

La IA está asumiendo continuamente nuevos desafíos, desde la detección de deepfakes (que, dicho sea de paso, también se hacen con IA) hasta ganar en el póquer y dar un impulso a los experimentos de biología sintética. Estas impresionantes hazañas son el resultado en parte de los enormes conjuntos de datos en los que están entrenados los sistemas. Ese entrenamiento es costoso y requiere mucho tiempo, y produce IA que realmente solo puede hacer bien una cosa.

Por ejemplo, para entrenar a una IA para diferenciar entre una imagen de un perro y una de un gato, se alimenta a miles, si no millones, de imágenes etiquetadas de perros y gatos. Un niño, por otro lado, puede ver un perro o un gato solo una o dos veces y recordar cuál es cuál. ¿Cómo podemos hacer que las IA aprendan más como lo hacen los niños?
Un equipo de la Universidad de Waterloo en Ontario tiene una respuesta: cambiar la forma en que se entrena a las IA.
Esto es lo que pasa con los conjuntos de datos que se utilizan normalmente para entrenar la IA: además de ser enormes, son muy específicos. Una imagen de un perro solo puede ser una imagen de un perro, ¿verdad? Pero, ¿qué pasa con un perro realmente pequeño con una cola larga? Ese tipo de perro, aunque sigue siendo un perro, se parece más a un gato que, digamos, a un Golden Retriever adulto.
Es este concepto en el que se basa la metodología del equipo de Waterloo. Describieron su trabajo en un artículo publicado en el servidor arXiv de preimpresión (o no revisado por pares) el mes pasado. Enseñar a un sistema de inteligencia artificial a identificar una nueva clase de objetos usando solo un ejemplo es lo que ellos llaman “aprendizaje de una sola vez”. Pero van un paso más allá, enfocándose en “menos de un aprendizaje de un disparo” o aprendizaje LO-shot para abreviar.
El aprendizaje LO-shot consiste en un sistema que aprende a clasificar varias categorías basándose en una cantidad de ejemplos que es menor que la cantidad de categorías. Ese no es el concepto más sencillo de entender, así que volvamos al ejemplo de perros y gatos. Supongamos que quiere enseñarle a una IA a identificar perros, gatos y canguros. ¿Cómo podría hacerse eso sin varios ejemplos claros de cada animal?
La clave, dice el equipo de Waterloo, está en lo que llaman etiquetas blandas. A diferencia de las etiquetas duras, que etiquetan un punto de datos como perteneciente a una clase específica, las etiquetas suaves descubren la relación o el grado de similitud entre ese punto de datos y varias clases. En el caso de una IA entrenada solo en perros y gatos, una tercera clase de objetos, digamos, los canguros, podría describirse como un 60% como un perro y un 40% como un gato (lo sé, los canguros probablemente no son el mejor animal haber incluido como una tercera categoría).
“Las etiquetas blandas se pueden usar para representar conjuntos de entrenamiento usando menos prototipos que clases, logrando grandes aumentos en la eficiencia de la muestra sobre los prototipos regulares (etiqueta dura)”, dice el documento. ¿Traducción? Dígale a una IA que un canguro es una fracción de gato y una fracción de perro, los cuales se ve y conoce bien, y podrá identificar un canguro sin haber visto nunca uno.
Si las etiquetas blandas están lo suficientemente matizadas, teóricamente podría enseñarle a una IA a identificar una gran cantidad de categorías basándose en una cantidad mucho menor de ejemplos de entrenamiento.
Los autores del artículo utilizan un algoritmo de aprendizaje automático simple llamado k vecinos más cercanos (kNN) para explorar esta idea con más profundidad. El algoritmo opera bajo el supuesto de que es más probable que existan cosas similares cerca unas de otras; si vas a un parque para perros, habrá muchos perros, pero no gatos ni canguros. Vaya a los pastizales australianos y habrá canguros pero no gatos ni perros. Y así.
Para entrenar un algoritmo kNN para diferenciar entre categorías, elija características específicas para representar cada categoría (es decir, para los animales, podría usar el peso o el tamaño como característica). Con una característica en el eje xy la otra en el eje y, el algoritmo crea un gráfico donde los puntos de datos que son similares entre sí se agrupan uno cerca del otro. Una línea en el centro divide las categorías, y es bastante sencillo para el algoritmo discernir en qué lado de la línea deben caer los nuevos puntos de datos.
El equipo de Waterloo lo mantuvo simple y usó diagramas de color en un gráfico 2D. Usando los colores y sus ubicaciones en los gráficos, el equipo creó conjuntos de datos sintéticos y etiquetas suaves que los acompañan. A continuación se muestra uno de los gráficos más simplistas, junto con etiquetas suaves en forma de gráficos circulares.
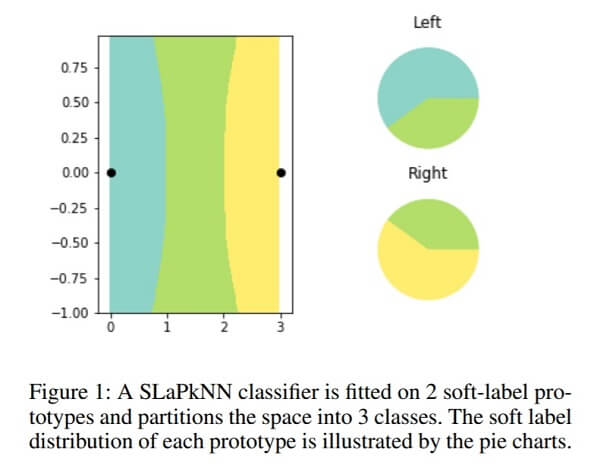
Cuando el equipo hizo que el algoritmo trazara las líneas de los límites de los diferentes colores en función de estas etiquetas suaves, pudo dividir la gráfica en más colores que el número de puntos de datos que se le dio en las etiquetas suaves.
Si bien los resultados son alentadores, el equipo reconoce que son solo el primer paso y aún queda mucho por explorar este concepto. El algoritmo kNN es uno de los modelos menos complejos que existen; ¿Qué podría suceder cuando el aprendizaje LO-shot se aplica a un algoritmo mucho más complejo? Además, para aplicarlo, aún necesita destilar un conjunto de datos más grande en etiquetas suaves.
Una idea en la que el equipo ya está trabajando es hacer que otros algoritmos generen las etiquetas suaves para el algoritmo que se entrenará con LO-shot; diseñar manualmente etiquetas suaves no siempre será tan fácil como dividir algunos gráficos circulares en diferentes colores.
El potencial de LO-shot para reducir la cantidad de datos de entrenamiento necesarios para producir sistemas de inteligencia artificial en funcionamiento es prometedor. Además de reducir el costo y el tiempo necesarios para entrenar nuevos modelos, el método también podría hacer que la IA sea más accesible para las industrias, empresas o personas que no tienen acceso a grandes conjuntos de datos, un paso importante para la democratización de la IA.