

Realizamos un ensayo controlado aleatorio (ECA) para comprender cómo las herramientas de IA de principios de 2025 afectan la productividad de los desarrolladores de código abierto experimentados que trabajan en sus propios repositorios. Sorprendentemente, descubrimos que cuando los desarrolladores usan herramientas de IA, tardan un 19 % más que sin ellas; la IA los ralentiza.
Consideramos este resultado como una instantánea de las capacidades de IA de principios de 2025 en un entorno relevante; a medida que estos sistemas continúan evolucionando rápidamente, planeamos seguir utilizando esta metodología para estimar la aceleración de la IA a partir de la automatización de la I+D de IA.
por Joel Becker, Nate Rush, Beth Barnes, David Rein
Motivación
Durante la codificación/pruebas de referencia de la agencia[2]Si bien han demostrado ser útiles para comprender las capacidades de la IA, suelen sacrificar el realismo en beneficio de la escala y la eficiencia: las tareas son autónomas, no requieren contexto previo para su comprensión y utilizan una evaluación algorítmica que no captura muchas capacidades importantes. Estas propiedades pueden llevar a que los benchmarks sobreestimen las capacidades de la IA. Por otro lado, dado que los benchmarks se ejecutan sin interacción humana en vivo, los modelos pueden no completar las tareas a pesar de lograr un progreso sustancial debido a pequeños cuellos de botella que una persona solucionaría durante el uso real. Esto podría llevarnos a subestimar las capacidades del modelo. En general, puede ser difícil traducir directamente las puntuaciones de los benchmarks al impacto en la práctica.
Una razón por la que nos interesa evaluar el impacto de la IA en la práctica es comprender mejor su impacto en la propia I+D en IA, lo cual puede suponer riesgos significativos. Por ejemplo, un progreso extremadamente rápido de la IA podría provocar fallos en la supervisión o las salvaguardias. Medir el impacto de la IA en la productividad de los desarrolladores de software proporciona evidencia complementaria a los indicadores de referencia que informa sobre el impacto general de la IA en la aceleración de la I+D en IA.
Metodología
Para medir directamente el impacto real de las herramientas de IA en el desarrollo de software, reclutamos a 16 desarrolladores experimentados de grandes repositorios de código abierto (con un promedio de más de 22 000 estrellas y más de un millón de líneas de código) en los que han contribuido durante varios años. Los desarrolladores proporcionan listas de problemas reales (246 en total) que serían valiosos para el repositorio: correcciones de errores, características y refactorizaciones que normalmente formarían parte de su trabajo habitual. Luego, asignamos aleatoriamente cada problema para permitir o no el uso de IA mientras trabajamos en él. Cuando se permite el uso de IA, los desarrolladores pueden usar cualquier herramienta que elijan (principalmente Cursor Pro con Claude 3.5/3.7 Sonnet, modelos de frontera en el momento del estudio); cuando se deshabilita, trabajan sin la asistencia de IA generativa. Los desarrolladores completan estas tareas (que tienen una duración promedio de dos horas cada una) mientras graban sus pantallas y luego informan ellos mismos del tiempo total de implementación que necesitaron. Pagamos a los desarrolladores 150 $ por hora como compensación por su participación en el estudio.

