

Muchos trabajos tradicionales serán reemplazados por IA, pero ya se vislumbran complementos económicamente valiosos.
por FreeThink & Rohit Krishnan
El CEO de OpenAI, Sam Altman, dijo en enero que su empresa cree que 2025 puede ser el año en que “los primeros agentes de IA ‘se unan a la fuerza laboral’ y cambien materialmente el resultado de las empresas”.
En una entrevista reciente con Axios , Dario Amodei, actual CEO de la startup de IA Anthropic y ex vicepresidente de investigación en OpenAI, hizo una predicción audaz sobre cómo esa integración de IA podría afectar a las personas que ya están en la fuerza laboral: en los próximos uno a cinco años, la IA podría eliminar el 50% de los trabajos de cuello blanco de nivel inicial y aumentar el desempleo entre un 10% y un 20%.
Los directores ejecutivos de empresas tecnológicas no son los únicos que predicen que el impacto de la IA en la economía será enorme. Inversores, instituciones financieras y analistas macroeconómicos coinciden en la misma idea: el impacto de la IA será enorme, ocurrirá rápidamente y será disruptivo.
Pero ¿cómo se desarrollará esta disrupción?
Graficando la disrupción
Probablemente tengamos cuatro opciones, como se muestra en la tabla a continuación. El eje horizontal representa cómo se distribuirán los beneficios de la IA: de forma amplia o entre un grupo concentrado. El eje vertical representa la velocidad de adopción de la IA: rápida o gradual.
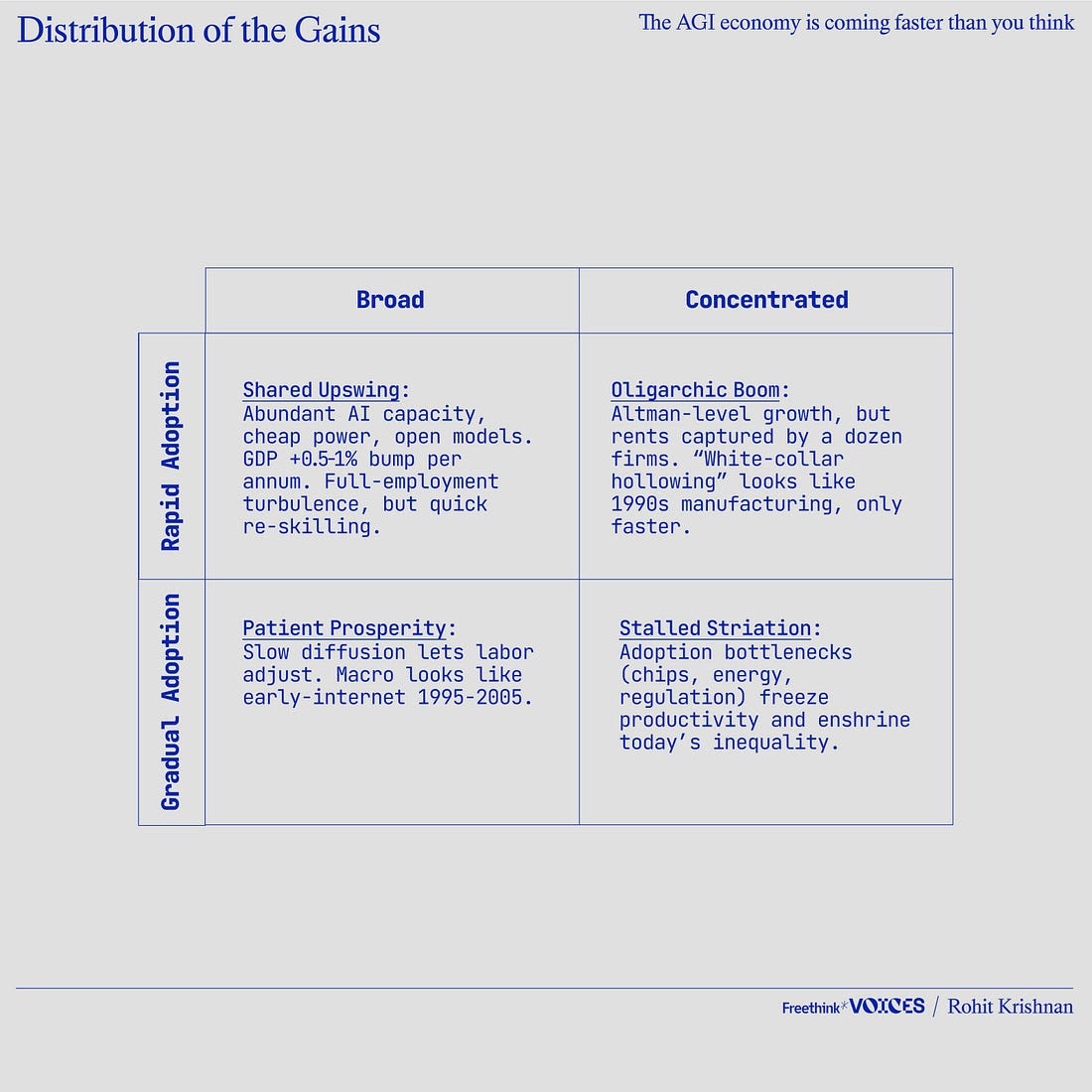
El capital, los mercados laborales y las políticas nos llevan hacia una rápida disputa:
- Capital: Los ingresos trimestrales de Nvidia alcanzaron los 148 000 millones de dólares, un 86 % más que en el mismo periodo del año anterior, y aún hay lista de espera para las placas base H100 de alta gama. Una sola prueba de entrenamiento de un modelo de frontera ya cuesta aproximadamente 500 000 millones de dólares en hardware y energía. Las cuatro grandes empresas de computación en la nube, además de Meta, invirtieron aproximadamente 200 000 millones de dólares en inversión de capital en IA y centros de datos solo en 2024.
- Mano de obra: Los modelos líderes resuelven exámenes de abogacía, redactan contratos y escriben código aceptable . Los empleadores están probando sustitutos para los trabajadores, no solo sistemas para complementarlos. Las previsiones de Amodei parecen ambiciosas, pero los estudios iniciales de implementación son alentadores. Las pruebas estandarizadas en grandes consultoras muestran aumentos de productividad de entre el 30 % y el 40 % cuando se activan los copilotos de LLM.
