos cambiaran mucho. Ahora, muchos productos de datos dependen de datos de fuentes internas y externas, y el gran volumen y velocidad con la que se recopilan estos datos pueden provocar derivas inesperadas, cambios de esquema, transformaciones y retrasos.
Transformaciones más complicadas
Una mayor cantidad de datos ingeridos de fuentes de datos externas significa que es necesario transformar, estructurar y agregar todos esos datos en todos los demás formatos para que sean utilizables. Peor aún, si esos formatos cambian, se produce un efecto dominó de fallas posteriores, ya que la lógica estrictamente codificada no logra adaptarse al nuevo esquema.
Demasiado enfoque en la ingeniería analítica
Los complejos canales de ingesta han creado un mercado de herramientas para simplificar este proceso de un extremo a otro, principalmente automatizando los procesos de ingesta y extracción, transformación, carga (ETL)/extracción, carga, transformación (ELT). Al combinarlos, se obtiene una plataforma de datos que la industria analítica ha denominado la “pila de datos moderna” o MDS. El objetivo del MDS es reducir la cantidad de tiempo que lleva que los datos estén disponibles para los usuarios finales (normalmente analistas) para que puedan comenzar a aprovechar esos datos más rápido. Sin embargo, cuanta más automatización tenga, menos control tendrá sobre cómo se entregan los datos. Estas organizaciones necesitan crear canales de datos personalizados para poder garantizar mejor que los datos se entreguen como se espera.Observabilidad de datos y el movimiento DataOps
Las operaciones de datos (DataOps) son un flujo de trabajo que permite un proceso de entrega ágil y un ciclo de retroalimentación para que las empresas puedan crear y mantener sus productos de manera más eficiente. DataOps permite a las empresas utilizar las mismas herramientas y estrategias en todas las fases de sus proyectos de análisis, desde la creación de prototipos hasta la implementación del producto.
El ciclo de DataOps describe las actividades fundamentales necesarias para mejorar la gestión de datos dentro del flujo de trabajo de DataOps. Este ciclo consta de tres etapas distintas: detección, concienciación e iteración.
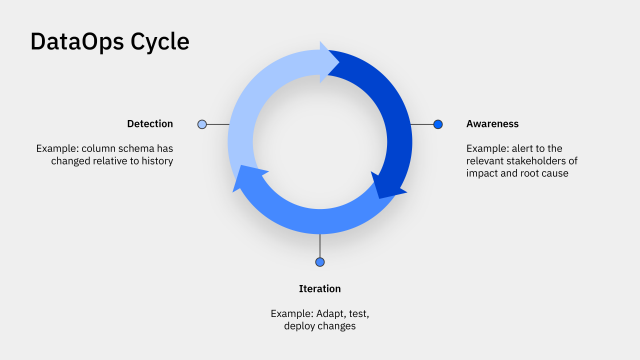
Detección
Es importante que este ciclo comience con la detección porque la base del movimiento DataOps se basa en una iniciativa de calidad de datos.
Esta primera etapa del ciclo DataOps se centra en la validación. Estos incluyen los mismos controles de calidad de los datos que se han utilizado desde el inicio del almacén de datos. Estaban analizando el esquema de columnas y las validaciones a nivel de filas. Básicamente, se garantiza que todos los conjuntos de datos cumplan con las reglas comerciales de su sistema de datos.
Este marco de calidad de datos que se encuentra en la etapa de detección es importante pero reaccionario por su propia naturaleza. Le brinda la capacidad de saber si los datos que ya están almacenados en su lago de datos o almacén de datos (y probablemente ya se estén utilizando) están en la forma que espera.
También es importante tener en cuenta que está validando conjuntos de datos y siguiendo reglas comerciales que conoce. Si no conoce las causas de los problemas, no podrá establecer nuevas reglas comerciales para que las sigan sus ingenieros. Esta comprensión alimenta la demanda de un enfoque de observabilidad continua de datos que se vincule directamente con todas las etapas del ciclo de vida de sus datos, comenzando con sus datos de origen.
Conciencia
La concientización es una etapa centrada en la visibilidad de la fase DataOps. Aquí es donde entra en escena la conversación sobre la gobernanza de datos y se introduce un enfoque centrado en los metadatos. Centralizar y estandarizar los metadatos de la canalización y del conjunto de datos en todo su ecosistema de datos brinda a los equipos visibilidad de los problemas dentro de toda la organización.
