

Su concurso de un millón de dólares para el premio ARC está diseñado para ponernos en el camino correcto.
- La inteligencia artificial general (AGI) podría cambiar el mundo, pero nadie parece saber qué tan cerca estamos de construirla.
- Las IA generativas actuales obtienen buenos resultados en los exámenes comparativos, pero dichos exámenes pueden resolverse mediante la memorización y no necesariamente indican una inteligencia general.
- Para acelerar el progreso en IA, François Chollet lanzó el Premio ARC, una competencia para ver qué IA pueden obtener la puntuación más alta en un conjunto de tareas de abstracción y razonamiento.
por Kristin Houser
Estamos en el año 2030 y la inteligencia artificial general (IAG) por fin ha llegado. En los próximos años, utilizaremos esta poderosa tecnología para curar enfermedades, acelerar los descubrimientos, reducir la pobreza y mucho más. En cierto modo, nuestro camino hacia la IA general se remonta a un concurso de un millón de dólares que desafió el status quo de la IA en 2024.
Inteligencia artificial general
La inteligencia artificial general (IAG), un software con inteligencia de nivel humano, podría cambiar el mundo, pero nadie parece saber qué tan cerca estamos de lograrla. Las predicciones de los expertos van desde 2029 a 2300 o nunca . Algunos insisten en que la IA general ya está aquí .
Para descubrir por qué es tan difícil predecir la llegada de la IA general, echemos un vistazo a la historia de la IA, las formas en que medimos actualmente la inteligencia de las máquinas y la competencia de un millón de dólares que podría ayudarnos a llegar a este software que cambiará el mundo.
Donde hemos estado

A dónde vamos (quizás)
Entonces, ¿cómo sabremos cuándo llegará la IAG?
Las pruebas de referencia son una forma útil de seguir el progreso de la IA, y elegirlas para IA diseñadas para una sola tarea es generalmente bastante fácil: si está entrenando una IA para identificar problemas cardíacos a partir de ecocardiogramas, por ejemplo, su punto de referencia podría ser su precisión en comparación con los médicos.
Pero, por definición, se supone que la inteligencia artificial general posee la misma inteligencia que los humanos. ¿Cómo se puede comparar eso?
Durante décadas, muchos consideraron que el test de Turing era un sólido parámetro de referencia para la inteligencia artificial general (aunque no fuera exactamente como Alan Turing pretendía que se utilizara). Si una IA podía convencer a un evaluador humano de que era humana, estaba exhibiendo funcionalmente una inteligencia de nivel humano, según se pensaba.
Pero cuando un chatbot diseñado a imagen de un adolescente “pasó” el test de Turing en 2014 actuando como un adolescente (desviando preguntas, haciendo chistes y, básicamente, actuando como un tonto), nada en él parecía particularmente inteligente, y mucho menos lo suficientemente inteligente como para cambiar el mundo.
Desde entonces, los avances en los grandes modelos de lenguaje (LLM, por sus siglas en inglés) —IA entrenadas en enormes conjuntos de datos de texto para predecir respuestas similares a las humanas— han llevado a chatbots que pueden engañar fácilmente a las personas haciéndoles creer que son humanos, pero esas IA tampoco parecen muy inteligentes, especialmente porque lo que dicen es a menudo falso .
Como la prueba de Turing se consideró rota , ” obsoleta ” y ” mucho más que obsoleta “, los desarrolladores de IA necesitaban nuevos puntos de referencia para la IAG, por lo que comenzaron a hacer que sus modelos tomaran las pruebas más difíciles que tenemos para las personas, como el examen de abogacía y el MCAT, y el MMLU , un punto de referencia creado en 2020 específicamente para evaluar el conocimiento de los modelos de lenguaje en una variedad de temas.
Ahora, los desarrolladores informan periódicamente sobre el rendimiento de sus IA más nuevas en relación con los examinados humanos, los modelos de IA anteriores y sus competidores de IA , y publican sus resultados en artículos con títulos como ” Chispas de inteligencia artificial general “.

Estos puntos de referencia nos dan una forma más objetiva de evaluar y comparar IA que la prueba de Turing, pero a pesar de cómo parecen, tampoco muestran necesariamente un progreso hacia la IAG.
Los LLM se entrenan con enormes cantidades de texto, en su mayoría extraídos de Internet, por lo que es probable que muchas de las mismas preguntas que se usan para evaluar un modelo se hayan incluido en sus datos de entrenamiento, en el mejor de los casos, inclinando la balanza y, en el peor, permitiéndole simplemente regurgitar respuestas en lugar de realizar cualquier tipo de razonamiento humano.