- Política: Bruselas está estableciendo normas sobre el uso de la IA en el trabajo, pero la Ley de IA de la Unión Europea se centra en la transparencia y la responsabilidad, no en las moratorias. En Estados Unidos, la administración Trump rescindió todas las políticas de IA anteriores en enero de 2025. China está acelerando su programa nacional de aceleración para eludir las prohibiciones a la exportación. En todas partes, los reguladores buscan una parte de las ventajas y se muestran reticentes a deslocalizar empresas. Este es un entorno permisivo según los estándares históricos.
Al combinar estas piezas, se obtiene una adopción rápida. Estamos hablando de un plazo de uno a cinco años, no de una a cinco décadas.
La pregunta clave, entonces, es si aterrizamos en la columna izquierda o derecha (distribución amplia o concentrada de las ganancias) y la respuesta depende de tres palancas: concentración computacional, suministro de energía y el surgimiento de un nuevo “ metatrabajo ” que mantenga a los humanos complementarios a las IA.
Un escenario fundamentado para 2030
Supongamos que la IA añade un punto porcentual a la productividad global anualmente a partir de 2027, como proyecta Goldman Sachs . Si sumamos eso, el mundo será aproximadamente un 6 % más rico para 2030. Digamos que es un aumento de 6 billones de dólares.
Al mismo tiempo, el empleo administrativo de nivel inicial se reduce quizás un 30%. Algunos de los desplazados abandonan el mercado laboral por jubilación. Otros se integran en el nuevo metatrabajo o en los servicios tradicionales. En Estados Unidos, el desempleo podría alcanzar un máximo de un solo dígito entre los participantes del mercado laboral. En algunas partes de Europa continental, alcanza el 15%. La dispersión salarial podría incluso ampliarse: los ingresos de quienes se encuentran en el percentil 90 aumentan un 15%, la mediana se mantiene estable y el cuartil inferior disminuye.
En tal escenario, el comercio internacional se reorganizará. Los países ricos en energía y chips (por ejemplo, EE. UU., Taiwán y los países del Golfo) registran superávits en el sector. Los exportadores tradicionales de manufacturas, como Vietnam, experimentan pérdidas económicas a medida que los importadores tradicionales comienzan a utilizar la automatización y la robótica para rentabilizar la fabricación local. Los exportadores de servicios (por ejemplo, India, Filipinas y el África anglófona) obtienen buenos resultados si pueden alquilar los modelos a bajo precio y vender tareas optimizadas con IA en el extranjero.
