

El camino hacia los recientes sistemas de IA avanzados ha consistido más en construir sistemas más grandes que en lograr avances científicos.
Durante gran parte de la historia de la inteligencia artificial, muchos investigadores previeron que la creación de sistemas verdaderamente capaces requeriría una larga serie de avances científicos: algoritmos revolucionarios, profundos conocimientos sobre la cognición humana o avances fundamentales en nuestra comprensión del cerebro. Si bien los avances científicos han influido, los avances recientes en IA han revelado una perspectiva inesperada: gran parte de la reciente mejora en las capacidades de IA se ha debido simplemente a la ampliación de los sistemas de IA existentes. 1
En este caso, escalar implica implementar mayor potencia computacional, usar conjuntos de datos más grandes y construir modelos más grandes. Este enfoque ha funcionado sorprendentemente bien hasta ahora 2
Hace tan solo unos años, los sistemas de IA de vanguardia tenían dificultades con tareas básicas como contar 3
Hoy, pueden resolver problemas matemáticos complejos, desarrollar software, crear imágenes y videos extremadamente realistas y debatir temas académicos.
Este artículo ofrece una breve descripción general del crecimiento de la IA en los últimos años. Los datos provienen de Epoch , una organización que analiza las tendencias en informática, datos e inversiones para comprender el futuro de la IA. Epoch mantiene el conjunto de datos más completo sobre modelos de IA y publica periódicamente cifras clave sobre su crecimiento y evolución.
¿Qué es el escalamiento en los modelos de IA?
Analicemos brevemente qué significa escalar en IA. Escalar consiste en aumentar tres aspectos principales durante el entrenamiento, que normalmente deben crecer juntos:
• La cantidad de datos utilizados para entrenar la IA;
• El tamaño del modelo, medido en “parámetros”;
• Los recursos computacionales, a menudo llamados “computación” en IA.
La idea es simple pero poderosa: los sistemas de IA más grandes, entrenados con más datos y que utilizan más recursos computacionales, tienden a tener un mejor rendimiento . Incluso sin cambios sustanciales en los algoritmos, este enfoque suele generar un mejor rendimiento en muchas tareas. 6
Esta es otra razón por la que esto es importante: a medida que los investigadores amplían la escala de estos sistemas de IA, no solo mejoran en las tareas en las que fueron entrenados, sino que a veces pueden llevarlos a desarrollar nuevas habilidades que no tenían en una escala más pequeña. 7 Por ejemplo, los modelos de lenguaje inicialmente tuvieron dificultades con pruebas aritméticas simples como la suma de tres dígitos, pero los modelos más grandes pudieron manejarlas fácilmente una vez que alcanzaron cierto tamaño. 8 La transición no fue una mejora gradual y suave, sino un salto más abrupto en las capacidades.
Este aumento abrupto de la capacidad, en lugar de una mejora constante, puede ser preocupante. Si, por ejemplo, los modelos desarrollan repentinamente comportamientos inesperados y potencialmente dañinos simplemente por aumentar de tamaño, sería más difícil anticiparlos y controlarlos.
Esto hace que el seguimiento de estas métricas sea importante.
¿Cuáles son los tres componentes para ampliar los modelos de IA?
Datos: ampliación de los datos de entrenamiento
Una forma de ver los modelos de IA actuales es considerarlos como sistemas de reconocimiento de patrones muy sofisticados. Funcionan identificando y aprendiendo de las regularidades estadísticas en el texto, las imágenes u otros datos con los que se entrenan. Cuantos más datos tenga acceso el modelo, más podrá aprender sobre los matices y las complejidades del dominio de conocimiento en el que está diseñado para operar .
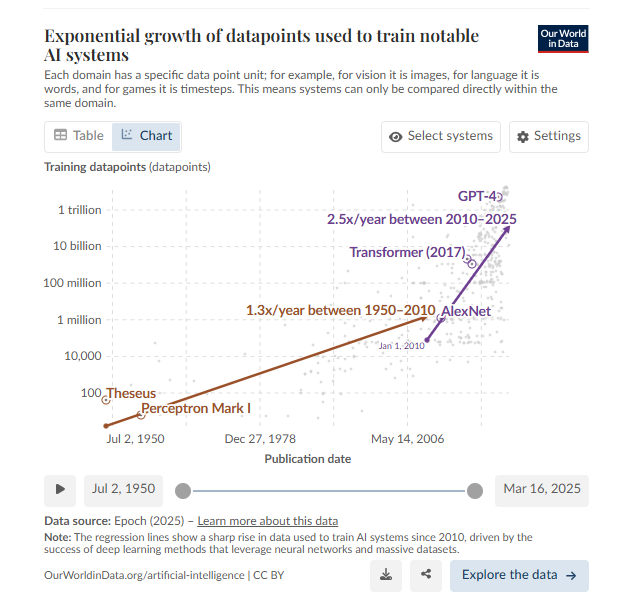
En 1950, Claude Shannon construyó uno de los primeros ejemplos de IA: un ratón robótico llamado Teseo, capaz de recordar su recorrido por un laberinto mediante sencillos circuitos de relés. Cada pared con la que Teseo chocaba se convertía en un punto de datos, lo que le permitía aprender la ruta correcta. El número total de paredes o puntos de datos era 40. Puedes encontrar este punto de datos en la gráfica; es el primero.
