

Presentamos el aprendizaje anidado: un nuevo paradigma de aprendizaje automático para el aprendizaje continuo
por Ali Behrouz, investigador estudiantil, y Vahab Mirrokni, vicepresidente y miembro de Google Research
Nested Learning es un nuevo enfoque del aprendizaje automático que ve los modelos como un conjunto de problemas de optimización anidados más pequeños, cada uno con su propio flujo de trabajo interno, para mitigar o incluso evitar por completo el problema del “olvido catastrófico”, donde aprender nuevas tareas sacrifica la competencia en tareas antiguas.
La última década ha presenciado un progreso increíble en el aprendizaje automático (ML), impulsado principalmente por potentes arquitecturas de redes neuronales y los algoritmos utilizados para entrenarlas. Sin embargo, a pesar del éxito de los grandes modelos de lenguaje (LLM), persisten algunos desafíos fundamentales, especialmente en torno al aprendizaje continuo, es decir, la capacidad de un modelo para adquirir activamente nuevos conocimientos y habilidades a lo largo del tiempo sin olvidar los antiguos.
En lo que respecta al aprendizaje continuo y la superación personal, el cerebro humano es la referencia. Se adapta mediante la neuroplasticidad: la notable capacidad de cambiar su estructura en respuesta a nuevas experiencias, recuerdos y aprendizaje. Sin esta capacidad, una persona se ve limitada al contexto inmediato (como la amnesia anterógrada). Observamos una limitación similar en los LLM actuales: su conocimiento se limita al contexto inmediato de su ventana de entrada o a la información estática que aprenden durante el preentrenamiento.
El enfoque simple, que consiste en actualizar continuamente los parámetros de un modelo con nuevos datos, suele conducir al olvido catastrófico (OC), donde el aprendizaje de nuevas tareas sacrifica la competencia en las tareas anteriores. Tradicionalmente, los investigadores combaten el OC mediante ajustes arquitectónicos o mejores reglas de optimización. Sin embargo, durante demasiado tiempo, hemos tratado la arquitectura del modelo (la estructura de la red) y el algoritmo de optimización (la regla de entrenamiento) como dos elementos separados, lo que nos impide lograr un sistema de aprendizaje verdaderamente unificado y eficiente.
En nuestro artículo, “ Aprendizaje Anidado: La Ilusión de las Arquitecturas de Aprendizaje Profundo ”, publicado en NeurIPS 2025 , presentamos el Aprendizaje Anidado, que cierra esta brecha. El Aprendizaje Anidado trata un solo modelo de ML no como un proceso continuo, sino como un sistema de problemas de aprendizaje interconectados de múltiples niveles que se optimizan simultáneamente. Argumentamos que la arquitectura del modelo y las reglas utilizadas para entrenarlo (es decir, el algoritmo de optimización) son fundamentalmente los mismos conceptos; son simplemente diferentes “niveles” de optimización, cada uno con su propio flujo interno de información (“flujo de contexto”) y tasa de actualización. Al reconocer esta estructura inherente, el Aprendizaje Anidado proporciona una nueva dimensión, previamente invisible, para diseñar una IA más capaz, lo que nos permite construir componentes de aprendizaje con mayor profundidad computacional, lo que en última instancia ayuda a resolver problemas como el olvido catastrófico.
Probamos y validamos el aprendizaje anidado a través de una arquitectura de prueba de concepto y automodificable que llamamos “Hope”, que logra un rendimiento superior en el modelado del lenguaje y demuestra una mejor gestión de la memoria de contexto largo que los modelos de última generación existentes.
El paradigma del aprendizaje anidado
El aprendizaje anidado revela que un modelo complejo de aprendizaje automático (ML) es en realidad un conjunto de problemas de optimización coherentes e interconectados, anidados entre sí o ejecutándose en paralelo. Cada uno de estos problemas internos tiene su propio flujo de contexto : su propio conjunto de información del que intenta aprender.
Esta perspectiva implica que los métodos de aprendizaje profundo existentes funcionan básicamente comprimiendo sus flujos de contexto internos. Más importante aún, el aprendizaje anidado revela una nueva dimensión para el diseño de modelos, permitiéndonos construir componentes de aprendizaje con mayor profundidad computacional.
