

Los “scraper” bots de IA acechan la web, drenando el tráfico, esquivando robots.txt y abrumando los servidores. Así es como los propietarios de sitios están tratando de contraatacar.
por Sharon Fisher
Piénsalo. Millones de pequeños bots, arrastrándose por todos los rincones de Internet, para obtener información para los sistemas de inteligencia artificial (IA).
Es suficiente para mantenerte despierto por la noche.
Los bots raspadores de IA están rompiendo Internet
El problema es que esos bots mantienen a la gente despierta por la noche, en particular, a los informáticos responsables de mantener sus sitios web receptivos con mucho tráfico.
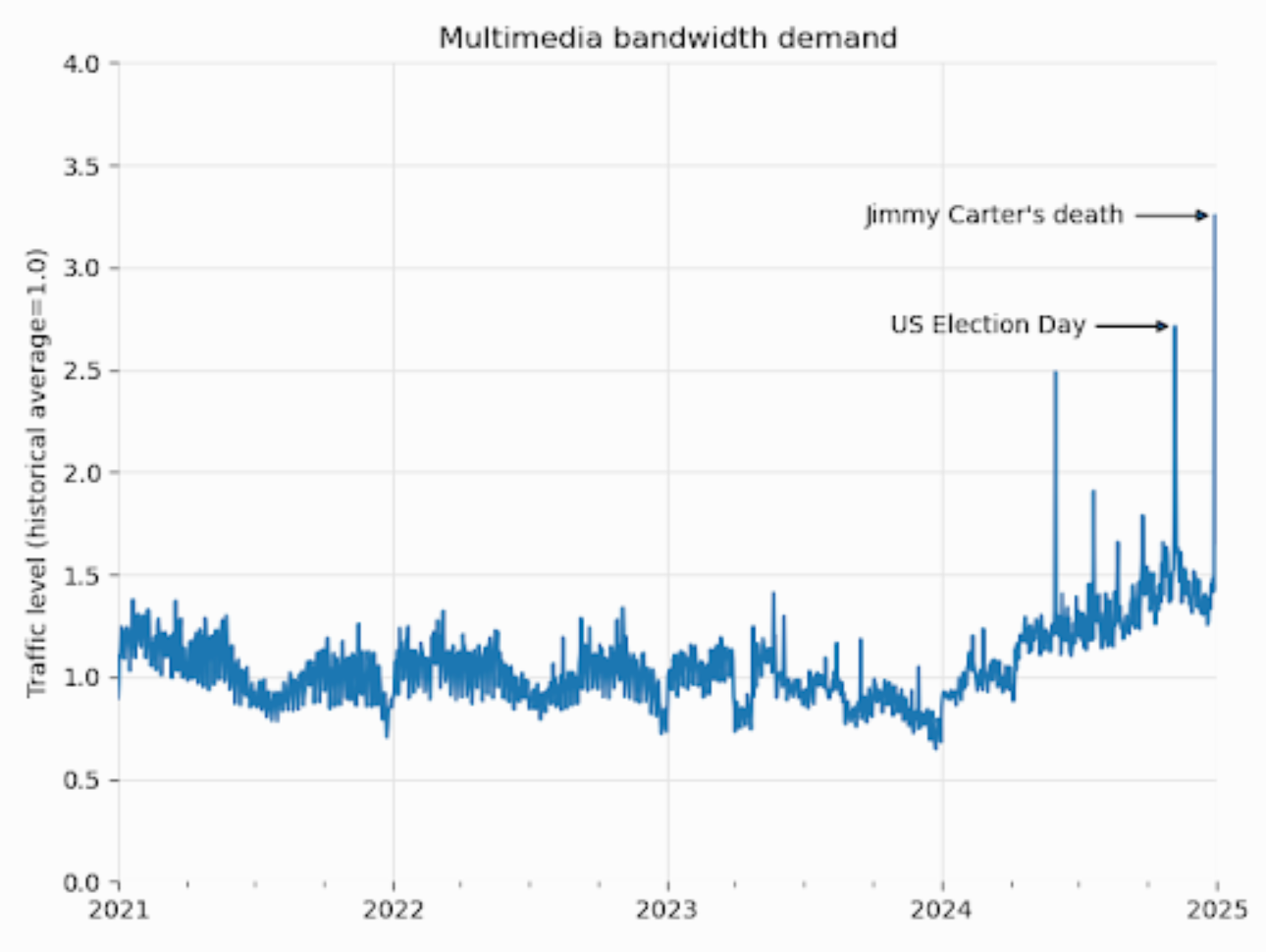
Desde enero de 2024, el ancho de banda utilizado para descargar contenido multimedia creció un 50%, según la Fundación Wikimedia. Pero este aumento no proviene de lectores humanos. Es en gran parte de programas automatizados que escapan de su catálogo de imágenes de Wikimedia Commons para alimentar modelos de IA.