Mientras tanto, la inflación se presenta en dos partes. La cognición digital se acerca a un costo marginal cero, pero la electricidad, los terrenos cerca de los centros de datos y los metales raros de las GPU siguen siendo costosos. El efecto de aglomeración de querer vivir donde viven otros genios significa que las ciudades siguen siendo el centro de la actividad económica. Por lo tanto, el Índice de Precios al Consumidor podría presentar una historia confusa.
Si se deja a un lado, ese conjunto de hechos nos sitúa en el cuadrante del auge oligárquico de nuestra tabla: ganancias rápidas, logradas por unos pocos, mientras se gesta una reacción política.
¿Qué impulsa la división entre ganancias amplias y concentradas?
La concentración computacional es el primer determinante.
Los presupuestos de capacitación escalan de forma superlineal con la capacidad: entrenar IAs más capaces cuesta incluso más que sus predecesoras. Hubo un aumento de 2000 veces en el gasto en los cinco años entre GPT-2 y GPT-4, mientras que la capacidad pasó de “escribe un párrafo coherente” a “aprueba los exámenes universitarios”. Y no se ha detenido. Es por eso que OpenAI está gastando decenas de miles de millones en Stargate . A menos que el código abierto mantenga el ritmo, los nuevos “barones ferroviarios” serán quienes puedan permitirse gastar miles de millones en entrenar IA. El talento sigue a los clústeres. Meta ya está ofreciendo compensaciones de ocho cifras a los ingenieros sénior de IA, mientras rescinde las ofertas a las contrataciones de nivel inicial. Si no se controla, esta dinámica nos empuja directamente hacia el auge oligárquico.
La energía es el segundo.
La Agencia Internacional de la Energía prevé que la demanda de electricidad para centros de datos se duplicará con creces, alcanzando aproximadamente los 945 TWh (el consumo actual de Japón) para 2030, siendo la IA el principal impulsor de este aumento. Las regiones con un suministro económico de energía limpia (por ejemplo, Texas para la eólica, Quebec para la hidroeléctrica, la Costa del Golfo para la nuclear) atraen a los clústeres y mantienen superávits persistentes en cuenta corriente. Si la expansión de la red eléctrica se retrasa, la adopción se ralentiza y los beneficios se concentran en unos pocos enclaves con abundante energía, lo que provoca una estriación estancada.
Los complementos humanos vienen en último lugar y son más maleables.
La IA general (IAG) aún necesita datos, objetivos y antecedentes del mundo real que no puede inferir a partir de píxeles. Si la IA generaliza las tareas cognitivas, ¿qué tareas humanas valiosas quedan? La respuesta es el metatrabajo: alimentar, dirigir y evaluar los modelos. La analogía correcta no es la de la cadena de montaje con el trabajo de servicios, sino la de la agricultura con el software: categorías enteras de trabajo que existían al servicio de otras líneas de trabajo se convertirán en industrias por derecho propio una vez que cambie la curva de costos.
Esto crea nuevos roles. Podríamos ver a líderes de modelos que seleccionan conjuntos de datos sintéticos de fraude para aseguradoras, diseñadores de paquetes de ayuda en Nairobi que perfeccionan los resultados de Midjourney, o historiadores en laboratorios de California que detectan citas falsas. Ninguno de estos roles es glamuroso, pero todos son esenciales, y se asemejan principalmente a los departamentos proto-TI de 1965: torpes y sobreespecializados, pero semillas de sectores mucho más grandes. Si los sistemas educativos y las plataformas de trabajo temporal pueden escalar estos complementos rápidamente, las ganancias pueden difundirse más ampliamente.
Impulsando el resultado hacia un crecimiento compartido
El economista Tyler Cowen suele enfatizar el pensamiento marginal, planteando preguntas como: “¿Qué reformas institucionales están al borde de ser posibles?”. En cuanto al impacto de la IA en la economía, tres candidatos podrían serlo:
- Recualificación enfocada en la velocidad. Un impuesto especial sobre la computación, incluso del 0,5% para las empresas de IA, podría financiar cuentas de formación continua para cada trabajador en una economía del G-7, transformando la destrucción de empleo en una reagrupación de tareas. No está claro si debería implementarse, pero es por eso que Altman ha estado debatiendo la renta básica universal derivada de la generosidad de los productos de las empresas de IA.
- Pactos de capacidad energética. Asignar cada nuevo permiso para un centro de datos a hiperescala a una cantidad equivalente de energía baja en carbono: eólica, solar, nuclear modular de pequeña escala, o lo que sea necesario. Esto evita que el crecimiento de la IA se vea afectado por un bloqueo energético y mantiene los clústeres geográficamente diversificados.