Para ilustrar este paradigma, analizamos el concepto de memoria asociativa : la capacidad de mapear y recordar una cosa en función de otra (como recordar un nombre cuando ves una cara).
- Demostramos que el proceso de entrenamiento en sí, específicamente el proceso de retropropagación , puede modelarse como una memoria asociativa. El modelo aprende a asignar un punto de datos dado al valor de su error local, lo que sirve como medida de cuán “sorprendente” o inesperado fue dicho punto de datos.
- De manera similar, siguiendo estudios previos (por ejemplo, Miras ), los componentes arquitectónicos clave, como el mecanismo de atención en los transformadores , también pueden formalizarse como módulos de memoria asociativa simples que aprenden el mapeo entre tokens en una secuencia.

La estructura uniforme y reutilizable, así como la actualización multitemporal en el cerebro, son componentes clave del aprendizaje continuo en humanos. El aprendizaje anidado permite actualizaciones multitemporales para cada componente del cerebro, a la vez que demuestra que arquitecturas conocidas como transformadores y módulos de memoria son, de hecho, capas lineales con diferentes frecuencias de actualización.
Al definir una frecuencia de actualización, es decir, la frecuencia con la que se ajustan los pesos de cada componente, podemos ordenar estos problemas de optimización interconectados en «niveles». Este conjunto ordenado constituye la base del paradigma del aprendizaje anidado.
Poniendo en práctica el aprendizaje anidado
La perspectiva del aprendizaje anidado nos brinda de inmediato formas basadas en principios para mejorar los algoritmos y arquitecturas existentes:
Optimizadores profundos
Dado que el aprendizaje anidado considera a los optimizadores (p. ej., los optimizadores basados en momentum) como módulos de memoria asociativa, nos permite aplicarles principios desde la perspectiva de la memoria asociativa. Observamos que muchos optimizadores estándar se basan en la simple similitud del producto escalar (una medida de la similitud de dos vectores calculada mediante la suma de los productos de sus componentes correspondientes), cuya actualización no tiene en cuenta la relación entre las diferentes muestras de datos. Al cambiar el objetivo subyacente del optimizador a una métrica de pérdida más estándar, como la pérdida de regresión L2 (una función de pérdida común en tareas de regresión que cuantifica el error sumando los cuadrados de las diferencias entre los valores predichos y los verdaderos), derivamos nuevas formulaciones para conceptos fundamentales como el momentum, haciéndolos más resistentes a los datos imperfectos.
Sistemas de memoria continua
En un Transformer estándar, el modelo de secuencia actúa como memoria a corto plazo, almacenando el contexto inmediato, mientras que las redes neuronales de prealimentación actúan como memoria a largo plazo, almacenando el conocimiento previo al entrenamiento. El paradigma de Aprendizaje Anidado extiende este concepto a lo que llamamos un “sistema de memoria continua” (CMS), donde la memoria se concibe como un espectro de módulos, cada uno actualizándose con una frecuencia específica. Esto crea un sistema de memoria mucho más rico y eficaz para el aprendizaje continuo.
Esperanza: Una arquitectura automodificable con memoria continua
Como prueba de concepto, utilizamos los principios de aprendizaje anidado para diseñar Hope, una variante de la arquitectura Titans . Las arquitecturas Titans son módulos de memoria a largo plazo que priorizan los recuerdos según su grado de sorpresa. A pesar de su potente gestión de memoria, solo tienen dos niveles de actualización de parámetros, lo que resulta en un aprendizaje contextual de primer orden. Hope, en cambio, es una arquitectura recurrente automodificable que puede aprovechar niveles ilimitados de aprendizaje contextual y que, además, se complementa con bloques CMS para escalar a ventanas de contexto más amplias. Esencialmente, puede optimizar su propia memoria mediante un proceso autorreferencial , creando una arquitectura con niveles de aprendizaje infinitos y en bucle.
Experimentos
Realizamos experimentos para evaluar la eficacia de nuestros optimizadores profundos y el rendimiento de Hope en tareas de modelado lingüístico, razonamiento de contexto largo, aprendizaje continuo e incorporación de conocimiento. Los resultados completos están disponibles en nuestro artículo .
