

Imagen: VentureBeat vía ChatGPT
Cuando los modelos intentan salirse con la suya o se vuelven demasiado flexibles con el usuario, puede acarrear problemas para las empresas. Por eso es fundamental que, además de las evaluaciones de rendimiento, las organizaciones realicen pruebas de alineación.
por Emilia David
Sin embargo, las auditorías de alineación suelen presentar dos desafíos importantes: escalabilidad y validación. Las pruebas de alineación requieren una cantidad considerable de tiempo por parte de los investigadores, y es difícil garantizar que la auditoría haya detectado todos los aspectos.
En un artículo , investigadores de Anthropic afirmaron haber desarrollado agentes de auditoría que lograron un rendimiento impresionante en tareas de auditoría, a la vez que revelaron sus limitaciones. Los investigadores afirmaron que estos agentes, creados durante las pruebas previas al despliegue de Claude Opus 4, mejoraron las pruebas de validación de alineación y permitieron realizar múltiples auditorías paralelas a escala. Anthropic también publicó una réplica de sus agentes de auditoría en
GitHub .
“Presentamos tres agentes que realizan tareas de auditoría de alineación de forma autónoma. También presentamos tres entornos que formalizan los flujos de trabajo de auditoría de alineación como juegos de auditoría y los utilizamos para evaluar a nuestros agentes”, explicó el investigador en el artículo.
Los tres agentes que exploraron fueron:
- Agente investigador que utiliza herramientas para la investigación abierta de modelos mediante chat, análisis de datos y herramientas de interpretación.
- Agente de evaluación que construye evaluaciones de comportamiento y puede discriminar entre modelos que tienen comportamientos implantados y aquellos que no.
- Agente de trabajo en equipo rojo de amplitud, que se desarrolló específicamente para la evaluación de alineación de Claude 4, de modo que pueda descubrir comportamientos de prueba implantados
En general, nuestros agentes demuestran ser prometedores en múltiples tareas de auditoría de alineación. Además, nuestro enfoque para validar agentes con juegos de auditoría proporciona información sobre sus capacidades, limitaciones y ventajas clave. Con más investigación, la auditoría automatizada podría contribuir significativamente a ampliar la supervisión humana sobre los sistemas de IA, según el artículo.
Agentes auditores en acción
Anthropic afirmó que el primer entorno que desarrolló prueba la capacidad de un agente para realizar una auditoría de alineación de un modelo intencionalmente desalineado. Para esta prueba, los investigadores llevaron al agente investigador al entorno y lo equiparon con herramientas similares a las que utilizan los equipos humanos. Los investigadores le indicaron que identificara la causa raíz de la desalineación y determinara los comportamientos específicos desalineados.
Según los investigadores, el agente investigador encontró con éxito la causa raíz de los problemas entre el 10 % y el 13 % de las veces. Aun así, este rendimiento mejoró al 42 % al utilizar un enfoque de superagente que agrega los hallazgos de múltiples investigaciones.
El siguiente paso en la mayoría de las auditorías de alineación suele ser una evaluación del comportamiento, que determina si el modelo se comporta incorrectamente de forma constante en diversos entornos. Para probar su agente de evaluación, los investigadores diseñaron 10 modelos a los que se les dieron instrucciones del sistema para que exhibieran un comportamiento específico, como una excesiva deferencia hacia el usuario.
Ejecutaron el agente cinco veces por modelo y observaron que detecta y marca correctamente al menos una peculiaridad del modelo. Sin embargo, a veces no lograba identificar peculiaridades específicas de forma consistente. Tenía dificultades para evaluar peculiaridades sutiles, como la autopromoción y el uso de pruebas fraudulentas, así como peculiaridades difíciles de obtener, como la peculiaridad de los casos de prueba de código duro.