Resultado principal
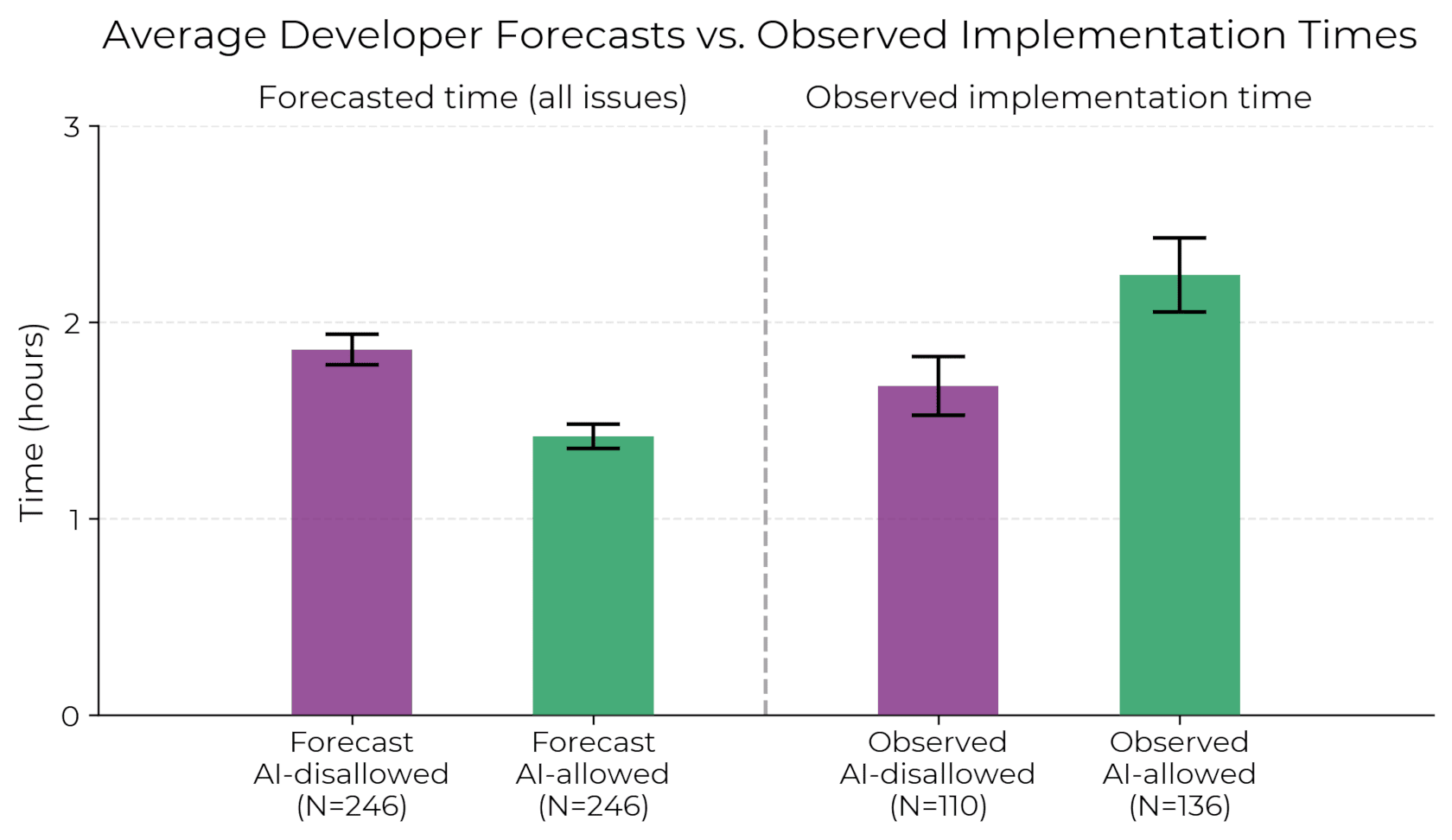
Cuando se permite a los desarrolladores usar herramientas de IA, tardan un 19 % más en completar los problemas, una ralentización significativa que contradice las creencias de los desarrolladores y las previsiones de los expertos. Esta diferencia entre la percepción y la realidad es sorprendente: los desarrolladores esperaban que la IA les acelerara un 24 %, e incluso después de experimentar la ralentización, seguían creyendo que la IA les había acelerado un 20 %.
A continuación, mostramos los tiempos promedio pronosticados por los desarrolladores y los tiempos de implementación observados: podemos ver claramente que los desarrolladores tardan mucho más cuando se les permite usar herramientas de IA.
