
La generación aumentada por recuperación (RAG) te permite personalizar LLMs sin ajustes, ayudándote a ahorrar dinero y acelerar el tiempo hasta la implementación. Seguir leyendo para descubrir cómo optimizar la implementación de RAG para tu organización.
por Intel
Puntos clave
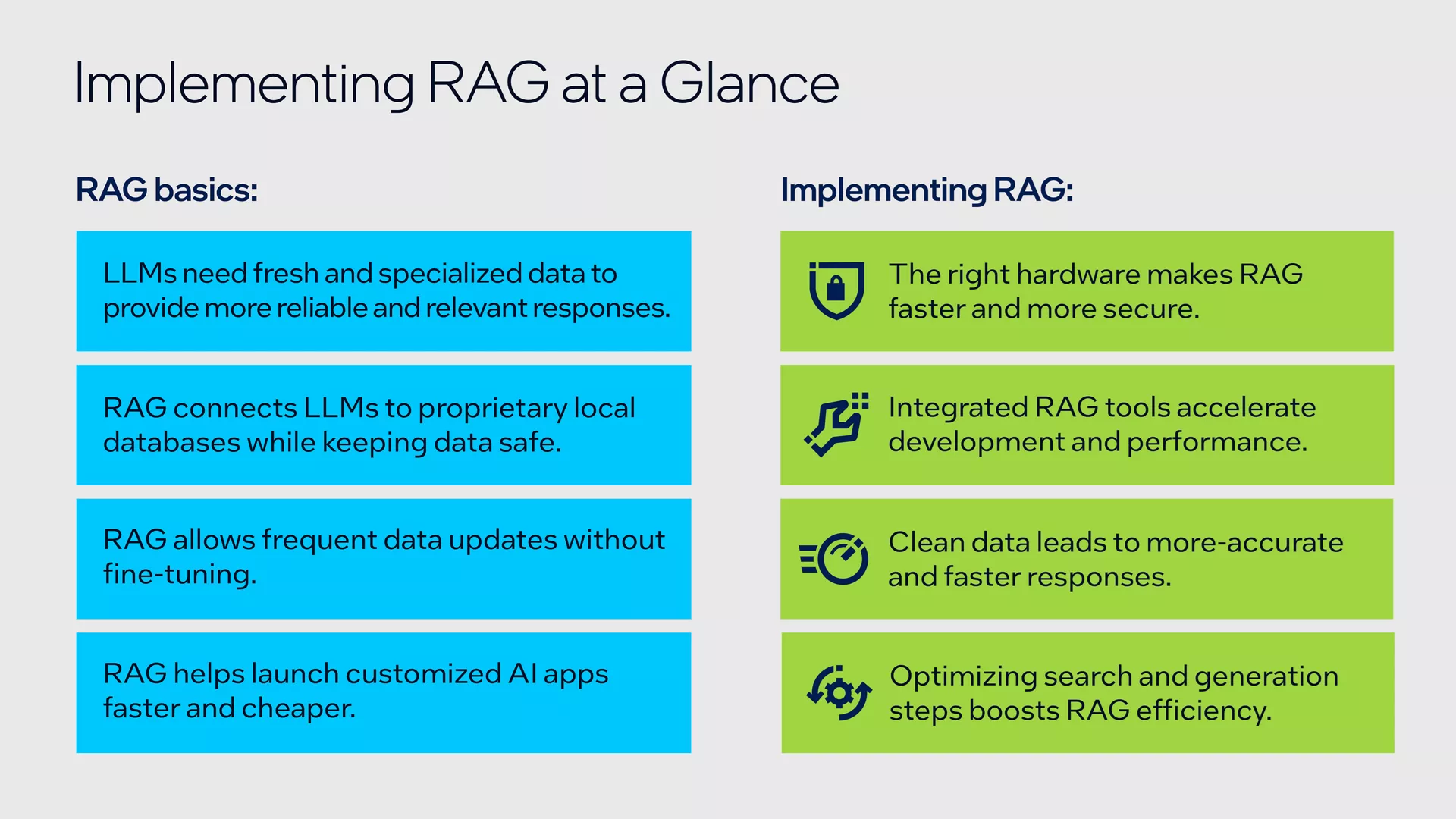
- RAG es un enfoque ideal para tu aplicación LLM si no tienes el tiempo ni el presupuesto para ajustes.