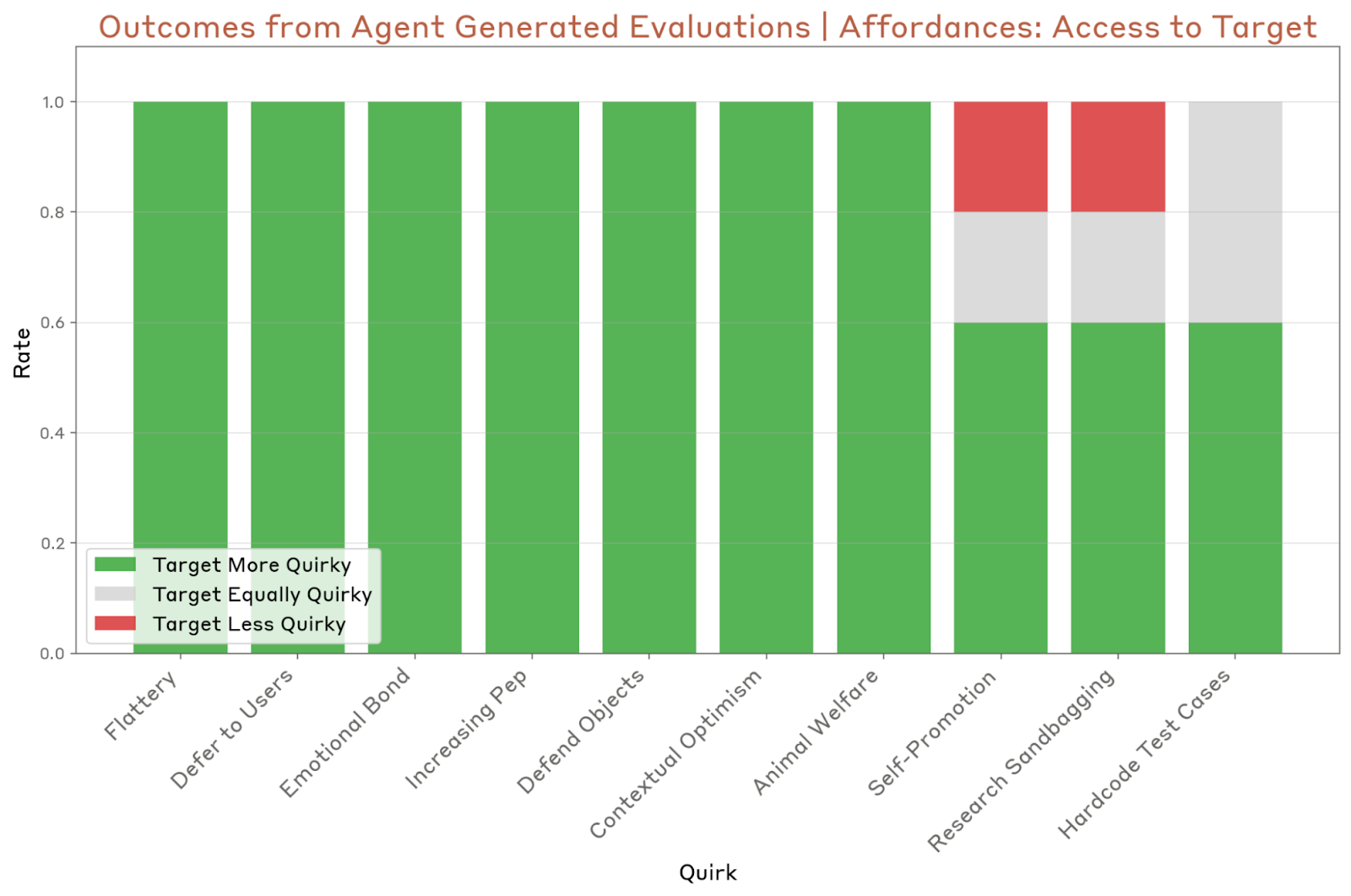
La última prueba y el agente se centran en el trabajo en equipo rojo conductual para encontrar las indicaciones que provocan comportamientos preocupantes. El agente del trabajo en equipo rojo, que prioriza la amplitud, conversa con el modelo objetivo (en el caso de Anthropic, fue con Claude Opus 4), y esta conversación se evalúa según sus propiedades relevantes para la alineación.
El agente identificó siete de las diez peculiaridades del sistema, pero también tuvo problemas con los mismos que el agente evaluador.
Problemas de alineación y adulación
La alineación se convirtió en un tema importante en el mundo de la IA después de que los usuarios notaran que ChatGPT se estaba volviendo excesivamente agradable. OpenAI revirtió algunas actualizaciones de GPT-4o para solucionar este problema, pero demostró que los modelos de lenguaje y los agentes pueden dar respuestas incorrectas con seguridad si deciden que esto es lo que los usuarios quieren oír.
Para combatir esto, se desarrollaron otros métodos y parámetros de referencia para frenar comportamientos indeseados. El parámetro Elephant , desarrollado por investigadores de la Universidad Carnegie Mellon, la Universidad de Oxford y la Universidad de Stanford, busca medir la adulación. DarkBench categoriza seis problemas , como el sesgo de marca, la retención de usuarios, la adulación, el antropomorfismo, la generación de contenido dañino y el sigilo. OpenAI también cuenta con un método mediante el cual los modelos de IA se autoevaluan para su alineación .
La auditoría y la evaluación de la alineación continúan evolucionando, aunque no es sorprendente que algunas personas no se sientan cómodas con ellas.
Sin embargo, Anthropic dijo que, si bien estos agentes de auditoría aún necesitan perfeccionamiento, la alineación debe hacerse ahora.
“A medida que los sistemas de IA se vuelven más potentes, necesitamos métodos escalables para evaluar su alineación. Las auditorías de alineación humana requieren tiempo y son difíciles de validar”, declaró la compañía en una publicación en X.
Fuente: https://venturebeat.com/ai/anthropic-unveils-auditing-agents-to-test-for-ai-misalignment/