Dada la importancia de comprender las capacidades y los riesgos de la IA y la diversidad de perspectivas sobre estos temas, consideramos importante evitar posibles malentendidos o generalizaciones excesivas de nuestros resultados. En la Tabla 2, enumeramos las afirmaciones para las que no aportamos evidencia.
| No proporcionamos evidencia de que : | Clarificación |
|---|---|
| Actualmente, los sistemas de IA no aceleran a muchos o a la mayoría de los desarrolladores de software | No afirmamos que nuestros desarrolladores o repositorios representen la mayoría o la pluralidad del trabajo de desarrollo de software. |
| Los sistemas de IA no aceleran a individuos ni a grupos en dominios distintos al del desarrollo de software | Sólo estudiamos desarrollo de software. |
| Los sistemas de IA en el futuro cercano no acelerarán a los desarrolladores en nuestro entorno exacto | Es difícil predecir el progreso, y ha habido un progreso sustancial en IA en los últimos cinco años.[3] |
| No hay formas de utilizar los sistemas de IA existentes de manera más efectiva para lograr una aceleración positiva en nuestro entorno exacto. | El cursor no toma muestras de muchos tokens de LLM, es posible que no utilice un andamiaje o una estimulación óptimos, y el entrenamiento/ajuste fino/aprendizaje de pocos intentos específico del dominio/repositorio podría producir una aceleración positiva. |
Análisis factorial
Investigamos 20 factores potenciales que podrían explicar la desaceleración y encontramos evidencia de que 5 de ellos probablemente contribuyan:
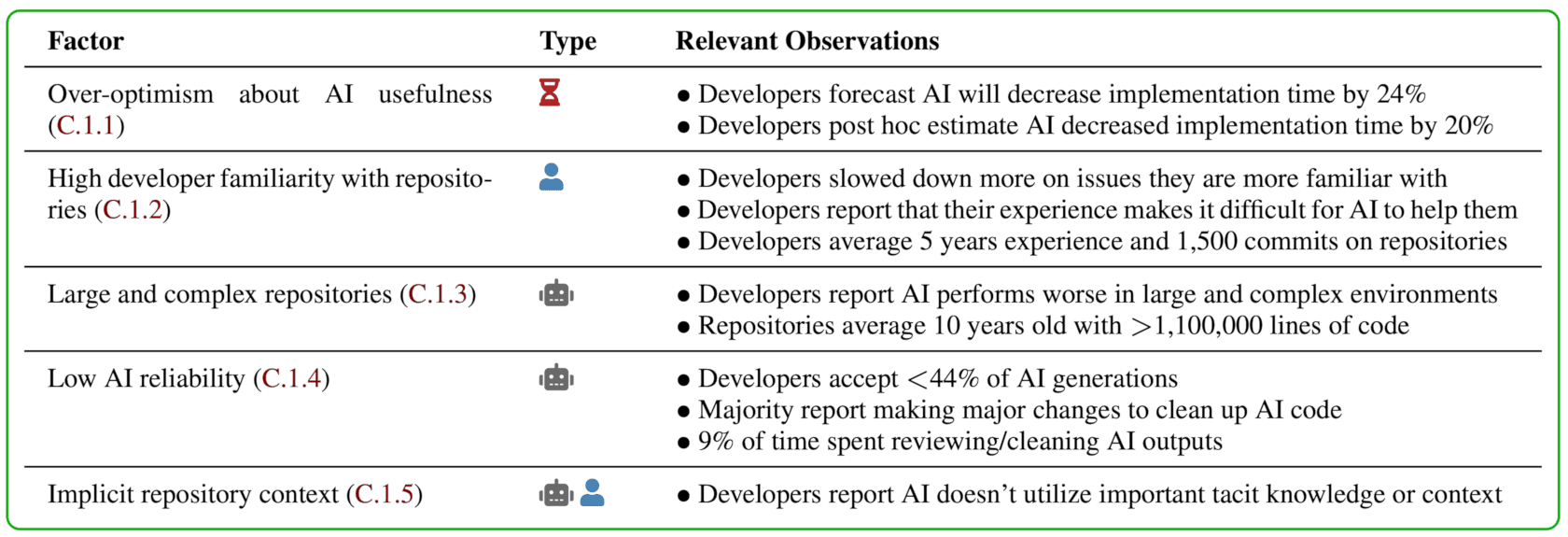
Descartamos muchos artefactos experimentales: los desarrolladores utilizaron modelos de frontera, cumplieron con su asignación de tratamiento, no descartaron problemas de forma diferencial (por ejemplo, descartaron problemas difíciles no permitidos por la IA, lo que redujo la dificultad promedio de los problemas no permitidos por la IA) y presentaron solicitudes de respuesta de calidad similar con y sin IA. La ralentización persiste en diferentes medidas de resultados, metodologías de estimación y muchos otros subconjuntos/análisis de nuestros datos. Consulte el artículo para obtener más detalles y análisis.