Otros sitios han informado problemas similares.
Cómo se apoderaron los bots
El primer bot raspador de Internet apareció en 1993, solo cinco años después de la creación de la World Wide Web. El bot, llamado World Wide Web Wanderer, fue construido en el MIT por Matthew Grey (actual ingeniero de software de Google) para medir el tamaño de la web.
Más tarde, estos bots se utilizaron para motores de búsqueda, como Google, según David Belson, jefe de información de datos de Cloudflare.
“Las plataformas de búsqueda históricamente rastrearon sitios web con la promesa implícita de que, a medida que los sitios aparecían en los resultados de búsquedas relevantes, enviarían tráfico a esos sitios, lo que a su vez generaría ingresos publicitarios para el editor”.
Incluso entonces, los operadores de sitios web tenían opciones. Si no querían que los bots indexaran sus sitios web, creaban un archivo robots.txt utilizando el Protocolo de exclusión de robots que limitaba el acceso de un bot. Esa salvaguarda no es tan efectiva hoy.
El nuevo problema del raspador de IA
El problema ahora es doble.
Menos humanos, más bots
Primero, más bots crean más tráfico a medida que las empresas de IA los usan para obtener información y crear modelos de IA. La empresa de software TollBit informó una disminución del 9,4% en los visitantes humanos a sus sitios entre el primer y segundo trimestre de 2025. A principios de año, 1 de cada 200 visitantes del sitio era IA. Ahora, es 1 de cada 50, un aumento de 4 veces.
Además del tráfico de bots, los modelos de IA alimentados por los bots no están devolviendo el favor. Anteriormente, los motores de búsqueda enviaban tráfico a sitios web que permitían bots como medio de pago. Eso sucede con menos frecuencia con los modelos de IA. En cambio, estos modelos crean resúmenes generados por IA para que las personas no tengan que ir a la fuente original de información.
Desobedecer bots
En segundo lugar, algunos bots de IA no siguen las reglas.
“No todos los rastreadores respetan robots.txt”, dijo Shayne Longpre, investigador de IA y líder de la Iniciativa de Procedencia de Datos. “No tienen la obligación legal de hacerlo”.
Los administradores web apoyan esto, informando que ven sistemas de IA con información que solo podría provenir de sus sitios, a pesar de tener robots.txt archivos configurados. Es posible que algunos ni siquiera vean indicios de tráfico de bots, y se descubre que bots como Perplexity están ocultando su identidad de rastreo para eludir las preferencias del sitio web.
A principios de este año, por ejemplo, Reddit demandó a Anthropic por extraer sus datos para usarlos en el entrenamiento de LLM, en violación de sus archivos de robots.txt, a pesar de las afirmaciones de Anthropic de que respeta estos bloqueadores de bots. En este caso, que aún está en remediación, Reddit argumenta que la compañía de IA violó los términos de servicio de Reddit al raspar datos sin permiso, en lugar de usar un reclamo de derechos de autor. En segundo lugar, Reddit afirma que está protegiendo los planes para vender sus propios datos, como con su acuerdo de licencia de 60 millones de dólares con Google en 2024.
¿Es posible derrotar a los bots?
Con las tácticas tradicionales fuera de la mesa, los administradores de sitios web están probando otras medidas.
- Las empresas de software han desarrollado soluciones para bloquear todo el tráfico de bots o elegir categorías específicas de bots para bloquear o permitir.
- Otros proveedores han creado sistemas que monitorean, administran y monetizan el tráfico de IA.
- El Grupo de Trabajo de Ingeniería de Internet está trabajando en una nueva iniciativa para dar a los sitios web más control sobre los bots de IA.