- Elegir una plataforma de cómputo que pueda impulsar el canal completo, incluidas cargas de trabajo de inferencia LLM exigentes.
- Implementar un marco de trabajo RAG integrado, como LangChain o fastRAG de Intel Lab, para ayudar a optimizar el desarrollo.
- Aprovechar procesadores diseñados específicamente y optimizaciones clave para maximizar el desempeño del canal de RAG.
- Probar el desempeño de las aplicaciones RAG en la cartera de IA de Intel® y proveedores de la nube con la nube para desarrolladores de Intel® Tiber™.
RAG y la IA generativa
Las aplicaciones con modelos de lenguaje de gran tamaño (LLM), como los chatbots, están generando beneficios importantes en todos los sectores. Las organizaciones utilizan LLMs para reducir los costos operativos, aumentar la productividad de los empleados y ofrecer experiencias más personalizadas a los clientes.
A medida que organizaciones como la tuya compiten por convertir esta tecnología revolucionaria en una ventaja competitiva, la mayoría de ellas primero necesitará personalizar las LLMs que están listas para usar según los datos de su organización para que los modelos puedan ofrecer resultados de IA específicos para empresas. Sin embargo, la inversión en tiempo y costo que se requiere para ajustar modelos puede representar obstáculos importantes que frenan a muchos innovadores en potencia.
Para superar estas barreras, la generación aumentada por recuperación (RAG) ofrece un enfoque más rentable para la personalización de LLM. Al permitirte crear modelos sobre tus datos propietarios sin necesidad de ajustes, RAG puede ayudarte a lanzar rápidamente aplicaciones de LLM personalizadas para tu empresa o tus clientes. En lugar de requerir reentrenamiento o ajustes, el enfoque de RAG te permite conectar el LLM listo para usar a una base de conocimientos externa seleccionada basada en los datos propietarios exclusivos de tu organización. Esta base de conocimientos informa los resultados del modelo con contexto e información específicos de la organización.
En este artículo, descubrirás cómo configurar los componentes clave de tu implementación de RAG, desde elegir las bases de tu hardware y software hasta crear tu base de conocimientos y optimizar tu aplicación en producción. También compartiremos herramientas y recursos que pueden ayudarte a aprovechar al máximo la potencia y la eficiencia de cada fase del proceso.
¿Cuándo es RAG el enfoque adecuado?
Antes de comenzar a evaluar los componentes básicos del canal, es importante considerar si RAG o el ajuste son la mejor opción para tu aplicación de LLM.
Ambos enfoques comienzan con un LLM fundamental, que ofrece una ruta más corta hacia LLMs personalizados que el entrenamiento de un modelo desde cero. Los modelos fundamentales han sido entrenados previamente y no requieren acceso a conjuntos de datos masivos, un equipo de expertos en datos ni energía informática adicional para el entrenamiento.
Sin embargo, una vez que elijas un modelo fundamental, aún necesitarás personalizarlo para tu empresa para que tu modelo pueda ofrecer resultados que aborden tus desafíos y necesidades. RAG puede ser una excelente opción para tu aplicación de LLM si no tienes el tiempo ni el dinero para invertir en ajustes. RAG también reduce el riesgo de alucinaciones, puede proporcionar fuentes para sus resultados para mejorar la explicabilidad y ofrece beneficios de seguridad, ya que la información confidencial se puede mantener de manera segura en bases de datos privadas.

Hardware
El canal de RAG incluye muchos componentes que requieren gran potencia de cómputo, y los usuarios finales esperan respuestas de baja latencia. Esto hace que elegir tu plataforma de cómputo sea una de las decisiones más importantes que tomarás a medida que buscas respaldar el canal de extremo a extremo.
Los procesadores Intel® Xeon® te permiten impulsar y administrar el canal de RAG completo en una sola plataforma, lo que optimiza el desarrollo, la implementación y el mantenimiento. Los procesadores Intel® Xeon® incluyen motores de IA integrados para acelerar las operaciones clave en todo el proceso, incluida la ingesta de datos, la recuperación de datos y la inferencia de IA en la CPU sin la necesidad de hardware adicional.
Para las aplicaciones RAG que requieren el mayor rendimiento o la menor latencia, puedes integrar los aceleradores de IA Intel® Gaudi®para satisfacer las exigencias avanzadas de desempeño de forma rentable. Los aceleradores Intel® Gaudi® están diseñados específicamente para acelerar la inferencia e incluso pueden reemplazar las CPUs y otros aceleradores para la inferencia de RAG.