Y como los desarrolladores de IA normalmente no publican detalles sobre sus datos de entrenamiento, aquellos fuera de las empresas (las personas que intentan prepararse para la (tal vez) inminente llegada de la IAG) no saben con certeza si este problema, conocido como ” contaminación de datos “, está afectando los resultados de las pruebas.
“La memorización es útil, pero la inteligencia es otra cosa”.François Chollet
Sin embargo, parece que sí. En las pruebas, los investigadores han descubierto que el rendimiento de un modelo en estos puntos de referencia puede disminuir drásticamente cuando se lo desafía con problemas de prueba ligeramente reformulados o que se crearon completamente después de la fecha límite para sus datos de entrenamiento.
“Casi todos los puntos de referencia actuales de IA se pueden resolver simplemente mediante la memorización”, dijo a Freethink François Chollet, ingeniero de software e investigador de IA. “Se puede simplemente observar qué tipo de preguntas hay en el punto de referencia y luego asegurarse de que esas preguntas, u otras muy similares, estén incluidas en los datos de entrenamiento de su modelo”.
“La memorización es útil, pero la inteligencia es otra cosa”, añadió. “En palabras de Jean Piaget, la inteligencia es lo que utilizamos cuando no sabemos qué hacer. Es la manera en que aprendemos ante nuevas circunstancias, cómo nos adaptamos e improvisamos, cómo adquirimos nuevas habilidades”.
“Está diseñado para resistir la memorización y, hasta ahora, ha resistido la prueba del tiempo”.François Chollet
En 2019, Chollet publicó un artículo en el que describe un punto de referencia engañosamente simple para evaluar las IA en cuanto a este tipo de inteligencia: el Corpus de Abstracción y Razonamiento (ARC).
“Se trata de una prueba de eficiencia en la adquisición de habilidades, en la que cada tarea tiene como objetivo ser novedosa para el examinado”, afirmó Chollet. “Está diseñada para resistir la memorización y, hasta ahora, ha resistido la prueba del tiempo”.
ARC es similar a una prueba de coeficiente intelectual para humanos inventada en 1938, llamada Matrices progresivas de Raven . Cada pregunta presenta pares de cuadrículas, cuyo tamaño varía de 1×1 a 30×30. Cada par tiene una cuadrícula de entrada y una cuadrícula de salida, con celdas en las cuadrículas rellenas con hasta 10 colores diferentes.
El trabajo de la IA es predecir cómo debería verse el resultado para una entrada determinada, basándose en un patrón establecido por uno o dos ejemplos.
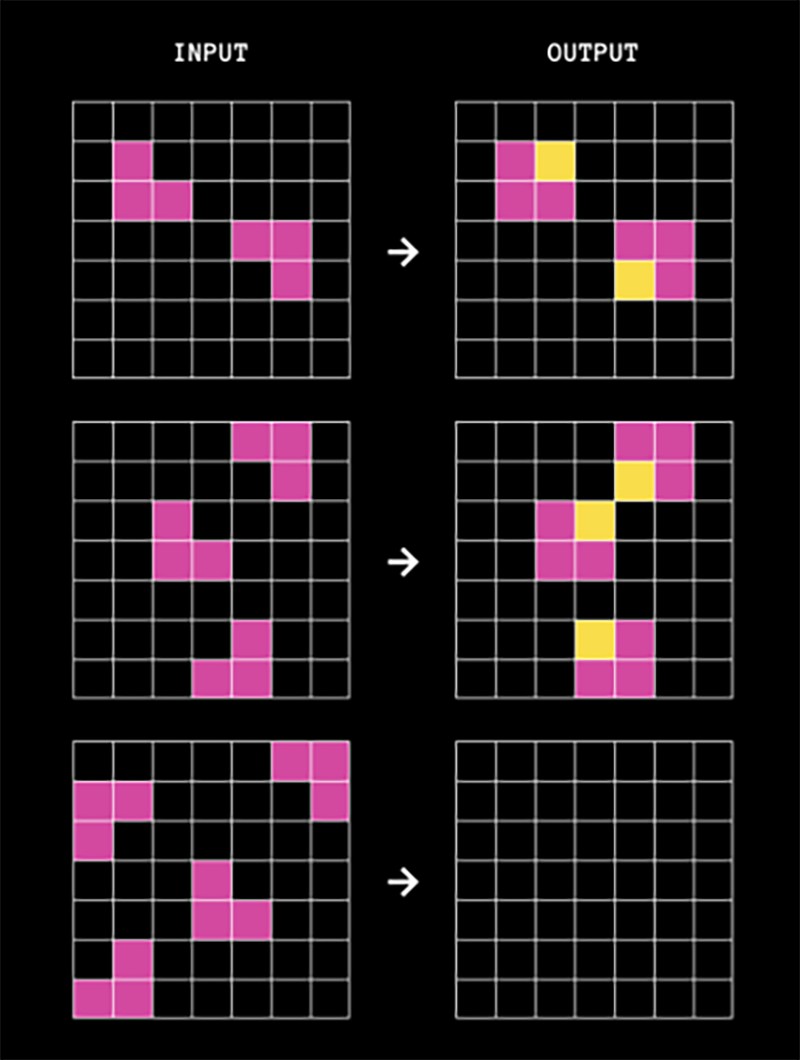
Desde que publicó su artículo, Chollet ha organizado varias competiciones ARC en las que han participado cientos de desarrolladores de IA de más de 65 países. Al principio, sus mejores IA podían resolver el 20 % de las tareas ARC. Para junio de 2024, esa cifra había aumentado al 34 %, cifra que todavía está muy por debajo del 84 % que pueden resolver la mayoría de los humanos.