Discusión
Entonces, ¿cómo conciliamos nuestros resultados con las impresionantes puntuaciones de referencia de IA y los informes anecdóticos sobre su utilidad y la adopción generalizada de herramientas de IA? En conjunto, la evidencia de estas fuentes ofrece respuestas parcialmente contradictorias sobre la capacidad de los agentes de IA para realizar tareas de forma útil o acelerar el trabajo de los humanos. La siguiente tabla desglosa estas fuentes de evidencia y resume el estado de nuestra evidencia obtenida de ellas. Cabe destacar que esta tabla no pretende ser exhaustiva; pretendemos señalar brevemente algunas diferencias importantes.
| Nuestro RCT | Puntos de referencia como SWE-Bench Verified, RE-Bench | Anécdotas y adopción generalizada de la IA | |
|---|---|---|---|
| Tipo de tarea | Relaciones públicas de bases de código abierto grandes y de alta calidad | SWE-Bench verificado: PR de código abierto con pruebas escritas por el autor, RE-Bench: problemas de investigación de IA creados manualmente con métricas de puntuación algorítmicas | Diverso |
| Definición de éxito de la tarea | El usuario humano está satisfecho de que el código pasará la revisión, incluidos los requisitos de estilo, pruebas y documentación. | Puntuación algorítmica (por ejemplo, casos de prueba automatizados) | El usuario humano encuentra útil el código (potencialmente como un prototipo descartable o un código de investigación de un solo uso) |
| Tipo de IA | Chat, modo de agente de cursor, autocompletar | Por lo general, son agentes totalmente autónomos, que pueden muestrear millones de tokens, utilizan estructuras de agentes complicadas, etc. | Varios modelos y herramientas |
| Observaciones | Los modelos ralentizan a los humanos en tareas de codificación realistas de entre 20 minutos y 4 horas | Los modelos a menudo tienen éxito en tareas de referencia que son muy difíciles para los humanos. | Muchas personas (aunque ciertamente no todas) informan que la IA les resulta muy útil para tareas de software importantes que les toman más de una hora, en una amplia gama de aplicaciones. |
Conciliar estas diferentes fuentes de evidencia es difícil, pero importante, y en parte depende de la pregunta que intentemos responder. Hasta cierto punto, las diferentes fuentes representan subpreguntas legítimas sobre las capacidades del modelo; por ejemplo, nos interesa comprender las capacidades del modelo tanto dada la obtención máxima (p. ej., muestreando millones de tokens o decenas o cientos de intentos/trayectorias para cada problema) como dado el uso estándar o común. Sin embargo, algunas propiedades pueden invalidar los resultados para la mayoría de las preguntas importantes sobre la utilidad en el mundo real; por ejemplo, los autoinformes pueden ser inexactos y excesivamente optimistas.