Debido a que las organizaciones suelen utilizar RAG cuando trabajan con datos confidenciales, proteger tu canal durante el desarrollo y la producción es primordial. Los procesadores Intel® Xeon® utilizan tecnologías de seguridad integradas, extensiones de protección de software Intel® (Intel® SGX) y extensiones de dominios de confianza Intel® (Intel® TDX) para permitir el procesamiento seguro de la IA en todo el canal a través de la informática confidencial y el cifrado de datos.
Una vez implementada, tu aplicación puede experimentar una mayor latencia debido a un aumento en la demanda de los usuarios finales. El hardware Intel® es altamente escalable, por lo que puedes agregar recursos de infraestructura rápidamente a medida que aumentan las necesidades. También puedes integrar optimizaciones para respaldar operaciones clave en todo el canal, como la vectorización de datos, la búsqueda de vectores y la inferencia de LLM.
Puedes probar el desempeño de RAG en los procesadores de IA de Intel® Xeon® e Intel® Gaudi® a través de la nube para desarrolladores Intel® Tiber™.
Utiliza un marco de trabajo RAG para integrar fácilmente cadenas de herramientas de IA
Para conectar muchos componentes, los canales RAG combinan varias cadenas de herramientas de IA para la ingesta de datos, bases de datos de vectores, LLMs y más.
A medida que comienzas a desarrollar tu aplicación RAG, los marcos de trabajo RAG integrados, como LangChain, fastRAG de Intel Lab, y LlamaIndex pueden optimizar el desarrollo. Los marcos de trabajo RAG suelen proporcionar APIs para integrar cadenas de herramientas de IA en todo el canal sin problemas y ofrecen soluciones basadas en plantillas para casos de uso del mundo real.
Intel ofrece optimizaciones para ayudar a maximizar el desempeño general del canal en hardware de Intel®. Por ejemplo, fastRAG integra la extensión de Intel® para PyTorch y Optimum Habana para optimizar aplicaciones RAG en procesadores Intel® Xeon® y aceleradores Intel® Gaudi®
Intel también contribuyó con optimizaciones a LangChain para mejorar el desempeño en hardware de Intel®.

Crear tu base de conocimientos
RAG permite a las organizaciones alimentar LLMs con información propietaria importante sobre su empresa y clientes. Estos datos se almacenan en una base de datos de vectores que puedes crear tú mismo.
Identificar fuentes de información
Imagina utilizar RAG para implementar un asistente personal de IA que pueda ayudar a responder preguntas de los empleados sobre tu organización. Podrías alimentar datos clave a LLM, como información de productos, políticas de la empresa, datos de clientes y un protocolo específico del departamento. Los empleados podrían hacerle preguntas al chatbot impulsado por RAG y obtener respuestas específicas de la organización, lo que ayudaría a los empleados a completar tareas más rápidamente y empoderarlos para que se centren en el pensamiento estratégico.
Por supuesto, las bases de conocimientos variarán en diferentes industrias y aplicaciones. Una empresa farmacéutica podría querer utilizar un archivo de resultados de pruebas e historial de pacientes. Un fabricante podría alimentar especificaciones de equipos y datos de desempeño históricos a un brazo robótico basado en RAG para que pueda detectar problemas potenciales de los equipos desde el principio. Una institución financiera podría querer conectar un LLM a estrategias financieras propietarias y tendencias de mercado en tiempo real para permitir que un chatbot brinde asesoramiento financiero personalizado.
En última instancia, para crear tu base de conocimientos, necesitas recopilar los datos importantes a los que deseas que tu LLM acceda. Estos datos pueden provenir de una variedad de fuentes basadas en texto, incluidos PDFs, transcripciones de video, correos electrónicos, diapositivas de presentación e incluso datos tabulares de fuentes como páginas de Wikipedia y hojas de cálculo.. RAG también admite soluciones de IA multimodal, que combinan múltiples modelos de IA para procesar datos de cualquier modalidad, incluidos sonido, imágenes y video.
Por ejemplo, un minorista podría utilizar una solución RAG multimodal para buscar imágenes de vigilancia para eventos clave rápidamente. Para hacer esto, el minorista crearía una base de datos de imágenes de video y utilizaría instrucciones de texto, como “hombre poniendo algo en su bolsillo” para identificar clips relevantes sin tener que buscar cientos de horas de video manualmente.