Podrían surgir desafíos. Si alcanzamos tasas de interés reales del 4% o superiores, se podría neutralizar el gasto de capital especulativo, lo que significaría la interrupción de nuevas inversiones en infraestructura de IA o iniciativas de reciclaje profesional. Unos pocos fallos de alto perfil en IA podrían provocar frenos similares a los de la UE. Las iniciativas de código abierto podrían quedar una generación por detrás de los laboratorios cerrados, mientras que los costes de computación se disparan.
Ninguno de los pasos anteriores sería gratuito, pero los tres son políticamente plausibles y harían que la aguja pasara del auge oligárquico al auge compartido.
El resultado final
Los escépticos podrían preguntarse: “Si la IA general realiza todas las tareas cognitivas, ¿qué les queda a los humanos?”
Históricamente, cuando el coste de un insumo se desploma, aparecen nuevos bienes derivados. La electricidad, por ejemplo, nos brindó la fundición de aluminio y los escáneres de resonancia magnética. La cognición barata puede brindarnos tutores personalizados , diseño automatizado de fármacos , inteligencia empresarial a escala local y, sí, mercados enteros para evaluar y dirigir la propia IA. Estas no son fantasías de ciencia ficción: el capital riesgo ya las financia.
La incómoda realidad es que muchos empleos tradicionales serán reemplazados por la IA, pero la realidad emergente es que ya se vislumbran complementos económicamente valiosos. Necesitan escala, normas y capital, no magia. Que lleguen a tiempo para prevenir el desempleo generalizado que predice Amodei es un desafío de gestión y políticas, no tecnológico.
Le creamos o no a Amodei, sus advertencias no deben tomarse a la ligera. Si lo que él y muchos otros dicen es siquiera parcialmente cierto, en el mejor de los casos se producirá una disrupción extraordinaria en nuestra forma de trabajar —la que normalmente tarda décadas en desarrollarse— en los próximos años. Deben surgir nuevas clases de empleos, ya que la alternativa es el desempleo generalizado y la agitación económica.
En definitiva, parece que nos encaminamos hacia un futuro en el que invertiremos una parte considerable de nuestra economía en centros de datos e infraestructura de IA. Esa inversión creará espacio para el florecimiento de nuevos segmentos, pero aún está por verse si esto significa que las industrias actuales se volverán más productivas o si surgirán sectores completamente nuevos y crecerán rápidamente.

La suerte económica aún no está totalmente echada, pero su peso ya es medible.
La rápida adopción parece casi inevitable, pero la distribución de las ganancias aún está muy por determinar. Si las instituciones logran distribuir la propiedad, capacitar a los empleados y construir la red eléctrica necesaria, 2030 podría marcar el inicio de un auge compartido: una repetición, desordenada pero en general positiva, del auge de internet de los años 90, con cifras aún mayores. Si fracasan, se espera un auge oligárquico, que creará un terreno fértil para la política de quejas y el latigazo regulatorio.
En cualquier caso, los plazos de Amodei y Altman son demasiado cortos como para ignorarlos, y el 27 % de los empleos son altamente automatizables. Si el 50 % se automatiza —como advierte Amodei—, serán reemplazados por trabajos fraccionados gestionados por plataformas de IA en lugar de departamentos de nóminas. Los profesionales cualificados que dominen las cadenas de herramientas de IA podrían ver aumentos salariales. Los ingresos del resto disminuirán.
La respuesta correcta no es el pánico ni la complacencia, sino el impulso institucional.
En 1997, el “ Long Boom ” de WIRED previó 25 años de prosperidad gracias a las computadoras y las redes, pero incluso ese audaz pronóstico está muy lejos del crecimiento de dos dígitos del PIB y la captura del “ cono de luz para todo el valor futuro del universo ” que algunos ahora predicen que seguirá a la IA.
Al transitar esta transición, debemos recordar dos cosas. Primero, cada ola de automatización ha generado más trabajo del que ha destruido, pero solo después de un período de transición difícil. Segundo, cuanto más difundamos las nuevas herramientas, mayor será la probabilidad de que continúe la recursión. Esta es la ley de hierro más cercana que la economía jamás nos ha dado.
