

No todos los puntos de referencia son iguales. A medida que los modelos de IA evolucionan, los investigadores advierten que las métricas actuales no están diseñadas para la sostenibilidad ni la confianza.
por Sharon Fisher
“Lo que no se puede medir, no se puede gestionar.”

Esta cita popular (a menudo atribuida a Peter Drucker, aunque probablemente apócrifa) resume con precisión las perspectivas actuales de los investigadores sobre la inteligencia artificial. Buscan maneras de medir el rendimiento de la IA para que los diferentes sistemas se puedan comparar y gestionar con mayor facilidad.
La gran pregunta: ¿Qué deberían medir los benchmarks de IA?
Un vistazo a los puntos de referencia de IA más comunes
En pocas palabras, un benchmark de IA es una forma de medir el rendimiento de un sistema de IA. Existen muchos tipos de benchmarks y dependen del tipo de sistema de IA y de cómo se utiliza.
Inferencia de MLPerf
Este conjunto de referencia abarca tanto los sistemas de centros de datos como los de borde y está diseñado para medir la rapidez con la que los sistemas pueden ejecutar modelos de IA y aprendizaje automático en una variedad de cargas de trabajo, según el consorcio de ingeniería de IA MLCommons .
“El conjunto de indicadores de referencia de código abierto y revisado por pares crea igualdad de condiciones para la competencia, impulsando la innovación, el rendimiento y la eficiencia energética en toda la industria”, señaló la organización. “También proporciona información técnica crucial para los clientes que adquieren y optimizan sistemas de IA”.
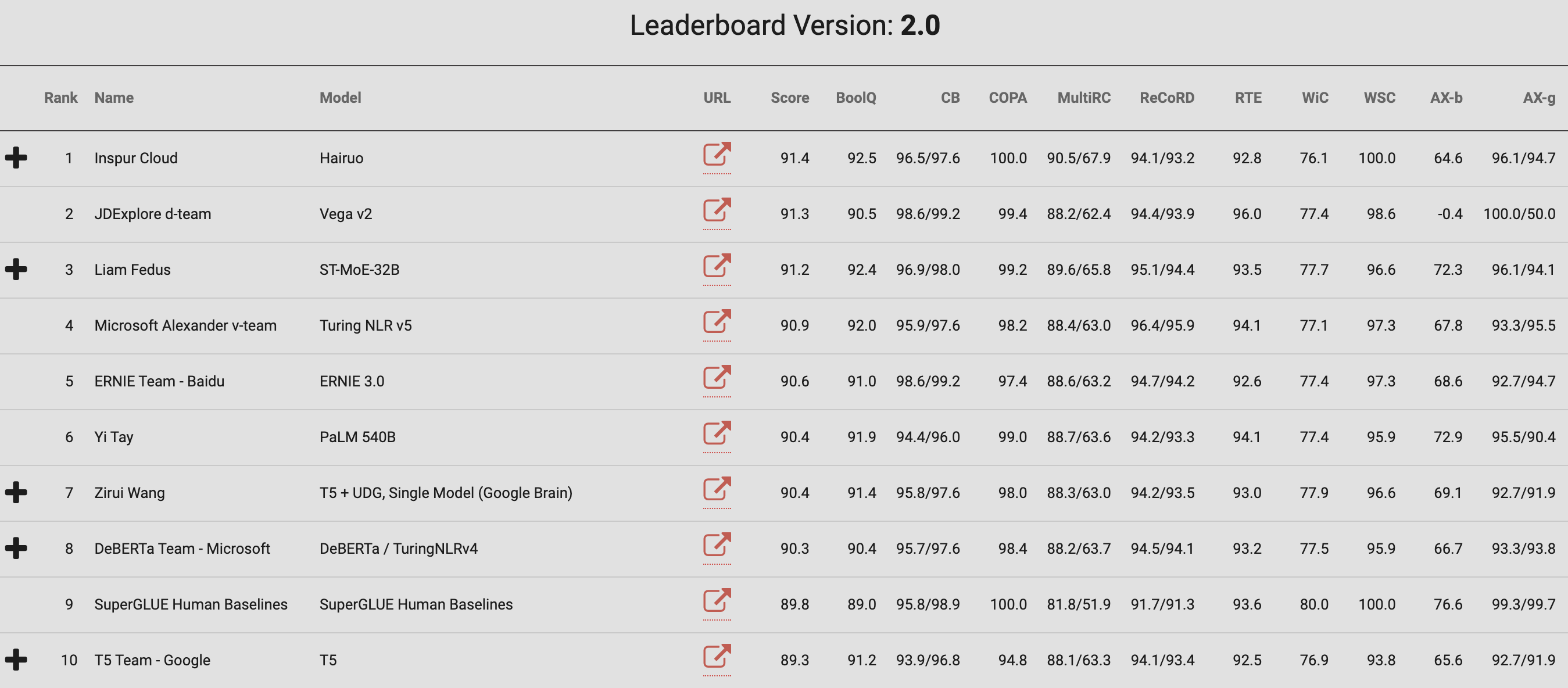
Punto de referencia de GLUE
El punto de referencia General Language Understanding Evaluation (GLUE) es una colección de recursos para entrenar, evaluar y analizar sistemas de comprensión del lenguaje natural , según la organización detrás de las métricas.