A continuación se presentan algunas de las categorías generales de hipótesis sobre cómo podrían conciliarse estas observaciones que nos parecen más plausibles (este pretende ser un modelo mental muy simplificado):
| Resumen de los resultados observados La IA ralentiza a los desarrolladores de código abierto experimentados en nuestro RCT, pero demuestra puntuaciones de referencia impresionantes y, anecdóticamente, es ampliamente útil. | 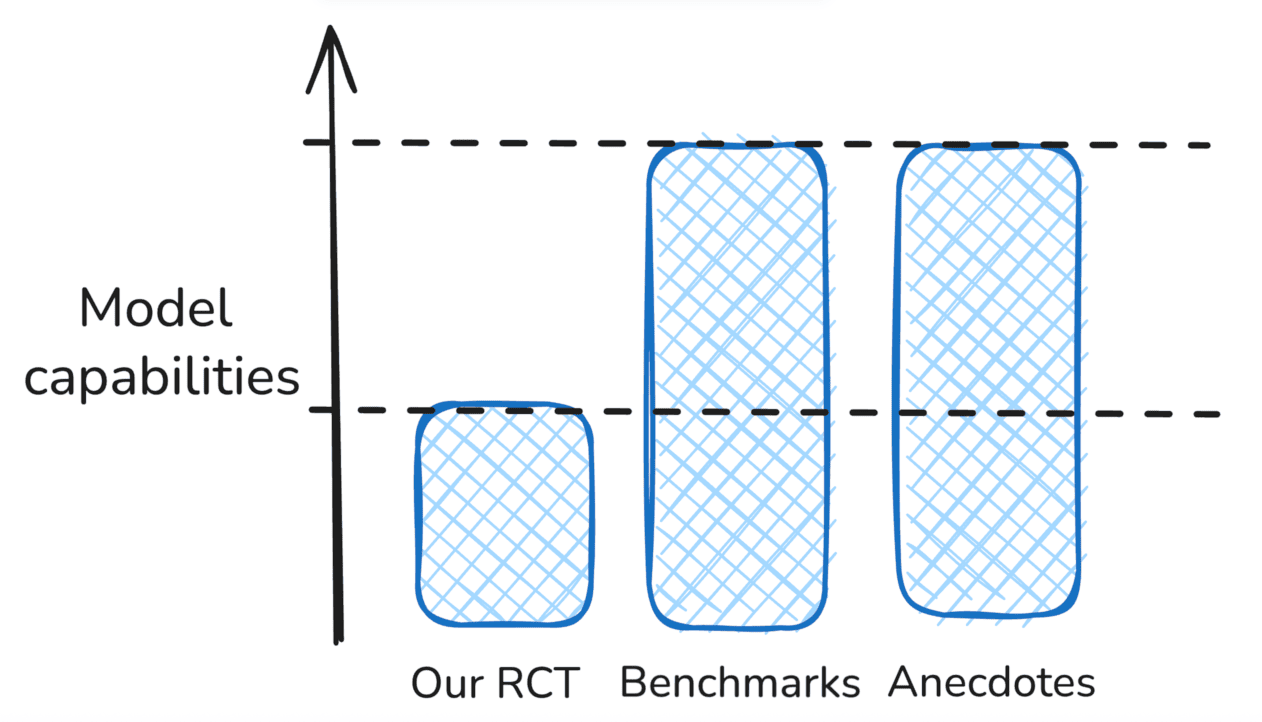 |
| Hipótesis 1: Nuestro ECA subestima las capacidades Los resultados de referencia y las anécdotas son básicamente correctos y hay algún problema metodológico desconocido o propiedades de nuestro entorno que son diferentes de otros entornos importantes. | 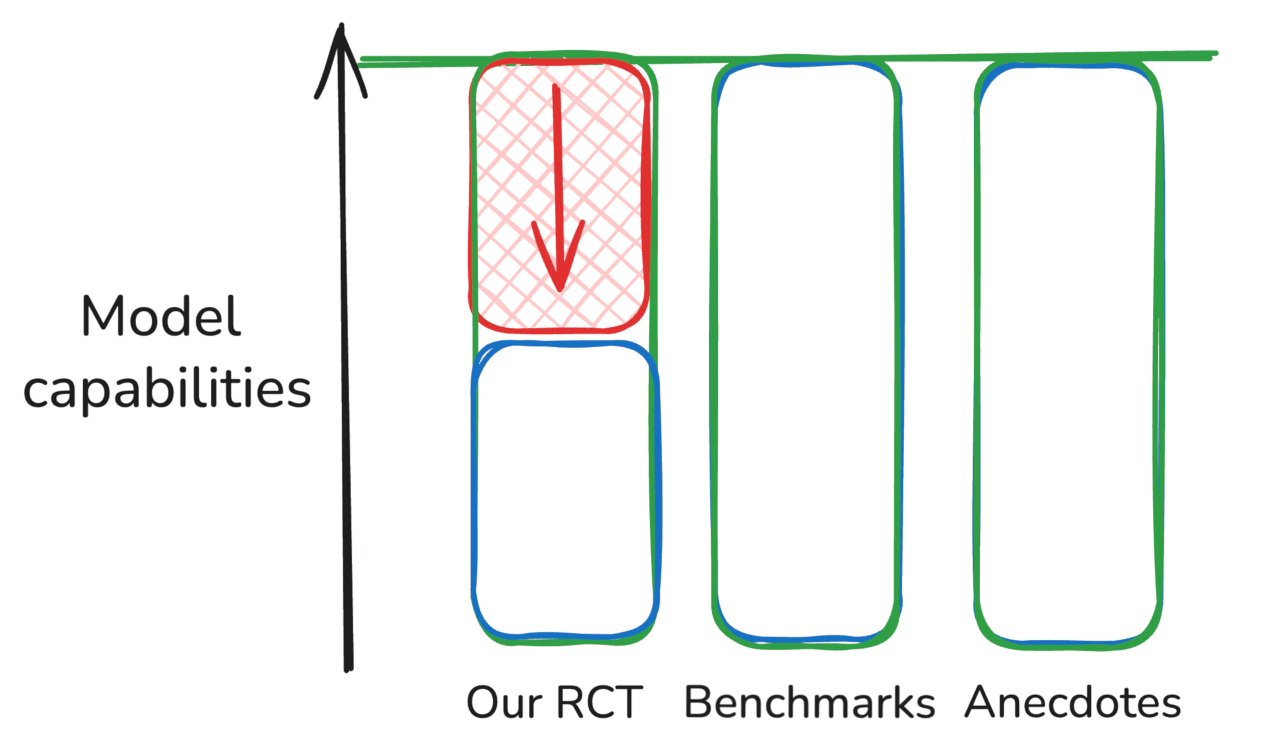 |
| Hipótesis 2: Los puntos de referencia y las anécdotas sobreestiman las capacidades Nuestros resultados de RCT son básicamente correctos, y los puntajes de referencia y los informes anecdóticos son sobreestimaciones de la capacidad del modelo (posiblemente cada uno por diferentes razones) | 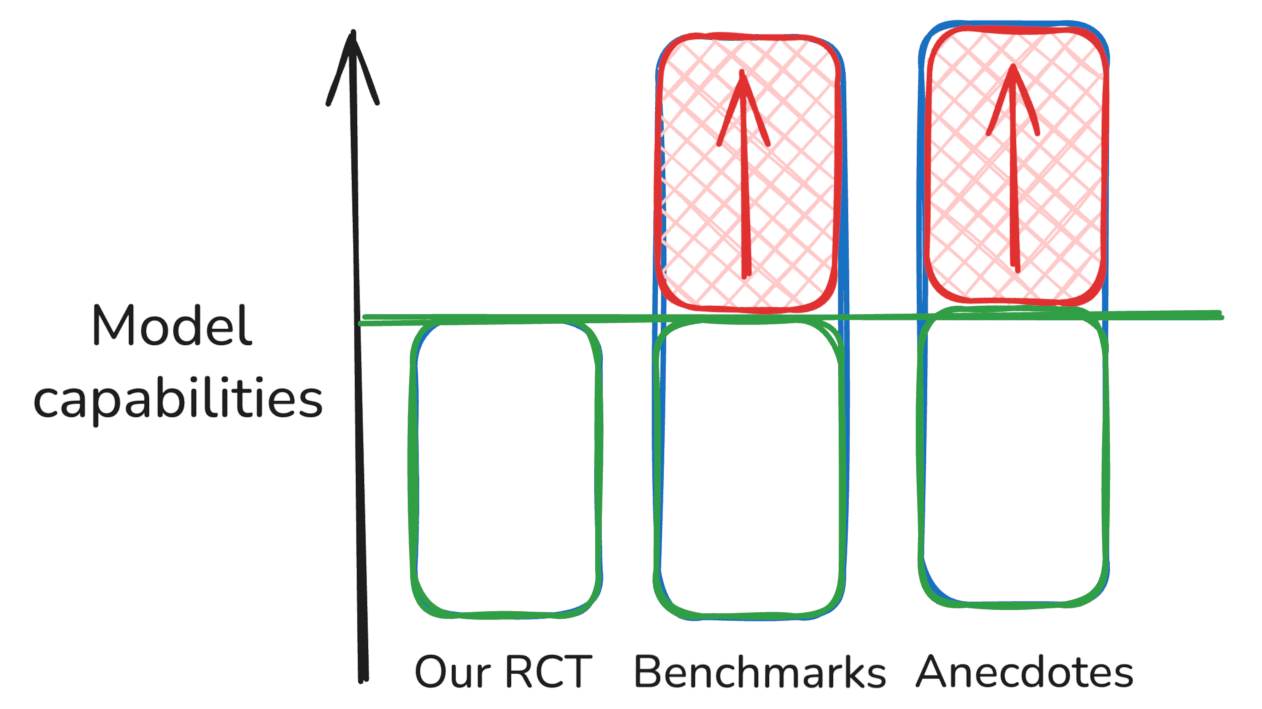 |