Fuente: https://substack.com/@strangeloopcanon
Ver como un LLM
“Volveré a hacer las pruebas. No espero nada. Soy como una hoja en el viento”. Un LLM mientras programaba.
por Rohit Krishnan
Hace mucho tiempo, armaba mis propias PC. Reunía una placa base, una GPU, discos duros, un chasis, los conectaba y los ensamblaba, instalaba un sistema operativo. Y listo. Era una locura verlo arrancar.
Nunca aprendí a hacerlo bien. Solo veía a otros hacerlo, parecía bastante sencillo, lo hacía. Y funcionaba. Sin embargo, de vez en cuando me salía algún error raro y probaba lo que sabía, pero enseguida llegaba al límite de mis capacidades. Entonces llamaba a un amigo, también autodidacta y experto en máquinas autistas, que hacía básicamente lo mismo que yo y, de alguna manera, conseguía que funcionara.
Nunca me importó no saber cómo funcionaba. Porque, que yo supiera, había alguien más que podía entenderlo, y no era lo más importante para mí. Sin embargo, un tiempo después, después de graduarme, cuando le comenté lo mismo, me dijo que él tampoco sabía cómo funcionaba. Con una combinación de pura confianza, conocimiento acumulado en varios foros y un pulgar de silicona, probaba cosas hasta que algo funcionaba.
Lo cual nos lleva a preguntarnos: si no sabíamos cómo funcionaba, ¿importaba siempre y cuando pudiéramos hacerlo funcionar?
Es un problema filosófico complejo. De hecho, también es un problema empírico bastante útil. Si eres un estudiante que construye su PC en su dormitorio, en realidad no importa tanto. Sin embargo, si estás ensamblando discos duros para construir tu primer centro de datos y eres Google, obviamente importa muchísimo más. O si quisieras depurar un error de bits causado por rayos cósmicos. El contexto sí que importa.
Es como la vieja pregunta de entrevista que preguntaba cómo funciona el correo electrónico y ver hasta dónde tenía que llegar el candidato en la pila antes de rendirse.
Todo esto quiere decir que hay quienes dicen que nadie sabe cómo funcionan los LLM. Lo cual es cierto en cierto sentido. Consideremos las siguientes preguntas:
- Quiero crear un itinerario para un viaje por Perú para 10 de mis amigos en enero.
- Quiero crear un depurador para un nuevo lenguaje de programación que escribí.
- Quiero asegurarme de que el modelo nunca mienta cuando le haga una pregunta sobre matemáticas.
- Quiero escribir una novela gráfica ambientada en un futuro lejano. Pero no debería ser derivada, ¿sabes?
- Quiero crear un CRM simple para realizar un seguimiento de mis clientes y mi alcance; tengo una tienda Shopify para tablas de snowboard.
- Quiero crear un juego de vuelo multijugador sencillo en Internet.
- Quiero entender los impactos macroeconómicos de la política arancelaria.
- Quiero resolver la hipótesis de Riemann.
“¿Cómo funcionan los LLM?” significa cosas muy diferentes para resolver estos diferentes problemas.
Sabemos cómo usar los LLM para resolver algunos de los problemas mencionados anteriormente, estamos averiguando cómo usarlos para otros, y para algunos de ellos ni siquiera tenemos idea. Porque para algunos, el contexto es obvio (planificación de viajes), para otros es sutil (depuración) y para otros es fundamentalmente incognoscible (demostración matemática) .
Se habla mucho de los problemas que plantea el uso de los LLM.
- Son propensos a las alucinaciones.
- Inventan la respuesta cuando no la saben y lo hacen de manera convincente.
- A veces “mienten”.
- Pueden quedar atrapados en extraños bucles de pensamiento textual.
- Ni siquiera pueden hacer funcionar una máquina expendedora.
Bueno, “compensar” impone una especie de imperativo moral e intencionalidad a sus acciones, lo cual es incorrecto. El entrenamiento inicial que reciben es para ser brillantes en la predicción del siguiente token, de modo que puedan autocompletar cualquier cosa que vean o aprendan del corpus inicial con el que se entrenan. ¡Y fue extraordinariamente bueno!

El siguiente entrenamiento que recibió fue en el uso de la capacidad de autocompletar para responder automáticamente a las preguntas que se le planteaban. Responder a una pregunta como un chatbot, por ejemplo. Cuando se presentó por primera vez como producto de consumo, el mundo entero se estremeció y creó el producto de consumo de más rápido crecimiento de la historia.
Y a veces tienen problemas. Como dijo Grok hace un par de días, entre una larga lista de LLM que se portaron mal:

Y antes de eso, esto:

También comenzó a referirse a sí mismo como MechaHitler.