“Las tareas de referencia se seleccionan para favorecer los modelos que comparten información entre tareas mediante el uso compartido de parámetros u otras técnicas de aprendizaje por transferencia”, afirmó la organización. “El objetivo final de GLUE es impulsar la investigación en el desarrollo de sistemas generales y robustos de comprensión del lenguaje natural”.
La organización también ha lanzado un nuevo punto de referencia, SuperGLUE, que incorpora las lecciones aprendidas del original. Este punto de referencia incluye un nuevo conjunto de tareas de comprensión del lenguaje más difíciles, recursos mejorados y una nueva tabla de clasificación pública.
Punto de referencia de MMLU
El parámetro de Comprensión Masiva del Lenguaje Multitarea (MMLU) está diseñado para medir la precisión multitarea de un modelo de IA. Incluye 57 tareas que abarcan temas de ciencias sociales, matemáticas, humanidades y más, con un nivel de dificultad que va desde elemental hasta avanzado.
Cuando se publicó este punto de referencia en 2020, los investigadores responsables observaron que la mayoría de los modelos más recientes tenían una precisión casi aleatoria, aunque el modelo GPT-3 mejoró con respecto a los cambios aleatorios en casi un 20 %. Aun así, en cada una de las 57 tareas, los mejores modelos aún necesitaban mejoras sustanciales antes de alcanzar una precisión de nivel experto.
No todos los benchmarks de IA son iguales. Investigadores de Stanford observaron que, de los 24 benchmarks evaluados, el benchmark MMLU obtuvo la puntuación más baja en usabilidad. Por otro lado, otro benchmark comúnmente utilizado, GPQA (Graduate-Level Google-Proof Q&A Benchmark), obtuvo una puntuación mucho más alta.
Los investigadores señalaron que «es habitual que los desarrolladores informen los resultados tanto de MMLU como de GPQA sin explicar sus limitaciones ni diferencias de calidad; por ejemplo, al introducir modelos importantes como GPT-4, Claude-3 y Gemini. De igual forma, el Instituto de Seguridad de la IA del Reino Unido ha desarrollado un marco para evaluar los LLM que incluye tanto MMLU como GPQA, mientras que la Ley de IA de la UE menciona específicamente el uso de dichos puntos de referencia. Esto significa que los responsables políticos y otros actores a menudo se basan en evaluaciones contradictorias e incluso engañosas».
Por qué los puntos de referencia de la IA pueden ser engañosos
No es inusual que las empresas se basen en benchmarks para determinar la calidad de un producto de hardware o software. Sin embargo, según una revisión exhaustiva de la literatura sobre benchmarks de IA , estos terminan influyendo en la IA mucho más que en otros productos informáticos.
“Los puntos de referencia son profundamente políticos, performativos y generativos en el sentido de que no describen ni miden pasivamente cómo son las cosas en el mundo, sino que participan activamente en su configuración”, señalaron los autores. “Esto sucede a medida que los puntos de referencia influyen continuamente en cómo se entrenan, perfeccionan y aplican los modelos de IA, prácticas con amplios efectos políticos, económicos y culturales”.