La centralización de metadatos es crucial para que la organización sea consciente del estado de sus datos de un extremo a otro. Hacer esto le permitirá avanzar hacia un enfoque más proactivo para resolver problemas de datos. Si hay datos incorrectos que ingresan a su “dominio”, puede rastrear el error hasta cierto punto en el nivel superior de su sistema de datos. Por ejemplo, el equipo de ingeniería de datos A ahora puede examinar los procesos del equipo de ingeniería de datos B y comprender lo que está sucediendo y colaborar con ellos para solucionar el problema.
También se aplica lo contrario. El equipo de ingeniería de datos B puede detectar un problema y rastrear el impacto que tendrá en las dependencias posteriores. Esto significa que el Equipo de ingeniería de datos A sabrá que ocurrirá un problema y podrá tomar todas las medidas necesarias para contenerlo.
Iteración
Aquí, los equipos se centran en los datos como código. Esta etapa del ciclo está centrada en el proceso. Los equipos se están asegurando de tener estándares repetibles y sostenibles que se aplicarán a todo el desarrollo de datos para garantizar que obtengan los mismos datos confiables al final de esos procesos.
La mejora gradual del estado general de la plataforma de datos ahora es posible gracias a la detección de problemas, el conocimiento de las causas fundamentales y los procesos eficientes de iteración.Beneficios de la observabilidad de datos
Una estrategia de observabilidad de datos bien ejecutada puede ofrecer una variedad de beneficios que contribuyen a una mejor calidad de los datos, la toma de decisiones, la confiabilidad y el desempeño organizacional general. Éstas incluyen: Mayor calidad de datos
La observabilidad de los datos permite a los equipos detectar problemas como valores faltantes, registros duplicados o formatos inconsistentes desde el principio, antes de que afecten las dependencias posteriores. Con datos de mayor calidad, las organizaciones pueden tomar mejores decisiones basadas en datos que conducen a mejores operaciones, satisfacción del cliente y rendimiento general.Solución de problemas más rápida
La observabilidad de los datos permite a los equipos identificar rápidamente errores o desviaciones en los datos mediante la detección de anomalías, el monitoreo en tiempo real y las alertas. La resolución de problemas y problemas más rápida ayuda a minimizar el costo y la gravedad del tiempo de inactividad.Colaboración mejorada
Al utilizar paneles compartidos que ofrecen las plataformas de observabilidad de datos, varias partes interesadas pueden obtener visibilidad del estado de conjuntos de datos críticos, lo que puede fomentar una mejor colaboración entre los equipos.Eficiencia incrementada
Las herramientas de observabilidad de datos ayudan a identificar cuellos de botella y problemas de rendimiento, lo que permite a los ingenieros optimizar sus sistemas para un mejor uso de los recursos y tiempos de procesamiento más rápidos. Además, la automatización reduce el tiempo y el esfuerzo necesarios para mantener la salud de sus datos, lo que permite a los ingenieros, analistas y científicos de datos centrar sus esfuerzos en obtener valor de los datos.Cumplimiento mejorado
La observabilidad de los datos puede ayudar a las organizaciones de industrias altamente reguladas, como las finanzas, la atención médica y las telecomunicaciones, a garantizar que sus datos cumplan con los estándares necesarios de precisión, coherencia y seguridad. Esto reduce el riesgo de incumplimiento y sanciones asociadas.Experiencia del cliente mejorada
Los datos de alta calidad son esenciales para comprender las necesidades, preferencias y comportamientos de los clientes, lo que, a su vez, permite a las organizaciones ofrecer experiencias más personalizadas y relevantes. La observabilidad de los datos puede ayudar a las organizaciones a mantener datos de clientes precisos y actualizados, lo que lleva a una mayor satisfacción y lealtad del cliente.Mayores ingresos
Al mejorar la calidad de los datos a través de la observabilidad, las organizaciones pueden desbloquear nuevos conocimientos, identificar tendencias y descubrir posibles oportunidades de generación de ingresos. Aprovechando al máximo sus activos de datos, las organizaciones pueden aumentar sus ingresos y su crecimiento.Los 5 pilares de la observabilidad de los datos
Juntos, los cinco pilares de la observabilidad de los datos brindan información valiosa sobre la calidad y confiabilidad de sus datos.
1. Frescura
La frescura describe qué tan actualizados están sus datos y con qué frecuencia se actualizan. La obsolescencia de los datos ocurre cuando hay lagunas importantes en el tiempo cuando los datos no se han actualizado. A menudo, cuando las canalizaciones de datos se interrumpen se debe a un problema de actualización.
2. Distribución
La distribución, un indicador del estado de sus datos a nivel de campo, se refiere a si los datos se encuentran o no dentro de un rango aceptado. Las desviaciones de la distribución esperada pueden indicar problemas de calidad de los datos, errores o cambios en las fuentes de datos subyacentes.