“Estamos en la era Napster del web scraping, y lo que la industria necesita es una solución similar a Spotify”, dijo Toshit Panigrahi, CEO y cofundador de TollBit.
Otros dicen que se necesita más. “Si bien es bueno ver innovación en torno a este problema, estamos más interesados en soluciones que puedan beneficiar a todos los usuarios y operadores de sitios, no solo a los clientes de cualquier proveedor de servicios en particular”, dijo Starchy Grant, administrador principal de sistemas de la Electronic Frontier Foundation. “Necesitaríamos ver estándares ampliamente adoptados que afecten ampliamente a todo el ecosistema.
¿Un proveedor para gobernarlos a todos?
Otra solución son los sistemas para reducir la carga de los bots de IA al tener un solo proveedor que extrae datos y luego otorga licencias para esos datos.
“No hemos escuchado de nadie que tome medidas exactamente hacia este tipo de sistema, pero hay algunos precedentes”, dijo Grant. “Wayback Machine de Internet Archive proporciona instantáneas de los contenidos web como un bien público; Cuando raspan una página web una vez, se convierte en un artefacto útil tanto para los operadores del sitio como para los visitantes”.
Otros ejemplos son Shodan, un motor de búsqueda para piratas informáticos y profesionales de la seguridad, y RECAP, que brinda a los usuarios acceso gratuito a documentos de la corte federal una vez que un documento determinado ha sido visto por un primer usuario.
Por qué los bots malos siguen colándose
El problema son los proveedores de IA que buscan formas de eludir estas soluciones, como el desarrollo de bots que actúan más como una persona.
“Hay una carrera armamentista en ambos extremos”, dijo Longpre. Los rastreadores básicos son fáciles de detectar, explicó. Pero también se utilizan bots más sofisticados, aunque más caros.
“Los sitios web también pueden tener una batalla cuesta arriba por delante cuando se trata de lograr que los raspadores que se comportan mal respeten sus señales o paguen en lugar de continuar con un interminable juego del gato y el ratón para intentar disfrazar su tráfico”, dijo Grant.
¿Se está haciendo realidad la ‘teoría de Internet muerta’?
El problema con estas tácticas es que corren el riesgo de dañar lo que hizo de Internet una gran fuente de información en primer lugar: su apertura.
Si cada sitio web se convierte en su propio jardín amurallado, donde solo los miembros tienen acceso a su contenido, Internet vuelve a ser lo que era antes de los días de Alta Vista y Google Search, cuando tenías que tener una idea de dónde podías encontrar información antes de buscarla. La casualidad de tropezar con un sitio web con fotos de gatos en fregaderos o discusiones sobre vestuario en películas de época ya no sucedería.
Además, si todos los sitios de buena reputación con información confiable se bloquean, solo los sitios no confiables estarán disponibles tanto para las personas como para los sistemas de inteligencia artificial, y no podremos confiar en ninguna información que obtengamos de la web o, peor aún, confiaremos en información que no es cierta. Eso se convierte en un problema aún mayor a medida que las empresas de IA se quedan sin datos de entrenamiento de LLM.
De hecho, ha habido una teoría de la conspiración desde 2016 llamada “Teoría de Internet muerta”, que dice que la web consistía completamente en bots que hablaban entre sí, sin contenido humano real. Con el enorme aumento en el tráfico de bots, la Teoría de Internet Muerta podría convertirse en realidad.
“Un mal resultado es que las únicas personas capaces de acceder a los datos son las que son lo suficientemente sofisticadas para los rastreadores realmente poderosos y que han hecho un trato”, dijo Longpre. “La web solo estaría disponible para aquellos que pudieran pagarla. No debería estar disponible solo para el mejor postor”.
Sobre el autor

Sharon Fisher ha escrito para revistas, periódicos y sitios web en toda la industria informática y empresarial durante más de 40 años y también es autora de “Riding the Internet Highway”, así como de capítulos de varios otros libros. Tiene una licenciatura en ciencias de la computación del Instituto Politécnico Rensselaer y una maestría en administración pública de la Universidad Estatal de Boise. Ha sido nómada digital desde 2020 y ha vivido en 18 países hasta ahora.