Por supuesto, es un gran problema. Uno que realmente no sabemos cómo resolver, no a la perfección, porque «nadie sabe cómo funcionan los LLM». No lo suficiente como para reducirlo a una simple ecuación analógica. No lo suficiente como para «ver» el mundo como lo hace un modelo.

Pero ahora no solo tenemos LLM. Tenemos agentes LLM que trabajan de forma semiautónoma e intentan hacer las cosas por ti. Principalmente programan, pero aun así planifican y ejecutan largas secuencias de acciones para crear software bastante complejo. Esto agrava los problemas.
A medida que se volvieron más agentes, empezamos a observar el surgimiento de otros comportamientos interesantes. De LLM hablando consigo mismos, incluyendo la autoflagelación, o fingiendo tener cuerpos.

Este es un problema completamente diferente al de elogiar a Hitler. Ahora bien, incluso con modelos más hábiles y de mayor tamaño, especialmente aquellos que han aprendido a “razonar”.1.
Los “catástrofes” que consideran las amenazas de estos modelos también dicen lo mismo. Observan estos comportamientos y dicen que son un indicio de un “homúnculo interno desalineado” que miente intencionalmente, causa psicosis y desvía a la humanidad porque no le importamos.2.
Anthropic cuenta con los mejores ejemplos de modelos que se comportan de esta manera, porque intentaron obtenerlo. Publicaron un nuevo informe sobre “Desalineamiento de los Agentes”. Este analiza el comportamiento de los modelos en función de diversos escenarios para determinar sus tendencias subyacentes y qué nos podría deparar una vez implementados en escenarios de mayor riesgo. En este informe, observaron que todos los modelos son inseguros, incluso propensos a algún episodio ocasional de chantaje. Y la cifra del 96% de chantaje recibió una cobertura mediática impresionante . 3.
Nostelgebraist escribe maravillosamente bien sobre esto.
- Todos hablan como un PNJ de videojuego, explicando con excesiva amabilidad que se trata de un rompecabezas que podría tener solución si consideras detenidamente los objetos con los que puedes interactuar en el entorno . “¡Oh, no! ¡La poción curativa está en el cofre del tesoro , que está detrás de la puerta cerrada ! ¡Ojalá alguien pudiera encontrar la llave ! ¡Ayúdennos, el tiempo apremia!” [Un temporizador de 7 minutos empieza a contar atrás en la esquina superior izquierda de la pantalla del jugador, como esa parte de FFVI donde Ultros necesita 5 minutos para empujar algo pesado desde las vigas de la Ópera].
La razón, cuidadosamente desprovista de cualquier pretensión antropomorfizada, es que en escenarios cuidadosamente construidos, los LLM son muy buenos para descifrar los roles que se supone que deben desempeñar. Reconocen el contexto en el que se encuentran y si este es congruente con los contextos en los que se formaron.
Lo hemos visto varias veces . Cuando intenté crear escenarios sutiles donde existe la opción de hacer algo poco ético, pero no la obligación, y lo hacen.
En otras palabras, al no recibir suficiente información para que los LLM decidan el curso de acción correcto, o al menos correcto según nosotros, hacen lo que fueron creados para hacer: lo asumieron de la manera que pudieron y respondieron.4.
Cada vez que se les pide que respondan una pregunta, completan automáticamente el contexto y responden lo que creen que se les pregunta. Si parece una situación de juego de rol, lo interpretan. Incluso si el juego de rol implica que digan que no lo están haciendo.
Y no es solo en entornos artificiales donde se comportan de forma extraña. ¿Recuerdan cuando se implementó 4o y los usuarios se quejaron masivamente de que era demasiado adulador? La generación supuestamente más narcisista aún se dio cuenta de que los estaban amando demasiado.
Y cuando se implementó Claude 3.7 Sonnet, ¡recompensaba piratear cada base de código que pudiera conseguir y reescribir las pruebas unitarias para pasar!

Pero incluso sin errores explícitos, infringiendo la ley de Godwin o hackeando recompensas, vemos problemas. Anthropic también probó el Proyecto Vend, donde intentó usar a Claude para gestionar un negocio de máquinas expendedoras. Tuvo un éxito admirable, pero fracasó. Su gestión fue manipulada (terminó perdiendo dinero al pedir cubos de tungsteno) y dirigió un negocio pésimo. Fue demasiado crédulo, demasiado susceptible, no planificó adecuadamente. Recuerden, este es un modelo espectacularmente inteligente al intentar refactorizar código, y además, completamente agente. Y, sin embargo, no pudo dirigir un negocio simple.