3. Volumen
El volumen se refiere a la cantidad de datos que se generan, ingieren, transforman y mueven a través de diversos procesos y canalizaciones. También se refiere a la integridad de sus tablas de datos. El volumen es un indicador clave para determinar si la ingesta de datos cumple o no con los umbrales esperados.
4. Esquema
El esquema describe la organización de sus datos. Los cambios de esquema a menudo dan como resultado datos rotos. La observabilidad de los datos ayuda a garantizar que sus datos estén organizados de manera consistente, sean compatibles entre diferentes sistemas y mantengan su integridad durante todo su ciclo de vida.
5. Linaje
El propósito de Lineage es responder a la pregunta: “¿Dónde?” cuando los datos se rompen. Observa los datos desde su origen hasta su ubicación final y observa cualquier cambio, incluido qué cambió, por qué cambió y cómo cambió a lo largo del camino. El linaje suele representarse visualmente.Observabilidad de los datos versus calidad de los datos
La observabilidad de los datos respalda la calidad de los datos , pero los dos son aspectos diferentes de la gestión de datos.
Si bien las prácticas de observabilidad de datos pueden señalar problemas de calidad en los conjuntos de datos, por sí solas no pueden garantizar una buena calidad de los datos. Eso requiere esfuerzos para solucionar los problemas de datos y evitar que ocurran en primer lugar. Por otro lado, una organización puede tener una sólida calidad de datos incluso si no implementa una iniciativa de observabilidad de datos.
El monitoreo de la calidad de los datos mide si la condición de los conjuntos de datos es lo suficientemente buena para los usos previstos en aplicaciones operativas y analíticas. Para tomar esa determinación, los datos se examinan en función de varias dimensiones de calidad, como precisión, integridad, coherencia, validez, confiabilidad y puntualidad.Observabilidad de datos versus gobernanza de datos
La observabilidad de los datos y la gobernanza de los datos son procesos complementarios que se apoyan mutuamente.
El gobierno de datos tiene como objetivo garantizar que los datos de una organización estén disponibles, sean utilizables, consistentes y seguros, y que se utilicen de conformidad con los estándares y políticas internos. Los programas de gobernanza a menudo incorporan o están estrechamente vinculados a esfuerzos de mejora de la calidad de los datos.
Un programa sólido de gobernanza de datos ayuda a eliminar los silos de datos, los problemas de integración de datos y la mala calidad de los datos que pueden limitar el valor de las prácticas de observabilidad de datos.
La observabilidad de los datos puede ayudar al programa de gobernanza al monitorear los cambios en la calidad, disponibilidad y linaje de los datos.La jerarquía de la observabilidad de los datos.
No toda la observabilidad de los datos es igual. El nivel de contexto que puede lograr depende de los metadatos que pueda recopilar y brindar visibilidad. Esto se conoce como jerarquía de observabilidad de datos. Cada nivel es la base para el siguiente y le permite alcanzar niveles de observabilidad cada vez más finos.

Monitoreo del estado operativo, datos en reposo y en movimiento
Obtener visibilidad del estado operativo y del conjunto de datos es una base sólida para cualquier marco de observabilidad de datos.
Los datos en reposo
Monitorear el estado del conjunto de datos se refiere al monitoreo de su conjunto de datos en su conjunto. Obtendrá conocimiento del estado de sus datos mientras se encuentran en una ubicación fija, lo que se conoce como “datos en reposo”.
El monitoreo de conjuntos de datos responde a preguntas como:
- ¿Este conjunto de datos llegó a tiempo?
- ¿Este conjunto de datos se actualiza con la frecuencia necesaria?
- ¿Está disponible el volumen esperado de datos en este conjunto de datos?
Datos en movimiento
El monitoreo operativo se refiere al monitoreo del estado de sus tuberías. Este tipo de monitoreo le brinda conocimiento del estado de sus datos mientras se transforman y se mueven a través de sus canalizaciones. Este estado de los datos se denomina “datos en movimiento”.
El monitoreo de tuberías responde a preguntas como:
- ¿Cómo afecta el rendimiento de la canalización a la calidad del conjunto de datos?
- ¿En qué condiciones se considera exitosa una carrera?
- ¿Qué operaciones están transformando el conjunto de datos antes de que llegue al lago o al almacén?
Si bien el monitoreo del conjunto de datos y de la canalización de datos generalmente se separa en dos actividades diferentes, es esencial mantenerlos acoplados para lograr una base sólida de observabilidad. Estos dos estados están altamente interconectados y dependen uno del otro. Separar estas dos actividades en diferentes herramientas o equipos hace que sea más difícil obtener una vista de alto nivel del estado de sus datos.Perfilado a nivel de columna
La creación de perfiles a nivel de columna es clave para esta jerarquía. Una vez que se ha establecido una base sólida, la creación de perfiles a nivel de columna le brinda la información que necesita para establecer nuevas reglas comerciales para su organización y aplicar las existentes a nivel de columna en lugar de solo a nivel de fila.