Resultados
Nuestros experimentos confirman el poder del aprendizaje anidado, el diseño de sistemas de memoria continua y los Titanes automodificables.
En un conjunto diverso de tareas de modelado de lenguaje y razonamiento de sentido común de uso común y público, la arquitectura Hope demuestra menor perplejidad y mayor precisión en comparación con los modelos recurrentes modernos y los transformadores estándar.
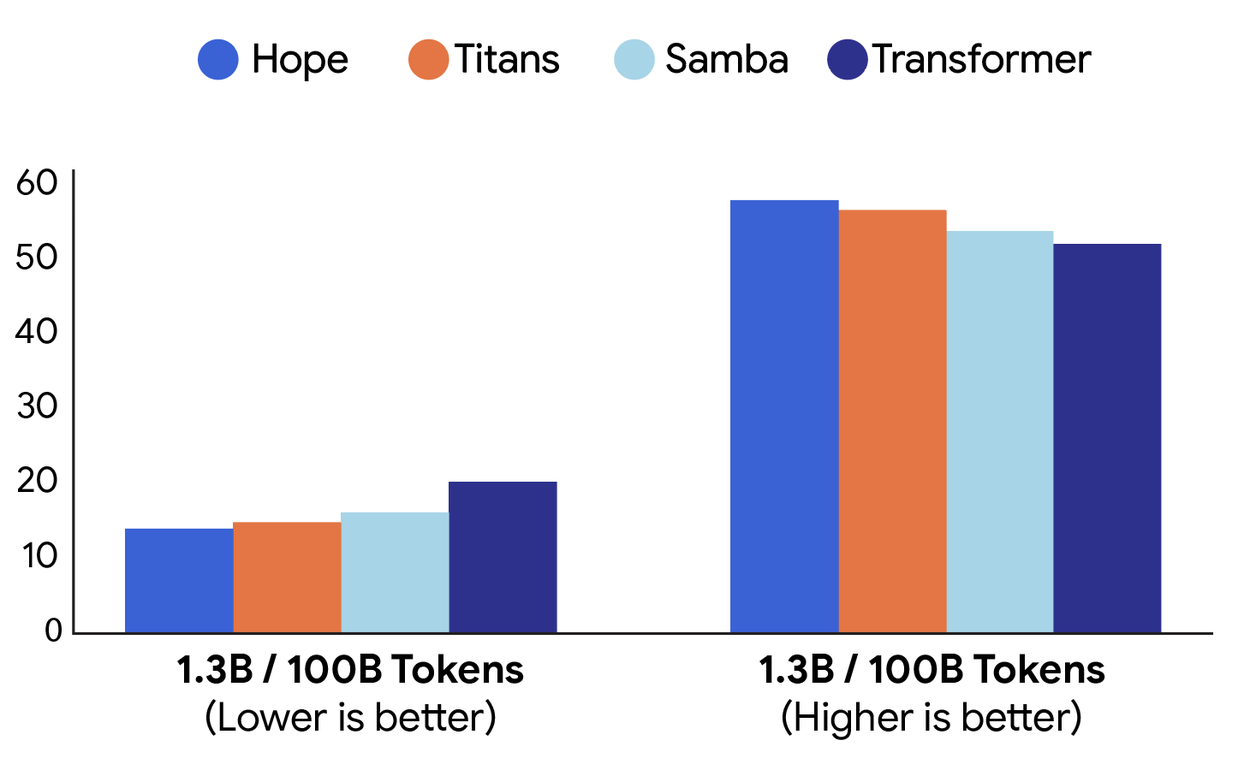
Comparación del rendimiento en tareas de modelado de lenguaje ( perplejidad ; izquierda) y razonamiento de sentido común (precisión; derecha) entre diferentes arquitecturas: Hope, Titans, Samba y un Transformer de referencia.
Hope demuestra una gestión de memoria superior en tareas posteriores de Needle-In-Haystack (NIAH) de contexto largo, lo que demuestra que los CMS ofrecen una forma más eficiente y eficaz de manejar secuencias extendidas de información.