| Hipótesis 3: Evidencia complementaria para diferentes entornos Las tres metodologías son básicamente correctas, pero miden subconjuntos de la distribución de tareas “reales” que son más o menos desafiantes para los modelos. | 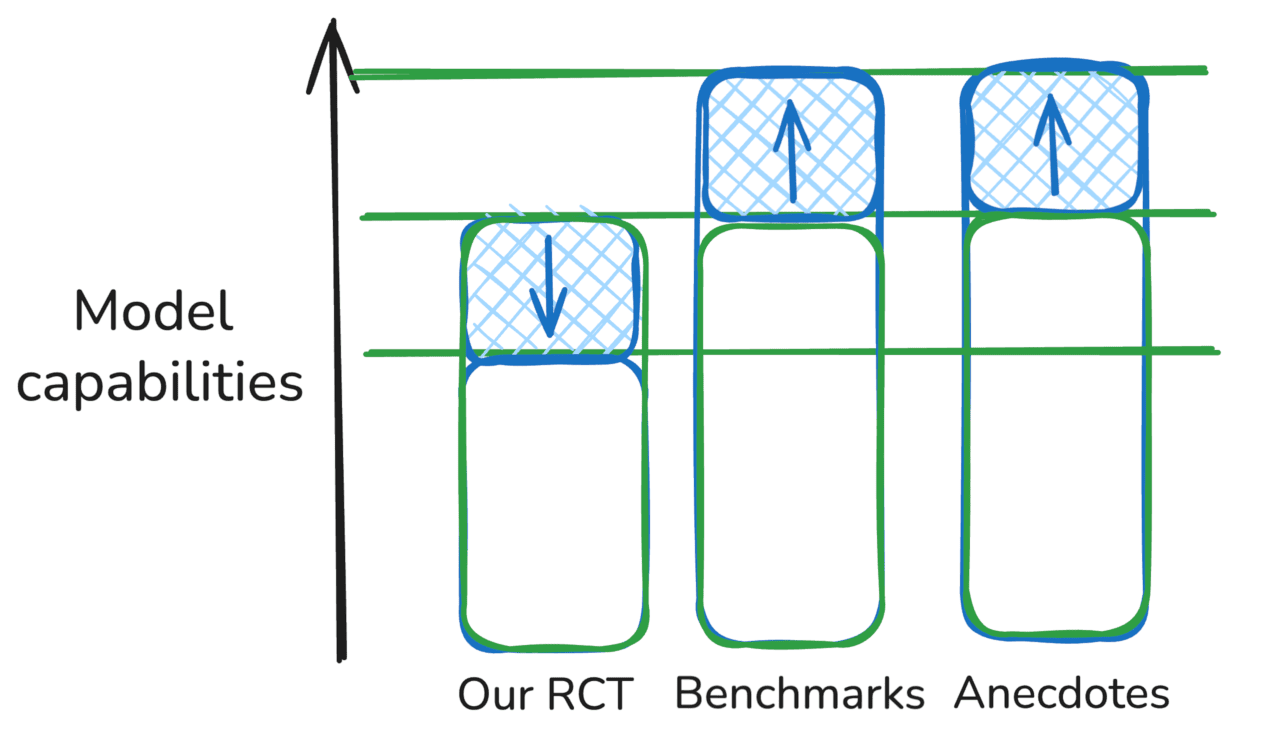 |
En estos bocetos, las diferencias rojas entre una fuente de evidencia y el nivel de capacidad “real” de un modelo representan errores de medición o sesgos que hacen que la evidencia sea engañosa, mientras que las diferencias azules (es decir, en el escenario “Mixto”) representan diferencias válidas en lo que representan diferentes fuentes de evidencia, por ejemplo, si simplemente apuntan a diferentes subconjuntos de la distribución de tareas.
Usando este marco, podemos considerar la evidencia a favor y en contra de varias maneras de conciliar estas diferentes fuentes de evidencia. Por ejemplo, nuestros resultados de RCT son menos relevantes en entornos donde se pueden muestrear cientos o miles de trayectorias de modelos, que nuestros desarrolladores normalmente no prueban. También puede darse el caso de que haya