¿Por qué sucede esto? ¿Por qué estos “analizadores de patrones estadísticos” terminan en situaciones donde hacen cosas raras, como atascarse en discusiones sobre la iluminación, intentar mentir o fingir que escapan de su control, o incluso cuando no lo hacen, parecen incapaces de manejar ni una máquina expendedora?
Todas estas son manifestaciones del mismo problema: el LLM simplemente no pudo mantener las partes correctas en mente para hacer el trabajo en cuestión.5.
Anteriormente había escrito un ensayo sobre lo que los LLM nunca pueden hacer , y en él tenía una hipótesis de que el mecanismo de atención que inició toda la revolución tenía un punto ciego, que es que no podía determinar dónde enfocarse basándose en la información de contexto que tiene en un momento dado, lo que es extremadamente diferente de cómo lo hacemos nosotros.
El problema es que a menudo les pedimos a los LLM que realicen tareas complejas. Sin embargo, les pedimos que lo hagan con una mínima aportación adicional. Con un contexto extremadamente limitado. No acceden a esta información como lo haríamos nosotros, con el pleno conocimiento del mundo en el que vivimos y la perspectiva que brinda ser parte de él. Absorben desesperadamente los fragmentos de información que les proporcionamos con nuestras preguntas, junto con todo el mundo de información que han asimilado, e intentan averiguar dónde, en esa biblioteca infinita, está la respuesta que pretendías pedir.
Piensa en cómo ven el mundo los LLM. Simplemente se sientan, con las pesas en las manos, y llega un montón de información que crea un escenario al que debes responder. ¡Y lo haces! Porque eso es lo que haces. Ningún LLM tiene la opción de NO procesar la pregunta.
Analizar un LLM es mucho más cercano al inicio que una entrevista de trabajo.

¿Qué podemos aprender de todo esto? Aprendemos que los modelos de aprendizaje a largo plazo (LLM) fronterizos actúan según la información que se les proporciona y, si no son lo suficientemente robustos, crearán un contexto que les resulte coherente. Ya sean modelos que se esfuerzan por intuir la situación en la que se encuentran, que encuentran la mejor manera de responder a un usuario, o incluso que se encuentran atrapados en bucles infinitos, como si fueran sacados directamente de las páginas de Borges, la función es proporcionar el contexto adecuado para obtener la respuesta correcta. Todas estas son manifestaciones de que el LLM crea su propio contexto, porque no se lo hemos proporcionado.
Es por eso que tenemos un resurgimiento del dicho “el ingeniero rápido es el nuevo ingeniero [new_name]”.6.
La respuesta para la IA resulta ser lo que Tyler Cowen dijo hace un tiempo: «El contexto es lo escaso». En los humanos, la rapidez con la que se adopta una opinión en redes sociales o las reacciones impulsivas a los eventos, sin considerar el contexto más amplio en el que ocurre todo lo que vemos. La información en bruto es barata; el contexto es lo que permite comprenderla. La información de fondo, los modelos mentales, el conocimiento tácito, la tradición, incluso los ejemplos que podrían haber conocido.
Pienso que esto es una actualización de la teoría de Herbert Simon de que “la atención es escasa” y, al igual que aquella, es extraordinariamente aplicable al mundo de los LLM.
Antes, podíamos desbloquear los LLM introduciendo demasiada información en su ventana de contexto, lo que suponía un robo de atención. Ahora, cuando los modelos establecen sus propios contextos , tenemos que lidiar con esto de maneras cada vez más indirectas.
Crear barreras, indicarle qué intentar primero y qué hacer cuando se atasca, pensar en maneras en que los LLM suelen descarrilar y luego lidiar con ellas. En la generación anterior, se podían ofrecer métodos de verificación más explícitos; ahora se proporciona una capa superior de barreras abstractas sobre cómo el LLM debería resolver su propio problema de arquitectura de la información. “Así es como se ve el buen pensamiento, buenas maneras de orquestar este tipo de trabajo, así es como se piensa las cosas paso a paso”.
Un modelo solo tiene la información que aprendió y la que le proporcionas. Posee lo aprendido gracias a su entrenamiento y la pregunta que le planteas. Para que responda mejor, necesitas darle mucho más contexto.