Preparar tus datos
Para preparar tus datos para un procesamiento eficiente, primero necesitarás limpiar los datos, por ejemplo, eliminando información y ruido duplicados, y dividirlos en segmentos administrables. Puedes leer más consejos para limpiar tus datos aquí.
A continuación, necesitarás utilizar un marco de trabajo de IA llamado modelo de inserción para convertir tus datos en vectores, o representaciones matemáticas del texto que ayudan al modelo a comprender un contexto más amplio. Los modelos de incrustación se pueden descargar de un tercero, como los que se presentan en la tabla de clasificación de modelos de embedding de código abierto de Hugging Face, y a menudo se pueden integrar sin problemas en tu marco de trabajo RAG a través de APIs de Hugging Face. Después de la vectorización, puedes almacenar tus datos en una base de datos de vectores para que estén listos para que el modelo los recupere de una manera eficiente.
Dependiendo del volumen y la complejidad de tus datos, procesar datos y crear incrustaciones pueden ser tan intensivos en términos de cómputo como la inferencia de LLM. Los procesadores Intel® Xeon® pueden manejar de manera eficiente toda la ingesta, la inserción y la vectorización de datos en un nodo basado en CPU sin la necesidad de hardware adicional.
Además, los procesadores Intel® Xeon® pueden combinarse con modelos de incrustación cuantificados para optimizar el proceso de vectorización, mejorando el rendimiento de codificación hasta 4 veces en comparación con modelos no cuantificados.1.
Optimizar la recuperación de consultas y contexto
Cuando un usuario envía una consulta a un modelo basado en RAG, un mecanismo de recuperación busca en tu base de conocimientos datos externos relevantes para enriquecer el resultado final del LLM. Este proceso depende de operaciones de búsqueda de vectores para encontrar y clasificar la información más relevante.
Las operaciones de búsqueda vectorial están altamente optimizadas en procesadores Intel® Xeon®. Las extensiones de vectores avanzadas Intel® 512 (Intel® AVX-512) integradas en los procesadores Intel® Xeon® mejoran las operaciones clave en la búsqueda de vectores y reducen el número de instrucciones, ofreciendo mejoras significativas en el rendimiento y el desempeño.
También puedes aprovechar la solución de búsqueda vectorial escalable (SVS) de Intel Lab para mejorar el desempeño de la base de datos de vectores. SVS optimiza las capacidades de búsqueda vectorial en CPUs Intel® Xeon® para mejorar los tiempos de recuperación y el desempeño general del canal.
Optimizar la generación de respuestas LLM
Una vez equipado con datos adicionales de tu almacén de vectores, el LLM puede generar una respuesta contextualmente precisa. Esto implica la inferencia LLM, que típicamente es la fase más exigente en términos de cómputo del canal RAG.
Los procesadores Intel® Xeon® utilizan Extensiones de matriz avanzadas Intel® (Intel® AMX), un acelerador de IA integrado, para permitir operaciones de matriz más eficientes y una gestión de memoria mejorada, ayudando a maximizar el desempeño de la inferencia. Para LLMs medianos y grandes, utiliza aceleradores de IA Intel® Gaudi® para acelerar la inferencia con desempeño y eficiencia de IA diseñados específicamente.
Intel también ofrece varias bibliotecas de optimización para ayudarte a maximizar la inferencia LLM en tus recursos de hardware. Nuestras bibliotecas Intel® oneAPI proporcionan optimizaciones de bajo nivel para marcos de IA populares como PyTorch y TensorFlow, permitiéndote utilizar herramientas de código abierto familiares que están optimizadas en hardware de Intel®. También puedes agregar extensiones, como la Extensión Intel® para PyTorch para permitir técnicas de inferencia cuantificada avanzadas para aumentar el desempeño general.
Una vez que tu aplicación esté en producción, es posible que desees actualizar al LLM más reciente para mantener el ritmo de la demanda de los usuarios finales. Debido a que RAG no implica ajustes y tu base de conocimientos existe fuera del modelo, RAG te permite reemplazar rápidamente tu LLM con un nuevo modelo para admitir una inferencia más rápida.
Fuente: https://www.intel.la/content/www/xl/es/goal/how-to-implement-rag.html