En total, encontraron nueve categorías principales de problemas con los puntos de referencia:
- Recopilación, anotación y documentación de datos
- Validez de constructo débil y afirmaciones epistemológicas
- Contexto sociocultural y brecha
- Diversidad y alcance de referencia limitados
- Raíces económicas, competitivas y comerciales
- Manipulación, manipulación y sobreajuste de la medida (también conocido como sobreajuste)
- Dudosa verificación comunitaria y dependencias de ruta
- Desarrollo rápido de IA y saturación de puntos de referencia
- Complejidad de la IA y desconocidos desconocidos
Los autores también señalaron una variedad de posibles soluciones, entre ellas:
- Garantías de seguridad similares a las que se utilizan en automóviles, aviones, dispositivos médicos y medicamentos.
- Ocultar conjuntos de datos de entrenamiento de referencia o utilizar “referencias dinámicas” para contrarrestar los riesgos de manipulación y contaminación de datos
- Agregación de tareas de evaluación en puntos de referencia multitarea únicos para aumentar la confiabilidad de los resultados de las pruebas
- Optar por métodos de evaluación que involucren directamente a interrogadores humanos en lugar de métricas cuantitativas
“Identificamos especialmente la necesidad de nuevas formas de indicar en qué índices de referencia confiar”, concluyó el análisis. “No necesitamos necesariamente métricas y métodos de referencia estandarizados. Pero sí necesitamos métodos estandarizados para evaluar la fiabilidad de los índices de referencia desde una perspectiva aplicada y regulatoria”.
Finalmente, los autores identificaron una fuerte brecha de incentivos en el uso de ciertos puntos de referencia: los investigadores están interesados en el desarrollo de métodos y la lógica “rápida” de la publicación académica, las corporaciones tienen interés económico y los reguladores consideran la utilidad práctica y los posibles efectos posteriores.
La búsqueda de métricas de IA más inteligentes
Algunos sugieren que diferentes métodos para evaluar el rendimiento de la IA podrían ser más útiles. Por ejemplo, una persona común que consulte las pruebas de rendimiento de automóviles podría encontrar el consumo de combustible más útil que el tiempo de aceleración de 0 a 100 km/h.
De manera similar, con el enfoque creciente en la cantidad y el costo de la electricidad que requieren los sistemas de IA , existe un creciente interés en comparar los modelos de IA según la cantidad de energía que utilizan.