Mientras que Teseo almacenaba estados binarios simples en circuitos de relé, los sistemas de IA modernos utilizan vastas redes neuronales, que pueden aprender patrones y relaciones mucho más complejos y, así, procesar miles de millones de puntos de datos.
Todos los modelos de IA recientes más destacados, especialmente los grandes y de vanguardia, se basan en grandes cantidades de datos de entrenamiento. Con el eje Y en escala logarítmica, el gráfico muestra que los datos utilizados para entrenar modelos de IA han crecido exponencialmente. De 40 puntos de datos para Theseus a billones de puntos de datos para los sistemas modernos más grandes en poco más de siete décadas.
Desde 2010, los datos de entrenamiento se han duplicado aproximadamente cada nueve o diez meses. Este rápido crecimiento se puede observar en el gráfico, representado por la línea morada que se extiende desde principios de 2010 hasta octubre de 2024, el último dato al momento de escribir este artículo. 10
Los conjuntos de datos utilizados para entrenar modelos lingüísticos de gran tamaño, en particular, han experimentado un crecimiento aún más rápido, triplicándose su tamaño cada año desde 2010. Estos modelos procesan el texto dividiéndolo en tokens (unidades básicas que el modelo puede codificar y comprender). Un token no corresponde directamente a una palabra, pero, en promedio, tres palabras en inglés corresponden a unos cuatro tokens.
Se estima que GPT-2, lanzado en 2019, se entrenó con 4 mil millones de tokens, aproximadamente el equivalente a 3 mil millones de palabras. Para poner esto en perspectiva, en septiembre de 2024, la Wikipedia en inglés contenía alrededor de 4.6 mil millones de palabras.<sup> 11</sup> En comparación, GPT-4, lanzado en 2023, se entrenó con casi 13 billones de tokens, o aproximadamente 9,75 billones de palabras. <sup>12</sup> Esto significa que los datos de entrenamiento de GPT-4 equivalían a más de 2000 veces la cantidad de texto de toda la Wikipedia en inglés.
A medida que utilizamos más datos para entrenar sistemas de IA, podríamos agotar el material de alta calidad generado por humanos, como libros, artículos y trabajos de investigación. Algunos investigadores predicen que podríamos agotar el material de entrenamiento útil en las próximas décadas . 13 Si bien los propios modelos de IA pueden generar grandes cantidades de datos, entrenar la IA con materiales generados por máquinas podría generar problemas, haciendo que los modelos sean menos precisos y más repetitivos. 14
Parámetros: ampliar el tamaño del modelo
Aumentar la cantidad de datos de entrenamiento permite a los modelos de IA aprender de mucha más información que nunca. Sin embargo, para detectar los patrones en estos datos y aprender eficazmente, los modelos necesitan lo que se denomina “parámetros”. Los parámetros son como perillas que se pueden ajustar para mejorar la forma en que el modelo procesa la información y realiza predicciones. A medida que aumenta la cantidad de datos de entrenamiento, los modelos necesitan mayor capacidad para capturar todos los detalles de los datos de entrenamiento. Esto significa que los conjuntos de datos más grandes suelen requerir que los modelos tengan más parámetros para aprender eficazmente.
Las primeras redes neuronales tenían cientos o miles de parámetros. Con su sencillo circuito de aprendizaje de laberintos, Theseus era un modelo con tan solo 40 parámetros, equivalentes al número de paredes que encontraba. Modelos de gran tamaño recientes, como GPT-3, cuentan con hasta 175 mil millones de parámetros.15
Aunque la cifra bruta pueda parecer elevada, se traduce aproximadamente en 700 GB si se almacena en un disco, que es fácilmente gestionable por las computadoras actuales.
El gráfico muestra cómo el número de parámetros en los modelos de IA se ha disparado con el tiempo. Desde 2010, el número de parámetros de los modelos de IA se ha duplicado aproximadamente cada año. La estimación más alta de parámetros registrada por Epoch es de 1,6 billones en el modelo QMoE.