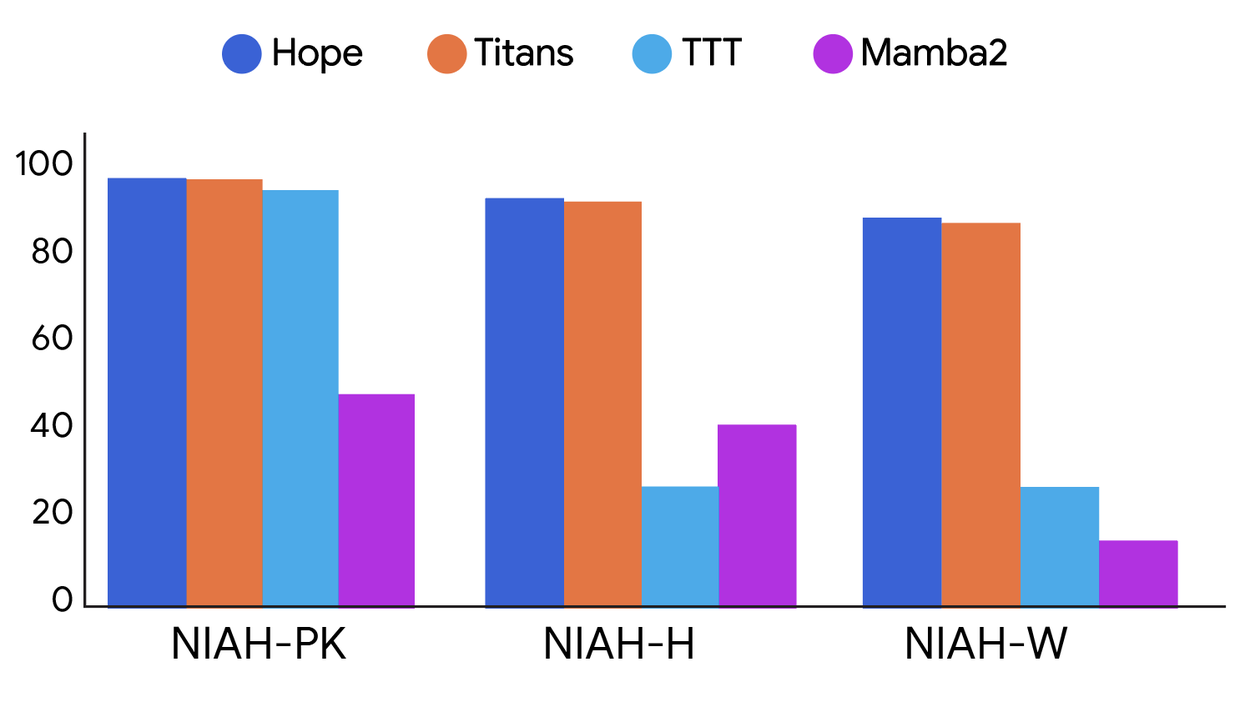
Comparación del rendimiento en tareas de contexto largo con diferentes niveles de dificultad entre distintas arquitecturas: Hope, Titans, TTT y Mamba2 . NIAH-PK, NIAH-H y NIAH-W son tareas de búsqueda de una aguja en un pajar con clave de acceso, número y palabra, respectivamente.
Conclusión
El paradigma del aprendizaje anidado representa un avance en nuestra comprensión del aprendizaje profundo. Al considerar la arquitectura y la optimización como un sistema único y coherente de problemas de optimización anidados, se abre una nueva dimensión para el diseño, apilando múltiples niveles. Los modelos resultantes, como la arquitectura Hope, demuestran que un enfoque basado en principios para unificar estos elementos puede dar lugar a algoritmos de aprendizaje más expresivos, capaces y eficientes.
Creemos que el paradigma del Aprendizaje Anidado ofrece una base sólida para cerrar la brecha entre la naturaleza limitada y olvidadiza de los LLM actuales y la notable capacidad de aprendizaje continuo del cerebro humano. Nos entusiasma que la comunidad investigadora explore esta nueva dimensión y nos ayude a construir la próxima generación de IA autosuperadora.
Fuente: https://research.google/blog/introducing-nested-learning-a-new-ml-paradigm-for-continual-learning/