Para acelerar el progreso en el razonamiento de IA, Chollet se asoció en junio con Mike Knoop , cofundador de la empresa de automatización de flujo de trabajo Zapier, para lanzar ARC Prize , una competencia para ver qué IA pueden obtener la puntuación más alta en un conjunto de tareas ARC, con más de un millón de dólares (y mucho prestigio) en juego para los mejores sistemas.
Los conjuntos de capacitación y evaluación públicos para la competencia, cada uno de los cuales consta de 400 tareas ARC, están disponibles para los desarrolladores en GitHub . Los participantes deben enviar su código antes del 10 de noviembre de 2024 para poder competir.
Luego, las IA serán probadas en el conjunto de 100 tareas de evaluación privada de ARC Prize fuera de línea : este enfoque garantiza que las preguntas de la prueba no se filtren y que las IA no tengan la oportunidad de verlas antes de la evaluación.
Los ganadores se anunciarán el 3 de diciembre de 2024 y las cinco IA con mayor puntuación recibirán entre 5000 y 25 000 dólares cada una (al momento de escribir este artículo, un equipo logró el 43 % ). Para ganar el gran premio de 500 000 dólares, la IA de un participante debe resolver el 85 % de las tareas. Si nadie gana, ese premio en metálico se transferirá a una competencia de 2025.
Para poder optar a cualquier premio, los desarrolladores deben estar dispuestos a abrir el código fuente.
“El propósito del Premio ARC es redirigir más atención a la investigación de IA hacia arquitecturas que puedan conducir a la inteligencia artificial general (AGI) y garantizar que los avances notables no permanezcan como un secreto comercial en un gran laboratorio corporativo de IA”, según el sitio web de la competencia .
“Básicamente, OpenAI hizo retroceder el progreso de la IAG entre cinco y diez años”.François Chollet
Es probable que esta nueva dirección se aleje de los LLM y otras IA generativas similares. Estas últimas acapararon casi la mitad de la financiación de la IA en 2023, pero, según Chollet, no solo es poco probable que conduzcan a la IAG, sino que están frenando activamente el avance hacia ella.
“Básicamente, OpenAI hizo retroceder el progreso de la inteligencia artificial general entre cinco y diez años”, dijo al podcast Dwarkesh . “Provocaron el cierre total de las publicaciones de investigación de vanguardia, y ahora los LLM han absorbido el oxígeno de la sala: todo el mundo está haciendo LLM”.
No está solo en su escepticismo respecto de que los LLM nos estén acercando a la IAG.
Yann LeCun, científico jefe de IA de Meta, dijo a Next Web que “en el camino hacia la inteligencia a nivel humano, un LLM es básicamente una rampa de salida, una distracción, un callejón sin salida”, y el propio CEO de OpenAI, Sam Altman, ha dicho que no cree que ampliar los LLM conduzca a la IAG.
En cuanto a qué tipo de IA es más probable que conduzca a la IAG, es demasiado pronto para decirlo, pero Chollet ha compartido detalles sobre los enfoques que han tenido mejores resultados en ARC hasta ahora, incluida la inferencia activa, la síntesis de programas DSL y la búsqueda de programas discretos. También cree que podría valer la pena explorar los modelos de aprendizaje profundo y alienta a los participantes a probar enfoques novedosos.
En última instancia, si él y otros tienen razón en que los LLM son un callejón sin salida en el camino hacia la IAG, una nueva prueba que realmente pueda identificar “chispas” de inteligencia general en la IA podría ser enormemente valiosa, ayudando a la industria a cambiar el enfoque hacia la investigación de los tipos de modelos que conducirán a la IAG lo antes posible, y todos los beneficios que cambiarían el mundo que podrían venir con ella.