Si bien los modelos de IA más grandes pueden hacer más, también enfrentan algunos problemas. Uno de los principales se denomina “sobreajuste”. Esto ocurre cuando una IA se optimiza demasiado para procesar los datos específicos con los que fue entrenada, pero tiene dificultades con los nuevos datos. Para combatir esto, los investigadores emplean dos estrategias: implementar técnicas especializadas para un aprendizaje más generalizado y ampliar el volumen y la diversidad de los datos de entrenamiento.
Computación: ampliación de los recursos computacionales
A medida que los modelos de IA aumentan en datos y parámetros, requieren recursos computacionales exponencialmente mayores. Estos recursos, comúnmente denominados “computación” en la investigación de IA, suelen medirse en operaciones de punto flotante (FLOP), donde cada FLOP representa un único cálculo aritmético, como una suma o una multiplicación.
Las necesidades computacionales para el entrenamiento de IA han cambiado drásticamente con el tiempo. Con un número modesto de datos y parámetros, los primeros modelos podían entrenarse en cuestión de horas con hardware simple. Los modelos más avanzados actuales requieren cientos de días de computación continua, incluso con decenas de miles de computadoras especializadas.
El gráfico muestra que el cómputo utilizado para entrenar cada modelo de IA (mostrado en el eje vertical) ha aumentado de forma constante y exponencial en las últimas décadas. De 1950 a 2010, el cómputo se duplicó aproximadamente cada dos años. Sin embargo, desde 2010, este crecimiento se ha acelerado drásticamente, duplicándose ahora aproximadamente cada seis meses, y el modelo con mayor intensidad de cómputo alcanza los 50 mil millones de petaFLOP al momento de escribir este artículo. 16

Para poner esta escala en perspectiva, una sola tarjeta gráfica de alta gama como la NVIDIA GeForce RTX 3090, ampliamente utilizada en la investigación de IA, funcionando a plena capacidad durante un año entero completaría solo 1,1 millones de cálculos de petaFLOP . 50 mil millones de petaFLOP son aproximadamente 45.455 veces más que eso.
Lograr cálculos a esta escala requiere grandes inversiones en energía y hardware. Se estima que entrenar algunos de los modelos más recientes cuesta hasta 40 millones de dólares , lo que lo hace accesible solo para unas pocas organizaciones con una sólida financiación.
Los cálculos, los datos y los parámetros tienden a escalarse al mismo tiempo
El cálculo, los datos y los parámetros están estrechamente interconectados a la hora de escalar modelos de IA. Cuantos más datos se entrenan, más cosas hay que aprender. Por lo tanto, para gestionar la creciente complejidad de los datos, los modelos de IA requieren más parámetros para aprender de sus diversas características. Añadir más parámetros al modelo implica que necesita más recursos computacionales durante el entrenamiento.
Esta interdependencia implica que los datos, los parámetros y el cómputo deben crecer simultáneamente. Los conjuntos de datos públicos más grandes de la actualidad son aproximadamente diez veces más grandes que los que utilizan la mayoría de los modelos de IA; algunos contienen cientos de billones de palabras. Sin embargo, sin suficientes cómputos y parámetros, los modelos de IA aún no pueden usarlos para el entrenamiento.
¿Qué podemos aprender de estas tendencias para el futuro de la IA?
Las empresas buscan grandes inversiones financieras para desarrollar y escalar sus modelos de IA, con un enfoque creciente en las tecnologías de IA generativa. Al mismo tiempo, el hardware clave utilizado para el entrenamiento (las GPU) es cada vez más económico y potente, y su velocidad de procesamiento se duplica aproximadamente cada 2,5 años por cada dólar invertido. <sup>17</sup> Algunas organizaciones también están aprovechando más recursos computacionales no solo para el entrenamiento de modelos de IA, sino también durante la inferencia (la fase en la que los modelos generan respuestas), como lo ilustra el último modelo o1 de OpenAI .
Estos avances podrían contribuir a la creación de tecnologías de IA más sofisticadas de forma más rápida y económica. A medida que las empresas invierten más y el hardware necesario mejora , podríamos observar mejoras significativas en las capacidades de la IA, incluyendo nuevas capacidades potencialmente inesperadas.
Dado que estos cambios podrían tener efectos importantes en nuestra sociedad, es fundamental que los monitoricemos y comprendamos con antelación. Para ello, Our World in Data actualizará mensualmente métricas clave, como el crecimiento de los recursos computacionales, el volumen de datos de entrenamiento y los parámetros de los modelos. Estas actualizaciones ayudarán a monitorizar la rápida evolución de las tecnologías de IA y proporcionarán información valiosa sobre su trayectoria.
Acerca del autor

Veronika se unió a Our World in Data en 2023. Recientemente terminó su doctorado en neurociencia computacional en la Universidad de Oxford y anteriormente trabajó en el equipo de periodismo de datos del Financial Times.