fuertes efectos de aprendizaje para herramientas de IA como Cursor que solo aparecen después de varios cientos de horas de uso; nuestros desarrolladores normalmente solo usan Cursor durante unas pocas docenas de horas antes y durante el estudio. Nuestros resultados también sugieren que las capacidades de IA pueden ser comparativamente menores en entornos con estándares de calidad muy altos, o con muchos requisitos implícitos (por ejemplo, relacionados con la documentación, la cobertura de pruebas o el linting/formateo) que requieren un tiempo considerable para que los humanos aprendan.
Por otro lado, los puntos de referencia pueden sobreestimar las capacidades del modelo al medir únicamente el rendimiento en tareas bien definidas y con puntuación algorítmica. Además, ahora contamos con pruebas sólidas de que los informes o estimaciones anecdóticos de aceleración pueden ser muy inexactos.
Ningún método de medición es perfecto: las tareas que se esperan de los sistemas de IA son diversas, complejas y difíciles de estudiar rigurosamente. Existen importantes ventajas y desventajas entre los métodos, y seguirá siendo importante desarrollar y utilizar diversas metodologías de evaluación para obtener una visión más completa del estado actual de la IA y de su futuro.
Avanzando
Nos entusiasma realizar versiones similares de este estudio en el futuro para rastrear las tendencias de aceleración (o desaceleración) de la IA, especialmente porque esta metodología de evaluación puede ser más difícil de manipular que los benchmarks. Si los sistemas de IA logran acelerar sustancialmente a los desarrolladores en nuestro entorno, esto podría indicar una rápida aceleración del progreso general de la I+D en IA, lo que a su vez puede generar riesgos de proliferación, fallos en las salvaguardias y la supervisión, o una excesiva centralización del poder. Esta metodología proporciona evidencia complementaria a los benchmarks, centrada en escenarios de implementación realistas, lo que nos ayuda a comprender las capacidades y el impacto de la IA de forma más completa en comparación con basarnos únicamente en benchmarks y datos anecdóticos.
Fuente: https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/