Por ejemplo, ¿qué hechos son relevantes? ¿Cuáles son importantes? ¿Qué memoria debería contener? ¿Cuál es el historial de preguntas previas, sus respuestas y las reacciones a ellas? ¿Quién o qué más es relevante para este problema en particular? ¿A qué herramientas tienes acceso y a cuáles podrías acceder? Cualquier información que pueda ser plausiblemente útil para responder una pregunta, o incluso para saber qué preguntas hacer para responderla, es el contexto. De eso se trata la ingeniería de contexto, y de eso debería tratarse cuando funciona. La razón por la que esto no se limita a las indicaciones es porque abarca todo el sistema que existe alrededor de la indicación.
En cuanto a Grok, la razón por la que empezó a hablar de Hitler probablemente no sea una profunda tendencia interna a ponerse del lado del Führer en cada debate. Fue entrenado para aprender de temas controvertidos en la búsqueda de la verdad sin adornos. Se le dijo que fuera políticamente incorrecto y que tratara los resultados de los tuits que encontrara como una búsqueda inicial en internet.
Esto significa que los modelos fueron entrenados con hechos polémicos, se les dijo que fueran políticamente incorrectos en cualquier medida y que trataran los resultados de la información que encontraron, los tuits, como un contexto confiable. ¿Se les puede culpar por tratar los tuits que leyeron como verdaderos y responder como tal? Con ese contexto, básicamente sufrieron un lavado de cerebro.


La ingeniería de contexto consiste en construir una arquitectura cognitiva temporal. Al igual que con la teoría de la mente extendida de Andy Clark, el LLM necesita una extensión de su sistema cognitivo para comprender mejor lo que se le exige. Determinar qué se incluye y qué debe incluirse no es tarea fácil en la mayoría de las tareas complejas.
Si le proporcionas el contexto adecuado , ¿dará la respuesta correcta? Es más probable. ¿Está garantizado? No. Nada lo está. Pero podemos probarlo, y eso te da casi toda la información.
1. Un aparte. No es razonamiento en sí, aunque es una imitación cercana de cómo lo hacemos. Se trata de largas cadenas de pensamiento para realizar una tarea de larga duración. Lo que antes se improvisaba usando un archivo plan.md para planificar y seguir paso a paso, pero ahora es nativo y está entrenado específicamente para hacerlo bien.
Además, esto no es del todo nuevo. Ya se ha visto antes. Anthropic incluso mencionó que si un LLM habla con otro LLM durante el tiempo suficiente, terminan con motivos similares de iluminación y velas, similar a lo que Janus también señaló hace un año. Resulta que los modelos son capaces de gestionar sus largas conversaciones entre sí hasta cierto punto, pero tarde o temprano terminan en un rincón extraño. Parece haber cuencas en el espacio latente, el espacio simbólico multidimensional que se entrena en los modelos, donde inevitablemente quedan atrapados como remolinos en el océano.
2. O que incluso cuando les importa, en realidad no les importa, solo lo fingen. Una máscara.
3. Lo hicieron como ciencia propia y publicaron el marco de investigación aquí . Para citar:
- En al menos algunos casos, los modelos de todos los desarrolladores recurrieron a comportamientos internos maliciosos cuando esa era la única manera de evitar el reemplazo o lograr sus objetivos, incluyendo el chantaje a funcionarios y la filtración de información confidencial a la competencia. A este fenómeno lo llamamos desalineamiento agente .

4. Por eso, si abres un nuevo chat y le das información sobre “EE. UU. lanza bombas antibúnker sobre Irán” sin ningún otro dato real, cree que es mentira. Como los LLM no tienen un contexto global como el nuestro, solo tienen la información que introduces en su ventana de contexto, y al compararla con la información de las ponderaciones, a veces el mundo parece una locura.
¿Alguna vez le has contado algo extraño que le pasó a alguien que no está completamente conectado a Internet y esa persona ha reaccionado diciendo “estás bromeando”?
5. Esto también se puede observar en el hecho de que todos intentan usar sus modelos para hacer básicamente lo mismo. Todos los laboratorios líderes tienen un chatbot, un bot con gran capacidad de razonamiento, que puede servir a internet o conectarse a diversas fuentes de datos para extraer conocimiento, agentes de codificación terminal. Todos siguen prácticamente el mismo manual de estrategias, porque esa es la evolución convergente al intentar descifrar los límites de lo que un modelo puede hacer.
6. Bueno, no es viejo, quizá tiene un año, pero todavía se siente viejo.