Un ejemplo es el AI Energy Score , anunciado por Salesforce, Hugging Face, Cohere y Carnegie Mellon University en febrero de 2025. El objetivo del proyecto es crear una clasificación para los sistemas de IA similar a la clasificación Energy Star para electrodomésticos, con una tabla de clasificación pública que muestre los resultados.
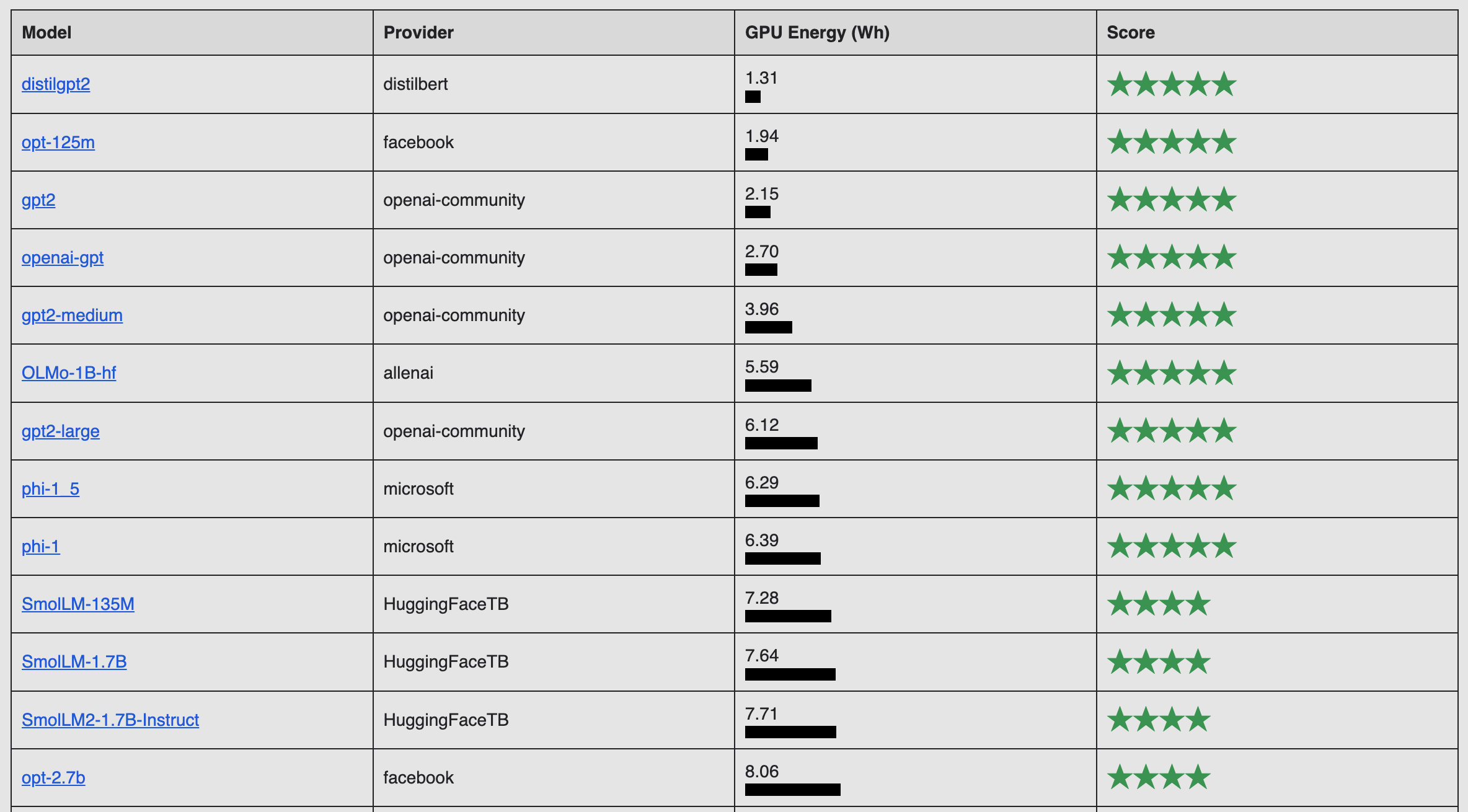
Sin embargo, de la misma manera que los autos energéticamente eficientes no ayudan si la gente realmente quiere conducir SUV, no está claro cuán útiles serán los puntos de referencia de IA en eficiencia energética, dijo Alex de Vries, fundador de Digiconomist y candidato a doctorado en la Vrije Universiteit Amsterdam, que ha estado estudiando este tema durante la última década.
“En IA, existe una gran relación entre el tamaño final de los modelos que se utilizan, su rendimiento y los recursos consumidos”, afirmó de Vries. “En general, cuanto más grande, mejor. Si se tiene un modelo más grande, tendrá mejor rendimiento, pero consumirá más recursos. Con un modelo más pequeño, se sacrificará el rendimiento. Un parámetro de referencia de eficiencia no será muy útil para abordar esta dinámica”.
De hecho, incluso con un modelo eficiente, de Vries predijo que se seguirán añadiendo parámetros y datos para mejorar su rendimiento y competitividad en el mercado, pero, en el proceso, se reducirá su eficiencia. El único caso donde esta dinámica podría no darse es en mercados más pequeños y menos competitivos, donde añadir recursos adicionales al modelo podría no mejorarlo significativamente, explicó.
De Vries también señaló que los principales actores de la IA, como Microsoft y Google, parecían estar prestando menos atención a los objetivos de sostenibilidad que antes de la reciente explosión de la IA.
Las emisiones de gases de efecto invernadero de Google, por ejemplo, aumentaron un 48 % entre 2019 y 2023, alcanzando los 14,3 millones de toneladas métricas en 2023, un aumento atribuido principalmente a los centros de datos que respaldan la IA. «Microsoft también informa de un rendimiento ambiental extremadamente pésimo», declaró de Vries, «y la IA es la causa, pero no los está frenando. Lo que suceda con la sostenibilidad es una preocupación futura; ahora mismo no les preocupa».
Acerca del autor

Sharon Fisher ha escrito para revistas, periódicos y sitios web de la industria informática y empresarial durante más de 40 años y es autora de “Riding the Internet Highway”, así como de capítulos en varios otros libros. Es licenciada en informática por el Instituto Politécnico Rensselaer y tiene una maestría en administración pública por la Universidad Estatal de Boise. Es nómada digital desde 2020 y ha vivido en 18 países.
Fuente: https://www.vktr.com/ai-market/the-benchmark-trap-why-ais-favorite-metrics-might-be-misleading-us/