Este nivel de conciencia le permite mejorar su marco de calidad de datos de una manera muy práctica.
Le permite responder preguntas como:
- ¿Cuál es el rango esperado para una columna?
- ¿Cuál es el esquema esperado de esta columna?
- ¿Qué tan única es esta columna?
Validación a nivel de fila
Desde aquí, puede pasar al nivel final de observabilidad: validación a nivel de fila. Esto analiza los valores de los datos en cada fila y valida que sean precisos.
Este tipo de observabilidad analiza:
- ¿Están los valores de datos de cada fila en la forma esperada?
- ¿Los valores de los datos tienen la longitud exacta que espera que tengan?
- Dado el contexto, ¿hay suficiente información aquí para ser útil para el usuario final?
Cuando las organizaciones obtienen una visión de túnel en la validación a nivel de fila, resulta difícil ver el bosque a través de los árboles. Al crear un marco de observabilidad que comienza con el monitoreo operativo y de conjuntos de datos, puede obtener un contexto general sobre el estado de sus datos y, al mismo tiempo, concentrarse en la causa raíz de los problemas y sus impactos posteriores.Implementación de un marco de observabilidad de datos
A continuación se detallan los pasos principales que normalmente implican la construcción de un proceso de observabilidad exitoso. El proceso implica la integración de varias herramientas y tecnologías, así como la colaboración de diferentes equipos dentro de una organización.
- Defina métricas clave: comience por identificar las métricas críticas que necesita realizar un seguimiento. Esto podría incluir métricas de calidad de datos, volúmenes de datos, latencia, tasas de error y utilización de recursos. La elección de métricas dependerá de sus necesidades comerciales específicas y de la naturaleza de su canal de datos.
- Elija las herramientas adecuadas: a continuación, elija las herramientas que necesitará para la recopilación, el almacenamiento, el análisis y las alertas de datos. Asegúrese de que las herramientas que seleccione, incluidas las de código abierto, sean compatibles con su infraestructura existente y puedan manejar la escala de sus operaciones.
- Estandarizar bibliotecas: implementar infraestructura que permita a los equipos hablar el mismo idioma y comunicarse abiertamente sobre problemas. Esto incluye bibliotecas estandarizadas para API y gestión de datos (es decir, consultar el almacén de datos, leer/escribir desde el lago de datos, extraer datos de las API, etc.) y la calidad de los datos.
- Instrumente su canal de datos: la instrumentación implica la integración de bibliotecas o agentes de recopilación de datos en su canal de datos. Esto le permite recopilar las métricas definidas de varias etapas de su canalización. El objetivo es lograr una visibilidad integral, por lo que es clave garantizar que cada etapa crucial esté instrumentada.
- Configure una solución de almacenamiento de datos: las métricas recopiladas deben almacenarse en una base de datos o en una plataforma de series temporales que pueda escalar a medida que crecen sus datos. Asegúrese de que la solución de almacenamiento que elija pueda manejar el volumen y la velocidad de sus datos.
- Implementar herramientas de análisis de datos: estas herramientas ayudan a obtener información a partir de las métricas almacenadas. Para un análisis más profundo, considere utilizar herramientas que proporcionen visualizaciones intuitivas y admitan consultas complejas.
- Configure alertas y notificaciones: establezca un sistema para enviar alertas automáticas cuando se crucen umbrales predefinidos o se produzca una detección de anomalías. Esto ayudará a su equipo a responder rápidamente a los problemas, minimizando cualquier posible tiempo de inactividad.
- Integre con plataformas de gestión de incidentes: además de detectar problemas, la observabilidad también implica la gestión eficaz de los problemas. Integrar su proceso de observabilidad con un sistema de gestión de incidentes puede ayudar a optimizar sus flujos de trabajo de respuesta.
- Revise y actualice periódicamente su canal de observabilidad: a medida que su negocio evoluciona, también lo harán sus datos y requisitos. Revisar y actualizar periódicamente su canal de observabilidad garantiza que seguirá proporcionando la información y el rendimiento necesarios.
La construcción de un canal de observabilidad es un proceso continuo de aprendizaje y refinamiento. Es fundamental empezar poco a poco, aprender de la experiencia y ampliar gradualmente sus capacidades de observabilidad.
Fuente: https://www.ibm.com/topics/data-observability